 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALF: Advertiser Large Foundation Model for Multi-Modal Advertiser Understanding
Apr 26, 2025



We present ALF (Advertiser Large Foundation model), a multi-modal transformer architecture for understanding advertiser behavior and intent across text, image, video and structured data modalities. Through contrastive learning and multi-task optimization, ALF creates unified advertiser representations that capture both content and behavioral patterns. Our model achieves state-of-the-art performance on critical tasks including fraud detection, policy violation identification, and advertiser similarity matching. In production deployment, ALF reduces false positives by 90% while maintaining 99.8% precision on abuse detection tasks. The architecture's effectiveness stems from its novel combination of multi-modal transformations, inter-sample attention mechanism, spectrally normalized projections, and calibrated probabilistic outputs.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
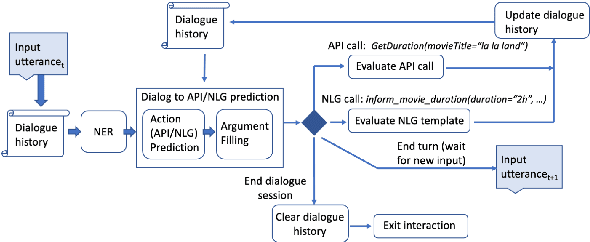

Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
Dialog Simulation with Realistic Variations for Training Goal-Oriented Conversational Systems
Nov 16, 2020
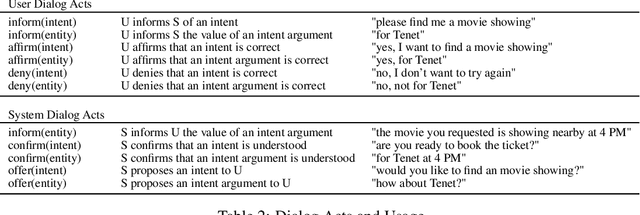
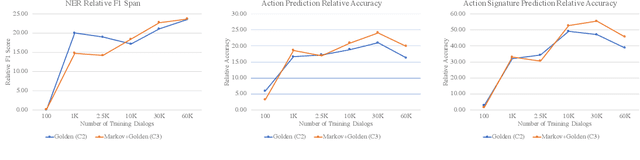
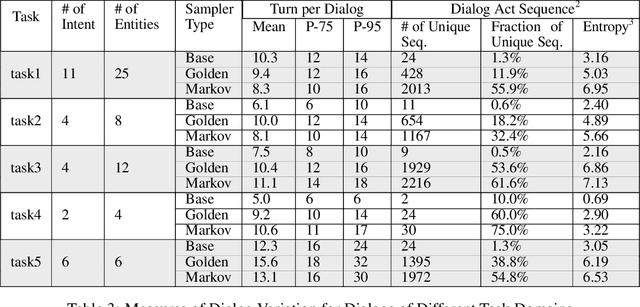
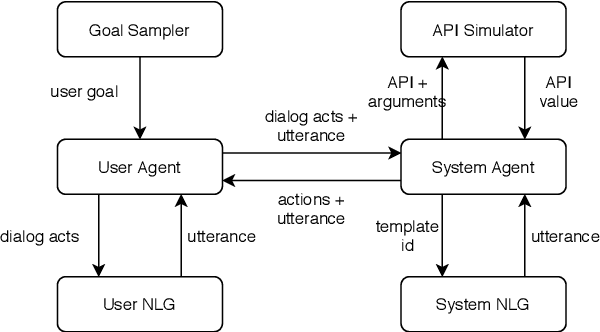
Goal-oriented dialog systems enable users to complete specific goals like requesting information about a movie or booking a ticket. Typically the dialog system pipeline contains multiple ML models, including natural language understanding, state tracking and action prediction (policy learning). These models are trained through a combination of supervised or reinforcement learning methods and therefore require collection of labeled domain specific datasets. However, collecting annotated datasets with language and dialog-flow variations is expensive, time-consuming and scales poorly due to human involvement. In this paper, we propose an approach for automatically creating a large corpus of annotated dialogs from a few thoroughly annotated sample dialogs and the dialog schema. Our approach includes a novel goal-sampling technique for sampling plausible user goals and a dialog simulation technique that uses heuristic interplay between the user and the system (Alexa), where the user tries to achieve the sampled goal. We validate our approach by generating data and training three different downstream conversational ML models. We achieve 18 ? 50% relative accuracy improvements on a held-out test set compared to a baseline dialog generation approach that only samples natural language and entity value variations from existing catalogs but does not generate any novel dialog flow variations. We also qualitatively establish that the proposed approach is better than the baseline. Moreover, several different conversational experiences have been built using this method, which enables customers to have a wide variety of conversations with Alexa.