 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmudged Fingerprints: A Systematic Evaluation of the Robustness of AI Image Fingerprints
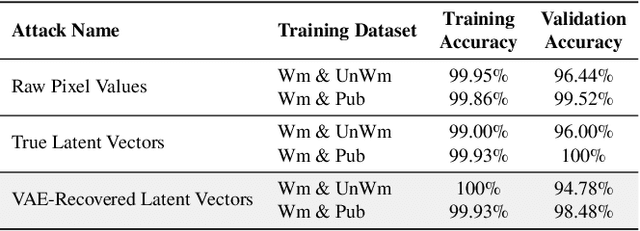
Dec 12, 2025Model fingerprint detection techniques have emerged as a promising approach for attributing AI-generated images to their source models, but their robustness under adversarial conditions remains largely unexplored. We present the first systematic security evaluation of these techniques, formalizing threat models that encompass both white- and black-box access and two attack goals: fingerprint removal, which erases identifying traces to evade attribution, and fingerprint forgery, which seeks to cause misattribution to a target model. We implement five attack strategies and evaluate 14 representative fingerprinting methods across RGB, frequency, and learned-feature domains on 12 state-of-the-art image generators. Our experiments reveal a pronounced gap between clean and adversarial performance. Removal attacks are highly effective, often achieving success rates above 80% in white-box settings and over 50% under constrained black-box access. While forgery is more challenging than removal, its success significantly varies across targeted models. We also identify a utility-robustness trade-off: methods with the highest attribution accuracy are often vulnerable to attacks. Although some techniques exhibit robustness in specific settings, none achieves high robustness and accuracy across all evaluated threat models. These findings highlight the need for techniques balancing robustness and accuracy, and identify the most promising approaches for advancing this goal.
A Crack in the Bark: Leveraging Public Knowledge to Remove Tree-Ring Watermarks
Jun 12, 2025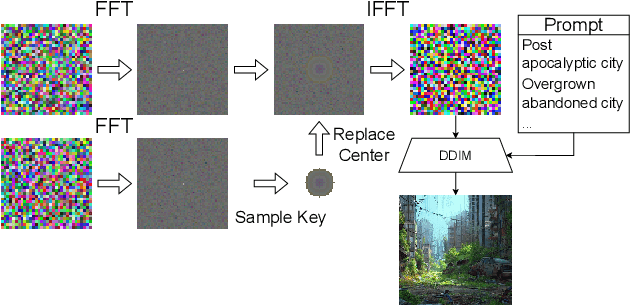
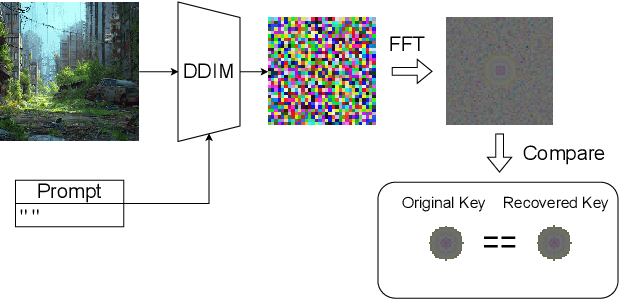
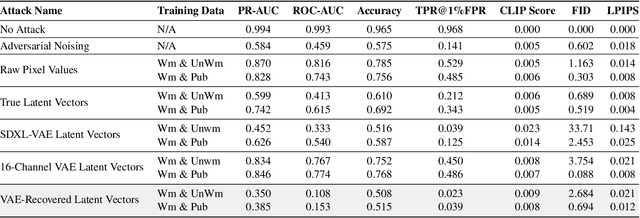
We present a novel attack specifically designed against Tree-Ring, a watermarking technique for diffusion models known for its high imperceptibility and robustness against removal attacks. Unlike previous removal attacks, which rely on strong assumptions about attacker capabilities, our attack only requires access to the variational autoencoder that was used to train the target diffusion model, a component that is often publicly available. By leveraging this variational autoencoder, the attacker can approximate the model's intermediate latent space, enabling more effective surrogate-based attacks. Our evaluation shows that this approach leads to a dramatic reduction in the AUC of Tree-Ring detector's ROC and PR curves, decreasing from 0.993 to 0.153 and from 0.994 to 0.385, respectively, while maintaining high image quality. Notably, our attacks outperform existing methods that assume full access to the diffusion model. These findings highlight the risk of reusing public autoencoders to train diffusion models -- a threat not considered by current industry practices. Furthermore, the results suggest that the Tree-Ring detector's precision, a metric that has been overlooked by previous evaluations, falls short of the requirements for real-world deployment.
