 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALF: Advertiser Large Foundation Model for Multi-Modal Advertiser Understanding
Apr 26, 2025



We present ALF (Advertiser Large Foundation model), a multi-modal transformer architecture for understanding advertiser behavior and intent across text, image, video and structured data modalities. Through contrastive learning and multi-task optimization, ALF creates unified advertiser representations that capture both content and behavioral patterns. Our model achieves state-of-the-art performance on critical tasks including fraud detection, policy violation identification, and advertiser similarity matching. In production deployment, ALF reduces false positives by 90% while maintaining 99.8% precision on abuse detection tasks. The architecture's effectiveness stems from its novel combination of multi-modal transformations, inter-sample attention mechanism, spectrally normalized projections, and calibrated probabilistic outputs.
The Label Complexity of Active Learning from Observational Data
May 29, 2019
Counterfactual learning from observational data involves learning a classifier on an entire population based on data that is observed conditioned on a selection policy. This work considers this problem in an active setting, where the learner additionally has access to unlabeled examples and can choose to get a subset of these labeled by an oracle. Prior work on this problem uses disagreement-based active learning, along with an importance weighted loss estimator to account for counterfactuals, which leads to a high label complexity. We show how to instead incorporate a more efficient counterfactual risk minimizer into the active learning algorithm. This requires us to modify both the counterfactual risk to make it amenable to active learning, as well as the active learning process to make it amenable to the risk. We provably demonstrate that the result of this is an algorithm which is statistically consistent as well as more label-efficient than prior work.
Model Extraction and Active Learning
Dec 04, 2018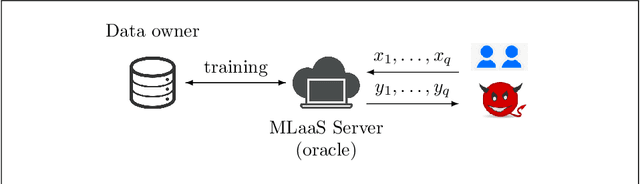
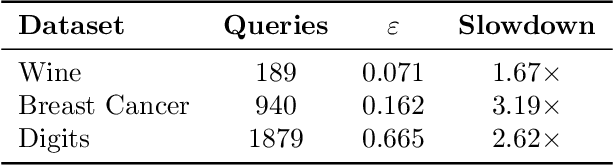
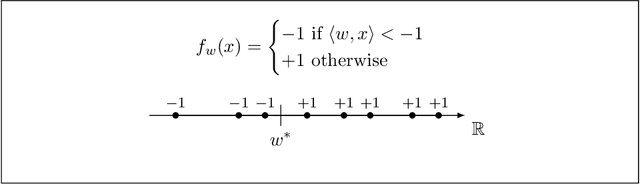
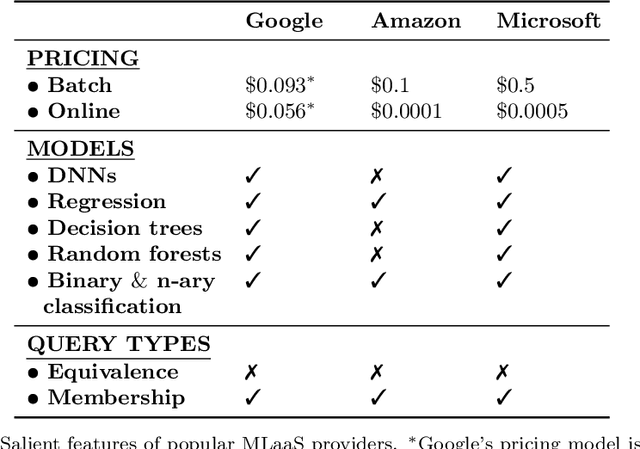
Machine learning is being increasingly used by individuals, research institutions, and corporations. This has resulted in the surge of Machine Learning-as-a-Service (MLaaS) cloud services that provide (a) tools and resources to learn the model, and (b) a user-friendly query interface to access the model. However, such MLaaS systems raise privacy concerns, one being model extraction. In model extraction attacks, adversaries maliciously exploit the query interface to steal the model. More precisely, in a model extraction attack, a good approximation of a sensitive or proprietary model held by the server is extracted (i.e. learned) by a dishonest user who interacts with the server only via the query interface. This attack was recently introduced by Tram\`er et al. at the 2016 USENIX Security Symposium, where practical attacks for various models were shown. We believe that better understanding the efficacy of model extraction attacks is paramount to designing better privacy-preserving MLaaS systems. To that end, we take the first step by (a) formalizing model extraction and discussing possible defense strategies, and (b) drawing parallels between model extraction and the better investigated active learning framework. In particular, we show that recent advancements in the active learning domain can be used to implement both model extraction attacks, and to investigate possible defense strategies.
Active Learning with Logged Data
Jun 13, 2018



