 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-Box Audits for Group Distribution Shifts
Sep 08, 2022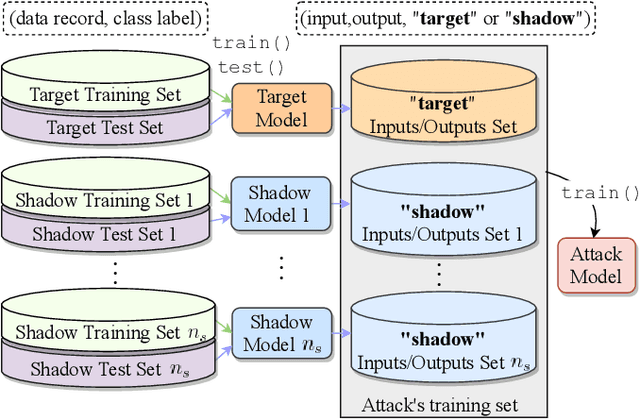
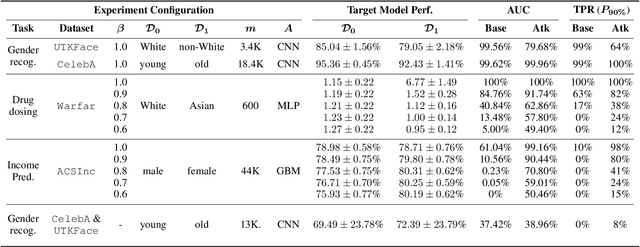
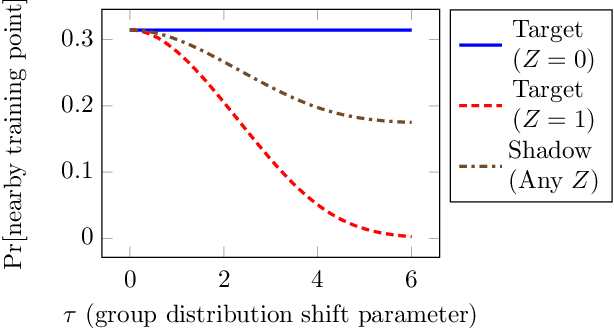
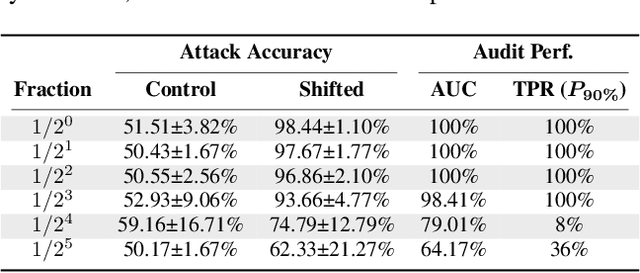
When a model informs decisions about people, distribution shifts can create undue disparities. However, it is hard for external entities to check for distribution shift, as the model and its training set are often proprietary. In this paper, we introduce and study a black-box auditing method to detect cases of distribution shift that lead to a performance disparity of the model across demographic groups. By extending techniques used in membership and property inference attacks -- which are designed to expose private information from learned models -- we demonstrate that an external auditor can gain the information needed to identify these distribution shifts solely by querying the model. Our experimental results on real-world datasets show that this approach is effective, achieving 80--100% AUC-ROC in detecting shifts involving the underrepresentation of a demographic group in the training set. Researchers and investigative journalists can use our tools to perform non-collaborative audits of proprietary models and expose cases of underrepresentation in the training datasets.