SoK: What Makes Private Learning Unfair?
Jan 24, 2025Differential privacy has emerged as the most studied framework for privacy-preserving machine learning. However, recent studies show that enforcing differential privacy guarantees can not only significantly degrade the utility of the model, but also amplify existing disparities in its predictive performance across demographic groups. Although there is extensive research on the identification of factors that contribute to this phenomenon, we still lack a complete understanding of the mechanisms through which differential privacy exacerbates disparities. The literature on this problem is muddled by varying definitions of fairness, differential privacy mechanisms, and inconsistent experimental settings, often leading to seemingly contradictory results. This survey provides the first comprehensive overview of the factors that contribute to the disparate effect of training models with differential privacy guarantees. We discuss their impact and analyze their causal role in such a disparate effect. Our analysis is guided by a taxonomy that categorizes these factors by their position within the machine learning pipeline, allowing us to draw conclusions about their interaction and the feasibility of potential mitigation strategies. We find that factors related to the training dataset and the underlying distribution play a decisive role in the occurrence of disparate impact, highlighting the need for research on these factors to address the issue.
Towards Understanding the Interplay of Generative Artificial Intelligence and the Internet
Jun 08, 2023

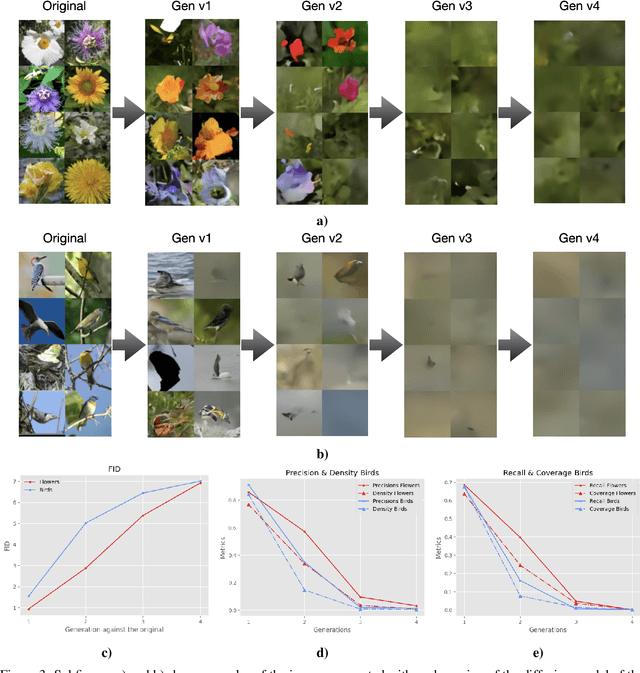
The rapid adoption of generative Artificial Intelligence (AI) tools that can generate realistic images or text, such as DALL-E, MidJourney, or ChatGPT, have put the societal impacts of these technologies at the center of public debate. These tools are possible due to the massive amount of data (text and images) that is publicly available through the Internet. At the same time, these generative AI tools become content creators that are already contributing to the data that is available to train future models. Therefore, future versions of generative AI tools will be trained with a mix of human-created and AI-generated content, causing a potential feedback loop between generative AI and public data repositories. This interaction raises many questions: how will future versions of generative AI tools behave when trained on a mixture of real and AI generated data? Will they evolve and improve with the new data sets or on the contrary will they degrade? Will evolution introduce biases or reduce diversity in subsequent generations of generative AI tools? What are the societal implications of the possible degradation of these models? Can we mitigate the effects of this feedback loop? In this document, we explore the effect of this interaction and report some initial results using simple diffusion models trained with various image datasets. Our results show that the quality and diversity of the generated images can degrade over time suggesting that incorporating AI-created data can have undesired effects on future versions of generative models.