We consider active learning with logged data, where labeled examples are drawn conditioned on a predetermined logging policy, and the goal is to learn a classifier on the entire population, not just conditioned on the logging policy. Prior work addresses this problem either when only logged data is available, or purely in a controlled random experimentation setting where the logged data is ignored. In this work, we combine both approaches to provide an algorithm that uses logged data to bootstrap and inform experimentation, thus achieving the best of both worlds. Our work is inspired by a connection between controlled random experimentation and active learning, and modifies existing disagreement-based active learning algorithms to exploit logged data.
Revisiting Perceptron: Efficient and Label-Optimal Learning of Halfspaces
Nov 06, 2017



It has been a long-standing problem to efficiently learn a halfspace using as few labels as possible in the presence of noise. In this work, we propose an efficient Perceptron-based algorithm for actively learning homogeneous halfspaces under the uniform distribution over the unit sphere. Under the bounded noise condition~\cite{MN06}, where each label is flipped with probability at most $\eta < \frac 1 2$, our algorithm achieves a near-optimal label complexity of $\tilde{O}\left(\frac{d}{(1-2\eta)^2}\ln\frac{1}{\epsilon}\right)$ in time $\tilde{O}\left(\frac{d^2}{\epsilon(1-2\eta)^3}\right)$. Under the adversarial noise condition~\cite{ABL14, KLS09, KKMS08}, where at most a $\tilde \Omega(\epsilon)$ fraction of labels can be flipped, our algorithm achieves a near-optimal label complexity of $\tilde{O}\left(d\ln\frac{1}{\epsilon}\right)$ in time $\tilde{O}\left(\frac{d^2}{\epsilon}\right)$. Furthermore, we show that our active learning algorithm can be converted to an efficient passive learning algorithm that has near-optimal sample complexities with respect to $\epsilon$ and $d$.
Active Learning from Imperfect Labelers
Oct 30, 2016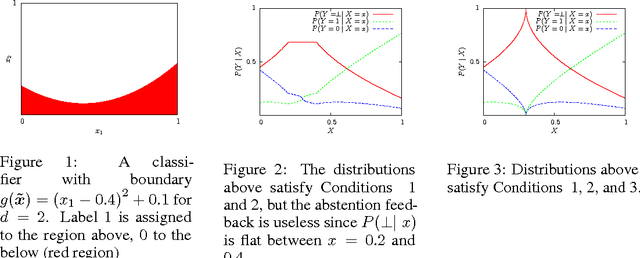
We study active learning where the labeler can not only return incorrect labels but also abstain from labeling. We consider different noise and abstention conditions of the labeler. We propose an algorithm which utilizes abstention responses, and analyze its statistical consistency and query complexity under fairly natural assumptions on the noise and abstention rate of the labeler. This algorithm is adaptive in a sense that it can automatically request less queries with a more informed or less noisy labeler. We couple our algorithm with lower bounds to show that under some technical conditions, it achieves nearly optimal query complexity.