 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
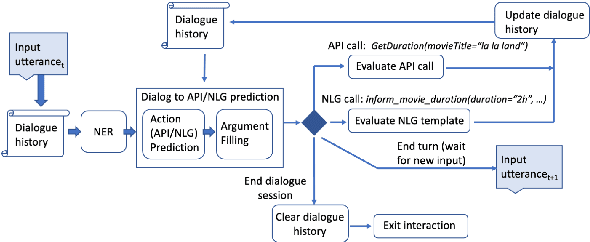

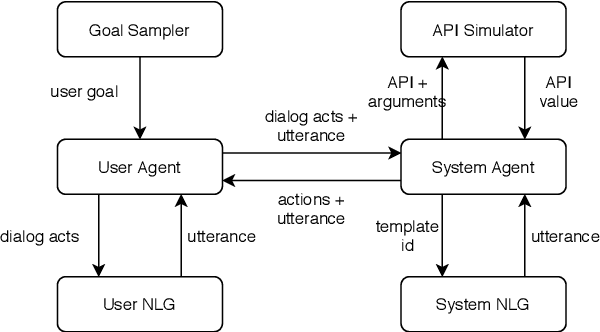
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
Schema-Guided Natural Language Generation
May 11, 2020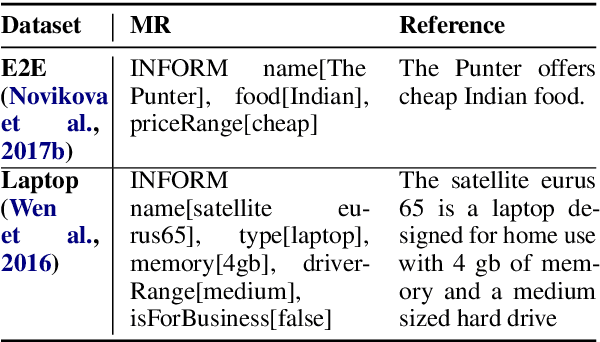


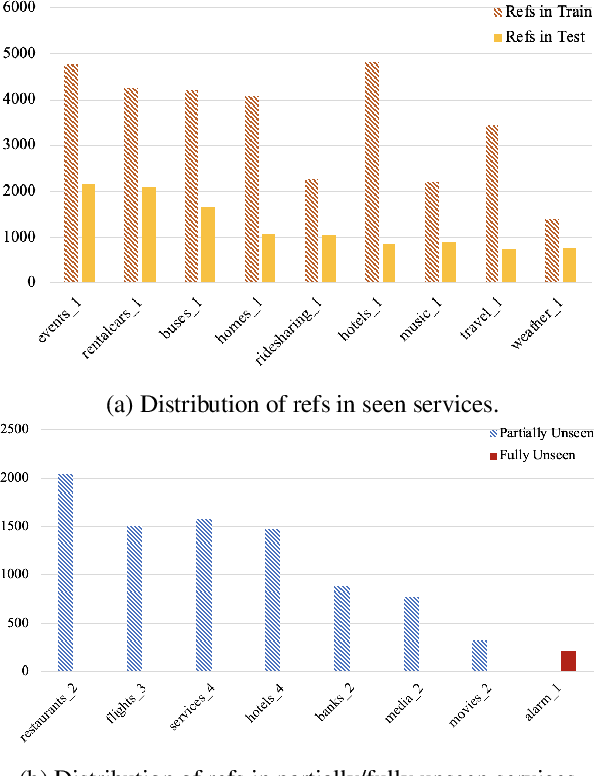
Neural network based approaches to natural language generation (NLG) have gained popularity in recent years. The goal of the task is to generate a natural language string to realize an input meaning representation, hence large datasets of paired utterances and their meaning representations are used for training the network. However, dataset creation for language generation is an arduous task, and popular datasets designed for training these generators mostly consist of simple meaning representations composed of slot and value tokens to be realized. These simple meaning representations do not include any contextual information that may be helpful for training an NLG system to generalize, such as domain information and descriptions of slots and values. In this paper, we present the novel task of Schema-Guided Natural Language Generation, in which we repurpose an existing dataset for another task: dialog state tracking. Dialog state tracking data includes a large and rich schema spanning multiple different attributes, including information about the domain, user intent, and slot descriptions. We train different state-of-the-art models for neural natural language generation on this data and show that inclusion of the rich schema allows our models to produce higher quality outputs both in terms of semantics and diversity. We also conduct experiments comparing model performance on seen versus unseen domains. Finally, we present human evaluation results and analysis demonstrating high ratings for overall output quality.
Just Ask:An Interactive Learning Framework for Vision and Language Navigation
Dec 02, 2019
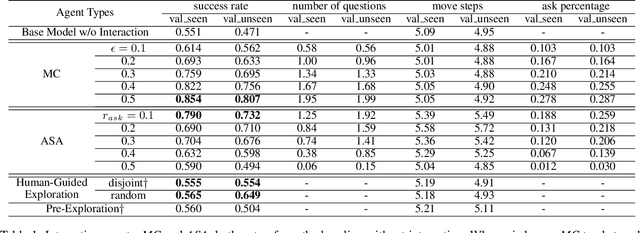
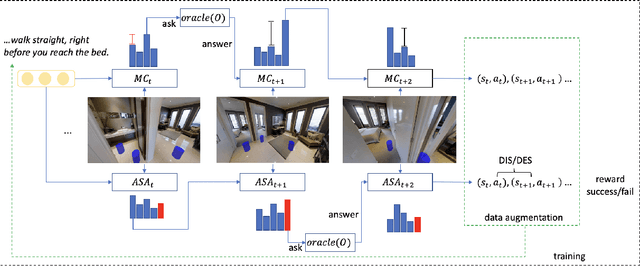