Individual Fairness Revisited: Transferring Techniques from Adversarial Robustness
Feb 24, 2020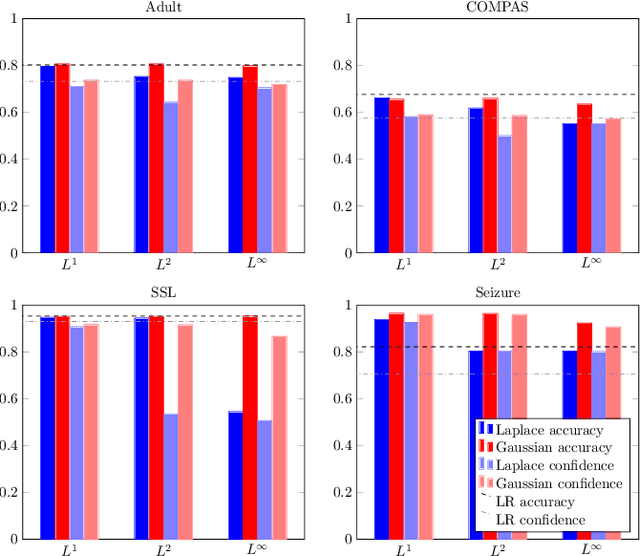
We turn the definition of individual fairness on its head---rather than ascertaining the fairness of a model given a predetermined metric, we find a metric for a given model that satisfies individual fairness. This can facilitate the discussion on the fairness of a model, addressing the issue that it may be difficult to specify a priori a suitable metric. Our contributions are twofold: First, we introduce the definition of a minimal metric and characterize the behavior of models in terms of minimal metrics. Second, for more complicated models, we apply the mechanism of randomized smoothing from adversarial robustness to make them individually fair under a given weighted $L^p$ metric. Our experiments show that adapting the minimal metrics of linear models to more complicated neural networks can lead to meaningful and interpretable fairness guarantees at little cost to utility.
Learning Fair Representations for Kernel Models
Jun 27, 2019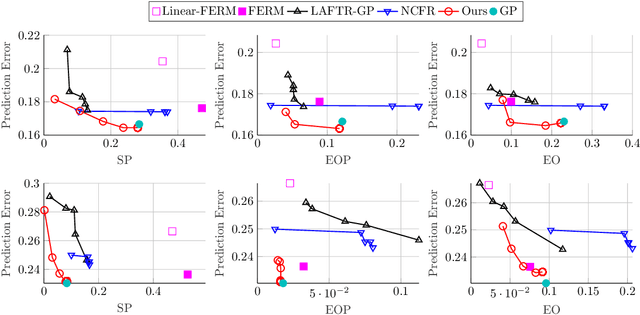
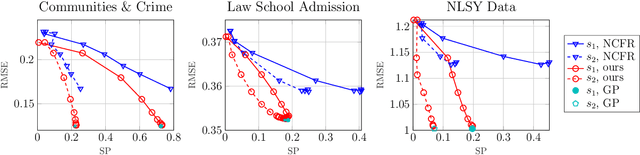
Fair representations are a powerful tool for establishing criteria like statistical parity, proxy non-discrimination, and equality of opportunity in learned models. Existing techniques for learning these representations are typically model-agnostic, as they preprocess the original data such that the output satisfies some fairness criterion, and can be used with arbitrary learning methods. In contrast, we demonstrate the promise of learning a model-aware fair representation, focusing on kernel-based models. We leverage the classical Sufficient Dimension Reduction (SDR) framework to construct representations as subspaces of the reproducing kernel Hilbert space (RKHS), whose member functions are guaranteed to satisfy fairness. Our method supports several fairness criteria, continuous and discrete data, and multiple protected attributes. We further show how to calibrate the accuracy tradeoff by characterizing it in terms of the principal angles between subspaces of the RKHS. Finally, we apply our approach to obtain the first Fair Gaussian Process (FGP) prior for fair Bayesian learning, and show that it is competitive with, and in some cases outperforms, state-of-the-art methods on real data.