Combining Generative Artificial Intelligence (AI) and the Internet: Heading towards Evolution or Degradation?
Feb 17, 2023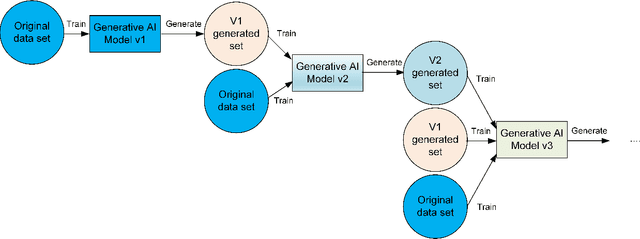



In the span of a few months, generative Artificial Intelligence (AI) tools that can generate realistic images or text have taken the Internet by storm, making them one of the technologies with fastest adoption ever. Some of these generative AI tools such as DALL-E, MidJourney, or ChatGPT have gained wide public notoriety. Interestingly, these tools are possible because of the massive amount of data (text and images) available on the Internet. The tools are trained on massive data sets that are scraped from Internet sites. And now, these generative AI tools are creating massive amounts of new data that are being fed into the Internet. Therefore, future versions of generative AI tools will be trained with Internet data that is a mix of original and AI-generated data. As time goes on, a mixture of original data and data generated by different versions of AI tools will populate the Internet. This raises a few intriguing questions: how will future versions of generative AI tools behave when trained on a mixture of real and AI generated data? Will they evolve with the new data sets or degenerate? Will evolution introduce biases in subsequent generations of generative AI tools? In this document, we explore these questions and report some very initial simulation results using a simple image-generation AI tool. These results suggest that the quality of the generated images degrades as more AI-generated data is used for training thus suggesting that generative AI may degenerate. Although these results are preliminary and cannot be generalised without further study, they serve to illustrate the potential issues of the interaction between generative AI and the Internet.
Black-Box Audits for Group Distribution Shifts
Sep 08, 2022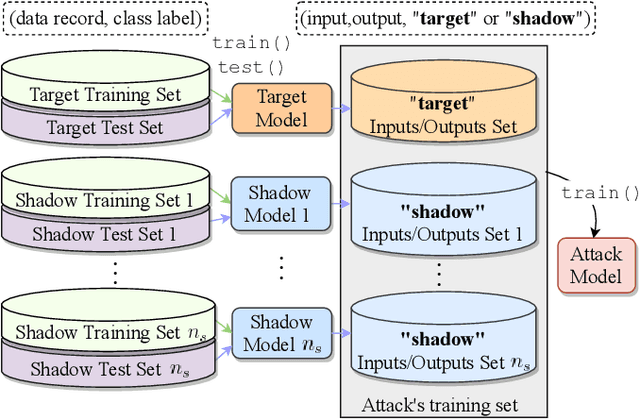
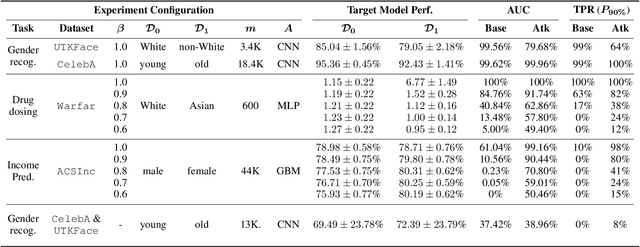
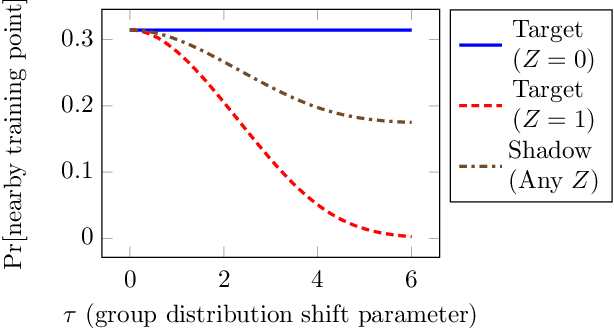
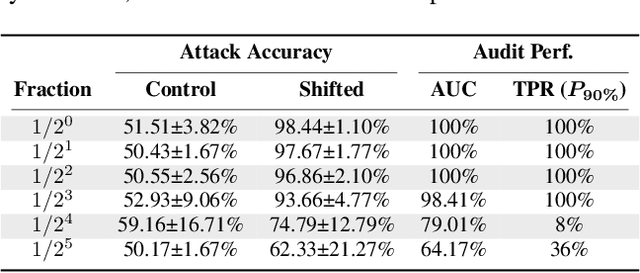
When a model informs decisions about people, distribution shifts can create undue disparities. However, it is hard for external entities to check for distribution shift, as the model and its training set are often proprietary. In this paper, we introduce and study a black-box auditing method to detect cases of distribution shift that lead to a performance disparity of the model across demographic groups. By extending techniques used in membership and property inference