In the vision and language navigation task, the agent may encounter ambiguous situations that are hard to interpret by just relying on visual information and natural language instructions. We propose an interactive learning framework to endow the agent with the ability to ask for users' help in such situations. As part of this framework, we investigate multiple learning approaches for the agent with different levels of complexity. The simplest model-confusion-based method lets the agent ask questions based on its confusion, relying on the predefined confidence threshold of a next action prediction model. To build on this confusion-based method, the agent is expected to demonstrate more sophisticated reasoning such that it discovers the timing and locations to interact with a human. We achieve this goal using reinforcement learning (RL) with a proposed reward shaping term, which enables the agent to ask questions only when necessary. The success rate can be boosted by at least 15% with only one question asked on average during the navigation. Furthermore, we show that the RL agent is capable of adjusting dynamically to noisy human responses. Finally, we design a continual learning strategy, which can be viewed as a data augmentation method, for the agent to improve further utilizing its interaction history with a human. We demonstrate the proposed strategy is substantially more realistic and data-efficient compared to previously proposed pre-exploration techniques.
Controlled Text Generation for Data Augmentation in Intelligent Artificial Agents
Oct 04, 2019
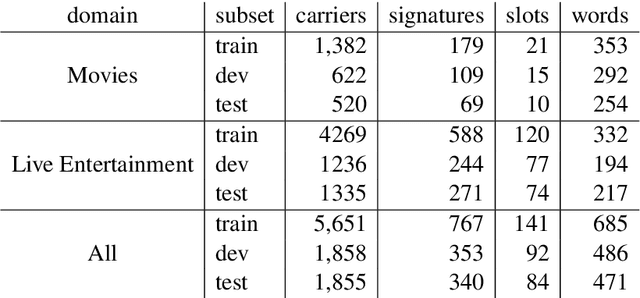
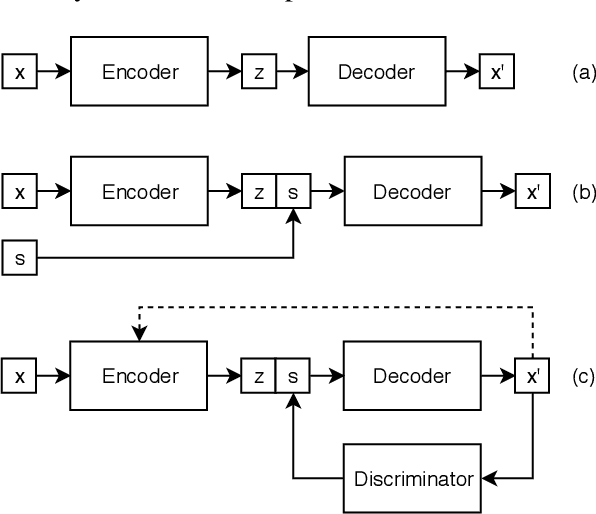
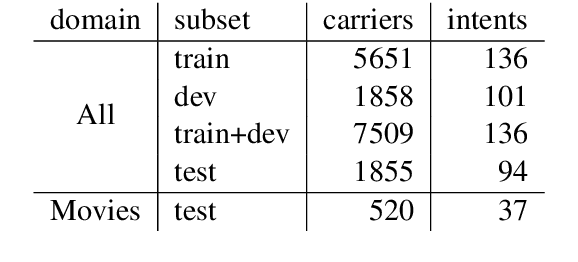
Data availability is a bottleneck during early stages of development of new capabilities for intelligent artificial agents. We investigate the use of text generation techniques to augment the training data of a popular commercial artificial agent across categories of functionality, with the goal of faster development of new functionality. We explore a variety of encoder-decoder generative models for synthetic training data generation and propose using conditional variational auto-encoders. Our approach requires only direct optimization, works well with limited data and significantly outperforms the previous controlled text generation techniques. Further, the generated data are used as additional training samples in an extrinsic intent classification task, leading to improved performance by up to 5\% absolute f-score in low-resource cases, validating the usefulness of our approach.