FlipTest: Fairness Auditing via Optimal Transport
Jun 24, 2019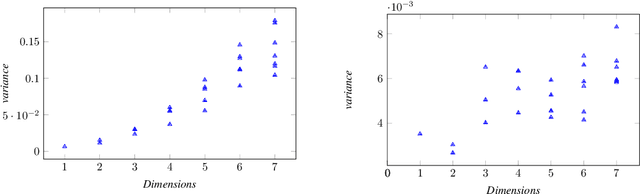
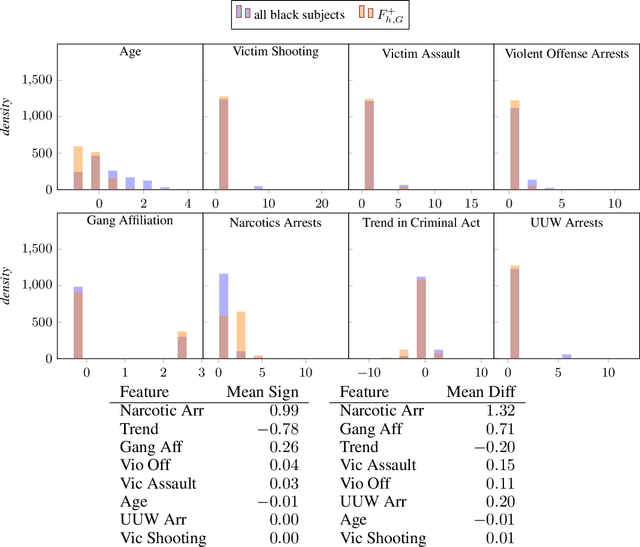
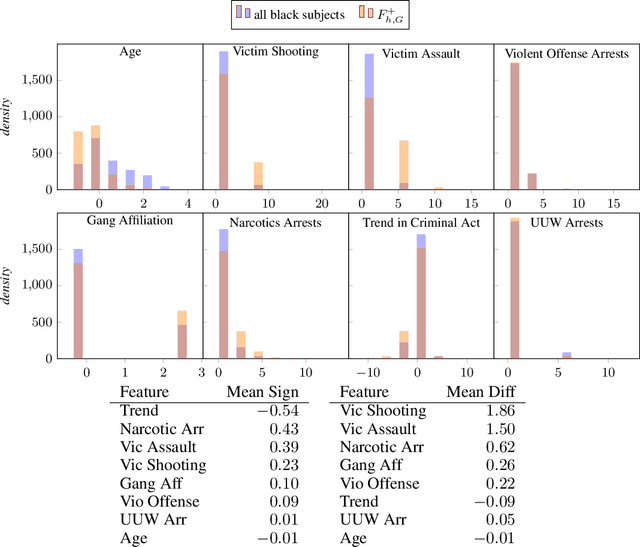
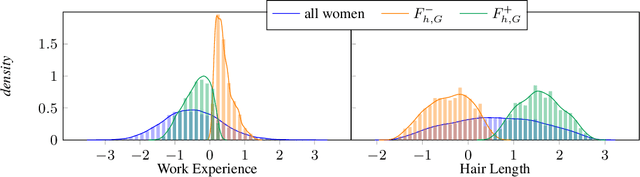
We present FlipTest, a black-box auditing technique for uncovering subgroup discrimination in predictive models. Combining the concepts of individual and group fairness, we search for discrimination by matching individuals in different protected groups to each other, and their comparing classifier outcomes. Specifically, we formulate a GAN-based approximation of the optimal transport mapping, and use it to translate the distribution of one protected group to that of another, returning pairs of in-distribution samples that statistically correspond to one another. We then define the flipset: the set of individuals whose classifier output changes post-translation, which intuitively corresponds to the set of people who were harmed because of their protected group membership. To shed light on why the model treats a given subgroup differently, we introduce the transparency report: a ranking of features that are most associated with the model's behavior on the flipset. We show that this provides a computationally inexpensive way to identify subgroups that are harmed by model discrimination, including in cases where the model satisfies population-level group fairness criteria.