attacks -- which are designed to expose private information from learned models -- we demonstrate that an external auditor can gain the information needed to identify these distribution shifts solely by querying the model. Our experimental results on real-world datasets show that this approach is effective, achieving 80--100% AUC-ROC in detecting shifts involving the underrepresentation of a demographic group in the training set. Researchers and investigative journalists can use our tools to perform non-collaborative audits of proprietary models and expose cases of underrepresentation in the training datasets.
"You Can't Fix What You Can't Measure": Privately Measuring Demographic Performance Disparities in Federated Learning
Jun 24, 2022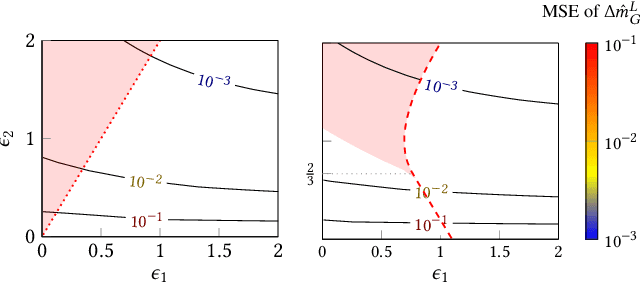
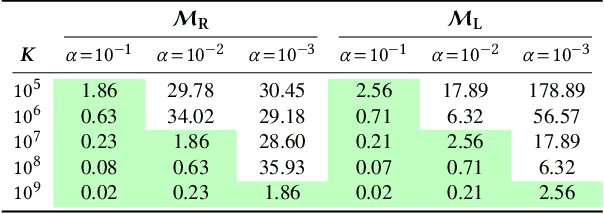
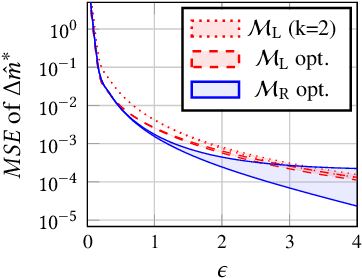

Federated learning allows many devices to collaborate in the training of machine learning models. As in traditional machine learning, there is a growing concern that models trained with federated learning may exhibit disparate performance for different demographic groups. Existing solutions to measure and ensure equal model performance across groups require access to information about group membership, but this access is not always available or desirable, especially under the privacy aspirations of federated learning. We study the feasibility of measuring such performance disparities while protecting the privacy of the user's group membership and the federated model's performance on the user's data. Protecting both is essential for privacy, because they may be correlated, and thus learning one may reveal the other. On the other hand, from the utility perspective, the privacy-preserved data should maintain the correlation to ensure the ability to perform accurate measurements of the performance disparity. We achieve both of these goals by developing locally differentially private mechanisms that preserve the correlations between group membership and model performance. To analyze the effectiveness of the mechanisms, we bound their error in estimating the disparity when optimized for a given privacy budget, and validate these bounds on synthetic data. Our results show that the error rapidly decreases for realistic numbers of participating clients, demonstrating that, contrary to what prior work suggested, protecting the privacy of protected attributes is not necessarily in conflict with identifying disparities in the performance of federated models.
