 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Extraction and Active Learning
Dec 04, 2018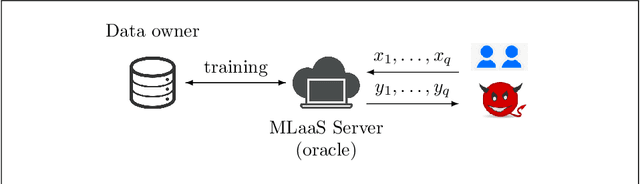
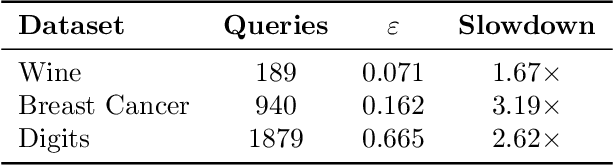
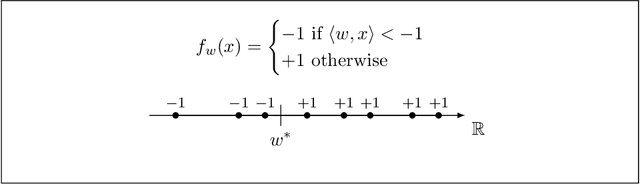
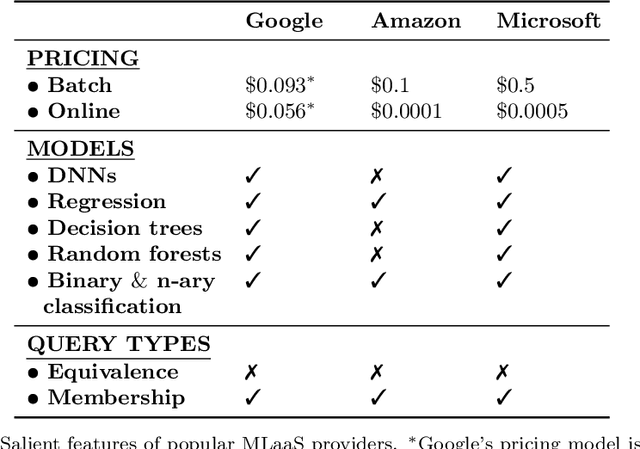
Machine learning is being increasingly used by individuals, research institutions, and corporations. This has resulted in the surge of Machine Learning-as-a-Service (MLaaS) cloud services that provide (a) tools and resources to learn the model, and (b) a user-friendly query interface to access the model. However, such MLaaS systems raise privacy concerns, one being model extraction. In model extraction attacks, adversaries maliciously exploit the query interface to steal the model. More precisely, in a model extraction attack, a good approximation of a sensitive or proprietary model held by the server is extracted (i.e. learned) by a dishonest user who interacts with the server only via the query interface. This attack was recently introduced by Tram\`er et al. at the 2016 USENIX Security Symposium, where practical attacks for various models were shown. We believe that better understanding the efficacy of model extraction attacks is paramount to designing better privacy-preserving MLaaS systems. To that end, we take the first step by (a) formalizing model extraction and discussing possible defense strategies, and (b) drawing parallels between model extraction and the better investigated active learning framework. In particular, we show that recent advancements in the active learning domain can be used to implement both model extraction attacks, and to investigate possible defense strategies.
Privacy-Preserving Collaborative Prediction using Random Forests
Nov 21, 2018

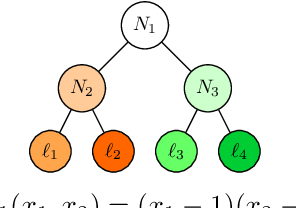
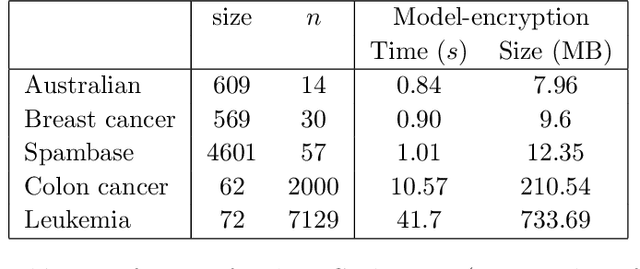
We study the problem of privacy-preserving machine learning (PPML) for ensemble methods, focusing our effort on random forests. In collaborative analysis, PPML attempts to solve the conflict between the need for data sharing and privacy. This is especially important in privacy sensitive applications such as learning predictive models for clinical decision support from EHR data from different clinics, where each clinic has a responsibility for its patients' privacy. We propose a new approach for ensemble methods: each entity learns a model, from its own data, and then when a client asks the prediction for a new private instance, the answers from all the locally trained models are used to compute the prediction in such a way that no extra information is revealed. We implement this approach for random forests and we demonstrate its high efficiency and potential accuracy benefit via experiments on real-world datasets, including actual EHR data.