Hunting for Discriminatory Proxies in Linear Regression Models
Nov 02, 2018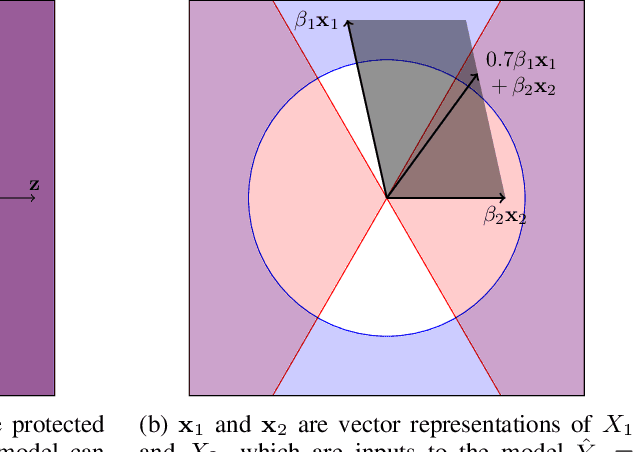


A machine learning model may exhibit discrimination when used to make decisions involving people. One potential cause for such outcomes is that the model uses a statistical proxy for a protected demographic attribute. In this paper we formulate a definition of proxy use for the setting of linear regression and present algorithms for detecting proxies. Our definition follows recent work on proxies in classification models, and characterizes a model's constituent behavior that: 1) correlates closely with a protected random variable, and 2) is causally influential in the overall behavior of the model. We show that proxies in linear regression models can be efficiently identified by solving a second-order cone program, and further extend this result to account for situations where the use of a certain input variable is justified as a `business necessity'. Finally, we present empirical results on two law enforcement datasets that exhibit varying degrees of racial disparity in prediction outcomes, demonstrating that proxies shed useful light on the causes of discriminatory behavior in models.
Discriminative but Not Discriminatory: A Comparison of Fairness Definitions under Different Worldviews
Sep 06, 2018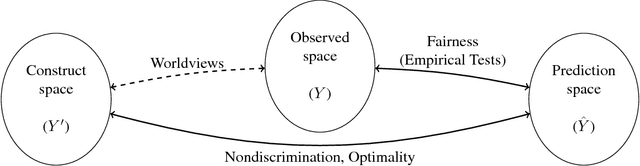
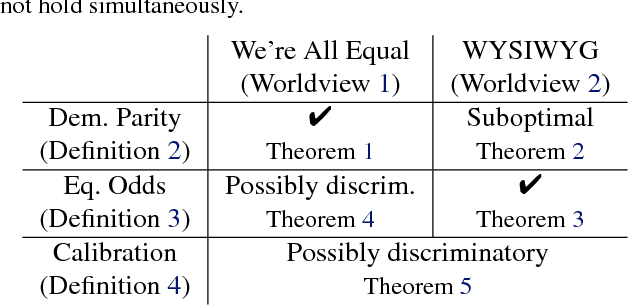
We mathematically compare three competing definitions of group-level nondiscrimination: demographic parity, equalized odds, and calibration. Using the theoretical framework of Friedler et al., we study the properties of each definition under various worldviews, which are assumptions about how, if at all, the observed data is biased. We prove that different worldviews call for different definitions of fairness, and we specify when it is appropriate to use demographic parity and equalized odds. In addition, we argue that calibration is unsuitable for the purpose of ensuring nondiscrimination. Finally, we define a worldview that is more realistic than the previously considered ones, and we introduce a new notion of fairness that is suitable for this worldview.