Automated Website Fingerprinting through Deep Learning
Dec 05, 2017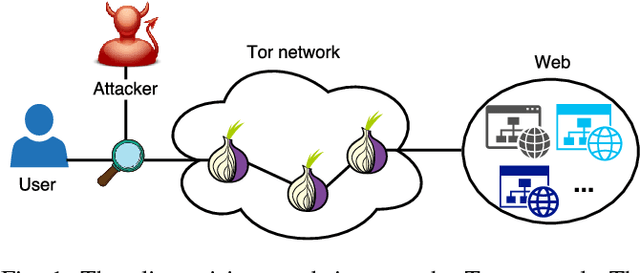
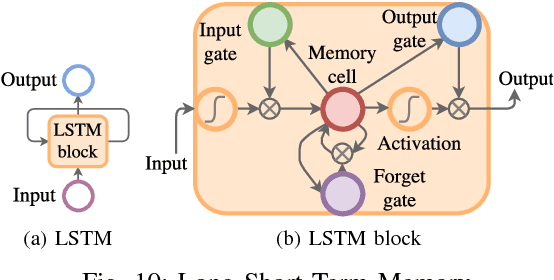
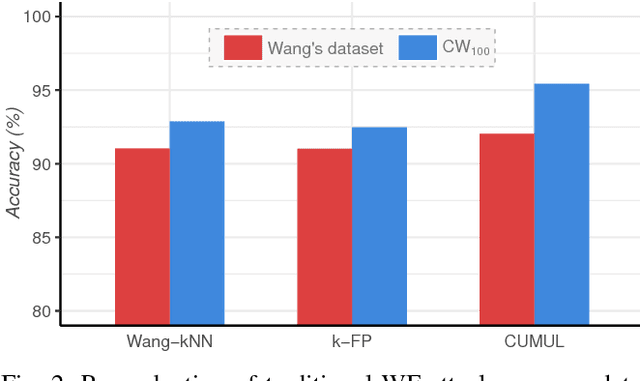
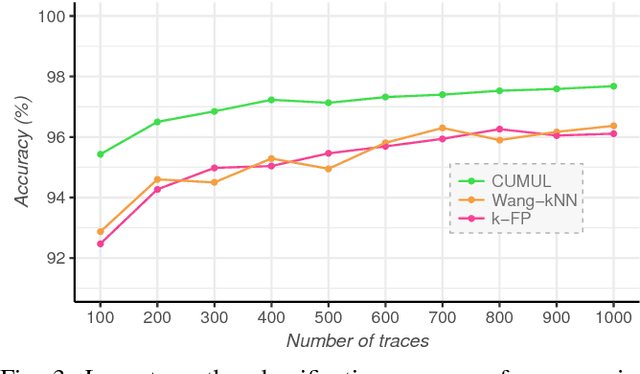
Several studies have shown that the network traffic that is generated by a visit to a website over Tor reveals information specific to the website through the timing and sizes of network packets. By capturing traffic traces between users and their Tor entry guard, a network eavesdropper can leverage this meta-data to reveal which website Tor users are visiting. The success of such attacks heavily depends on the particular set of traffic features that are used to construct the fingerprint. Typically, these features are manually engineered and, as such, any change introduced to the Tor network can render these carefully constructed features ineffective. In this paper, we show that an adversary can automate the feature engineering process, and thus automatically deanonymize Tor traffic by applying our novel method based on deep learning. We collect a dataset comprised of more than three million network traces, which is the largest dataset of web traffic ever used for website fingerprinting, and find that the performance achieved by our deep learning approaches is comparable to known methods which include various research efforts spanning over multiple years. The obtained success rate exceeds 96% for a closed world of 100 websites and 94% for our biggest closed world of 900 classes. In our open world evaluation, the most performant deep learning model is 2% more accurate than the state-of-the-art attack. Furthermore, we show that the implicit features automatically learned by our approach are far more resilient to dynamic changes of web content over time. We conclude that the ability to automatically construct the most relevant traffic features and perform accurate traffic recognition makes our deep learning based approach an efficient, flexible and robust technique for website fingerprinting.