 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialog Simulation with Realistic Variations for Training Goal-Oriented Conversational Systems
Nov 16, 2020
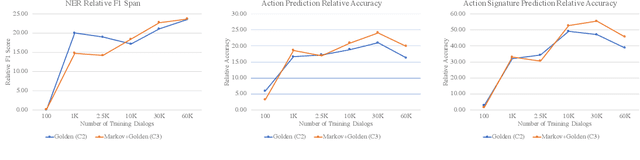
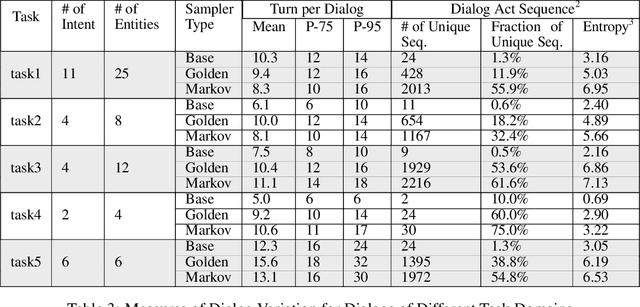
Goal-oriented dialog systems enable users to complete specific goals like requesting information about a movie or booking a ticket. Typically the dialog system pipeline contains multiple ML models, including natural language understanding, state tracking and action prediction (policy learning). These models are trained through a combination of supervised or reinforcement learning methods and therefore require collection of labeled domain specific datasets. However, collecting annotated datasets with language and dialog-flow variations is expensive, time-consuming and scales poorly due to human involvement. In this paper, we propose an approach for automatically creating a large corpus of annotated dialogs from a few thoroughly annotated sample dialogs and the dialog schema. Our approach includes a novel goal-sampling technique for sampling plausible user goals and a dialog simulation technique that uses heuristic interplay between the user and the system (Alexa), where the user tries to achieve the sampled goal. We validate our approach by generating data and training three different downstream conversational ML models. We achieve 18 ? 50% relative accuracy improvements on a held-out test set compared to a baseline dialog generation approach that only samples natural language and entity value variations from existing catalogs but does not generate any novel dialog flow variations. We also qualitatively establish that the proposed approach is better than the baseline. Moreover, several different conversational experiences have been built using this method, which enables customers to have a wide variety of conversations with Alexa.
Transforming Facial Weight of Real Images by Editing Latent Space of StyleGAN
Nov 05, 2020



We present an invert-and-edit framework to automatically transform facial weight of an input face image to look thinner or heavier by leveraging semantic facial attributes encoded in the latent space of Generative Adversarial Networks (GANs). Using a pre-trained StyleGAN as the underlying generator, we first employ an optimization-based embedding method to invert the input image into the StyleGAN latent space. Then, we identify the facial-weight attribute direction in the latent space via supervised learning and edit the inverted latent code by moving it positively or negatively along the extracted feature axis. Our framework is empirically shown to produce high-quality and realistic facial-weight transformations without requiring training GANs with a large amount of labeled face images from scratch. Ultimately, our framework can be utilized as part of an intervention to motivate individuals to make healthier food choices by visualizing the future impacts of their behavior on appearance.