Privacy Risk in Machine Learning: Analyzing the Connection to Overfitting
May 04, 2018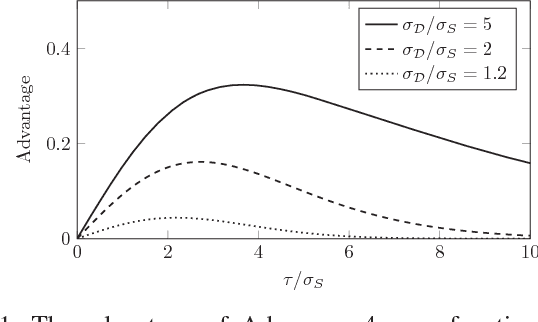
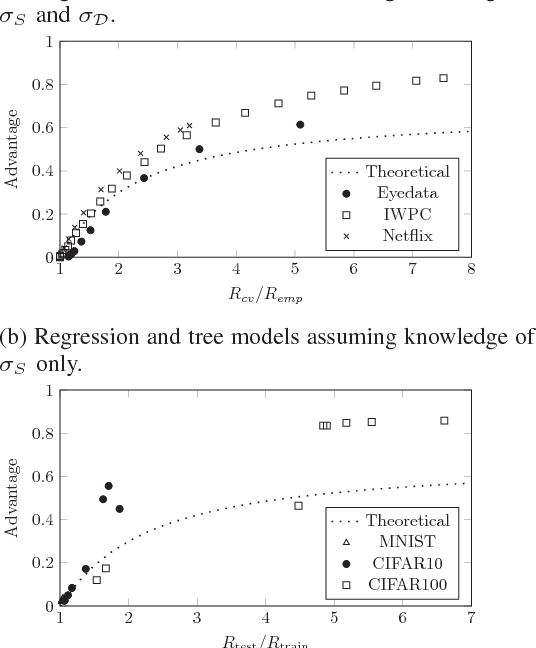
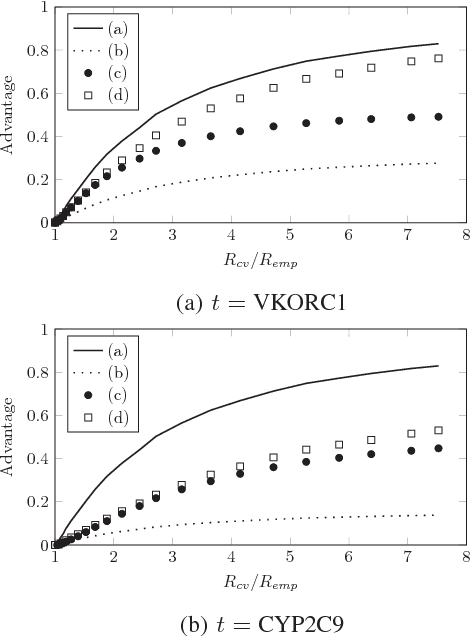
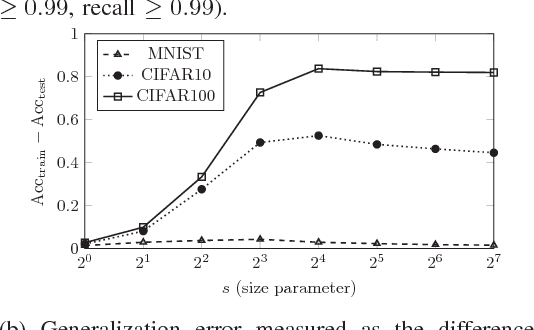
Machine learning algorithms, when applied to sensitive data, pose a distinct threat to privacy. A growing body of prior work demonstrates that models produced by these algorithms may leak specific private information in the training data to an attacker, either through the models' structure or their observable behavior. However, the underlying cause of this privacy risk is not well understood beyond a handful of anecdotal accounts that suggest overfitting and influence might play a role. This paper examines the effect that overfitting and influence have on the ability of an attacker to learn information about the training data from machine learning models, either through training set membership inference or attribute inference attacks. Using both formal and empirical analyses, we illustrate a clear relationship between these factors and the privacy risk that arises in several popular machine learning algorithms. We find that overfitting is sufficient to allow an attacker to perform membership inference and, when the target attribute meets certain conditions about its influence, attribute inference attacks. Interestingly, our formal analysis also shows that overfitting is not necessary for these attacks and begins to shed light on what other factors may be in play. Finally, we explore the connection between membership inference and attribute inference, showing that there are deep connections between the two that lead to effective new attacks.