Privacy Risk in Machine Learning: Analyzing the Connection to Overfitting
May 04, 2018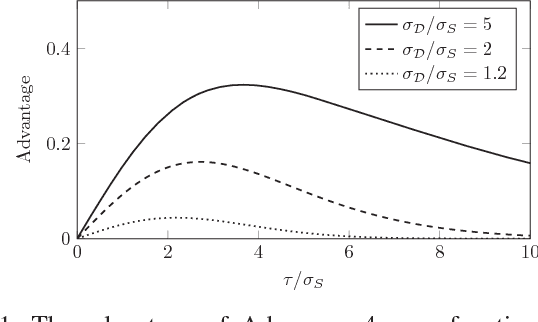
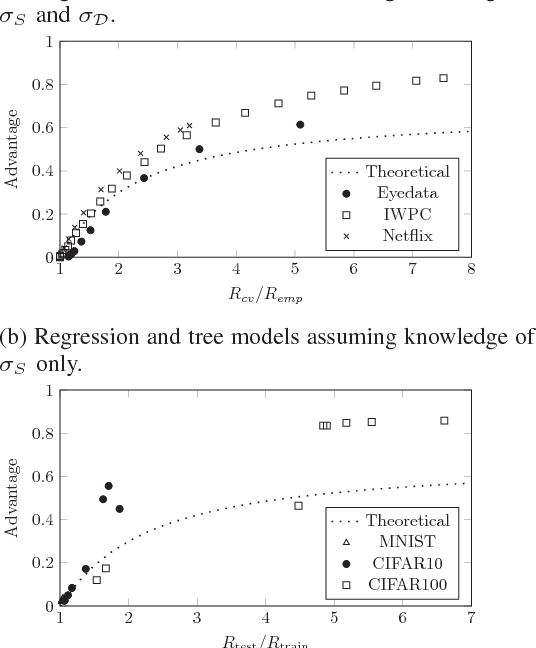
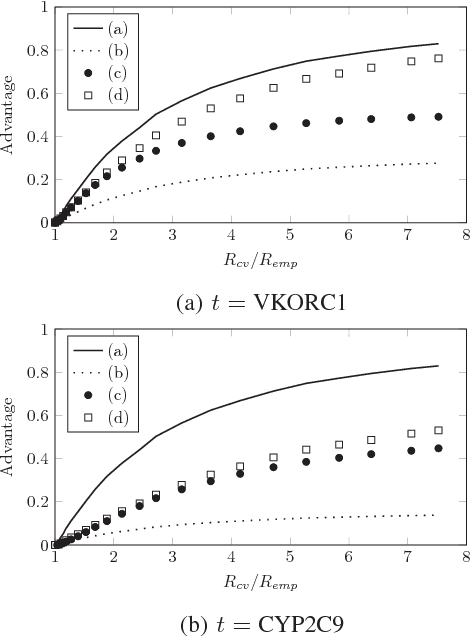
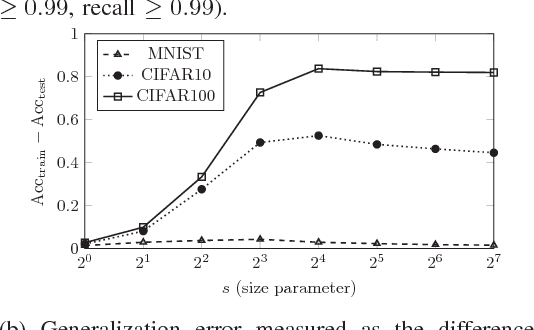
Machine learning algorithms, when applied to sensitive data, pose a distinct threat to privacy. A growing body of prior work demonstrates that models produced by these algorithms may leak specific private information in the training data to an attacker, either through the models' structure or their observable behavior. However, the underlying cause of this privacy risk is not well understood beyond a handful of anecdotal accounts that suggest overfitting and influence might play a role. This paper examines the effect that overfitting and influence have on the ability of an attacker to learn information about the training data from machine learning models, either through training set membership inference or attribute inference attacks. Using both formal and empirical analyses, we illustrate a clear relationship between these factors and the privacy risk that arises in several popular machine learning algorithms. We find that overfitting is sufficient to allow an attacker to perform membership inference and, when the target attribute meets certain conditions about its influence, attribute inference attacks. Interestingly, our formal analysis also shows that overfitting is not necessary for these attacks and begins to shed light on what other factors may be in play. Finally, we explore the connection between membership inference and attribute inference, showing that there are deep connections between the two that lead to effective new attacks.