 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowPure: Continuous Normalizing Flows for Adversarial Purification
May 19, 2025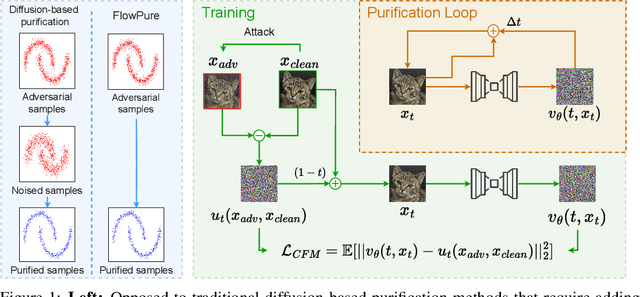
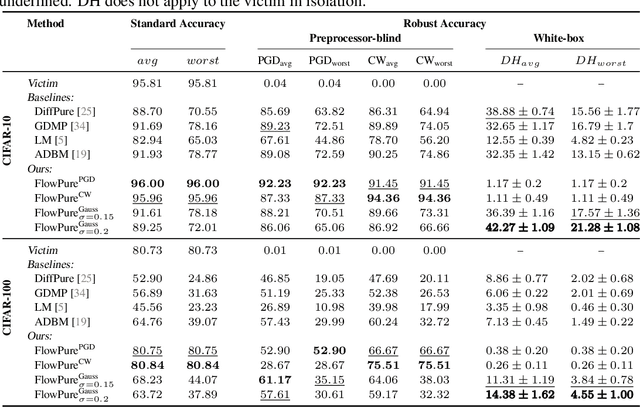
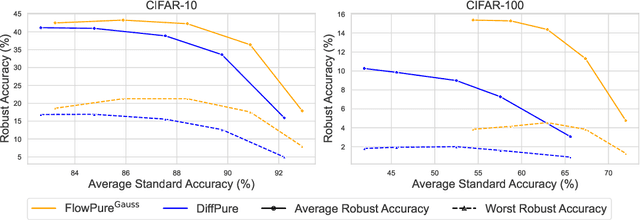
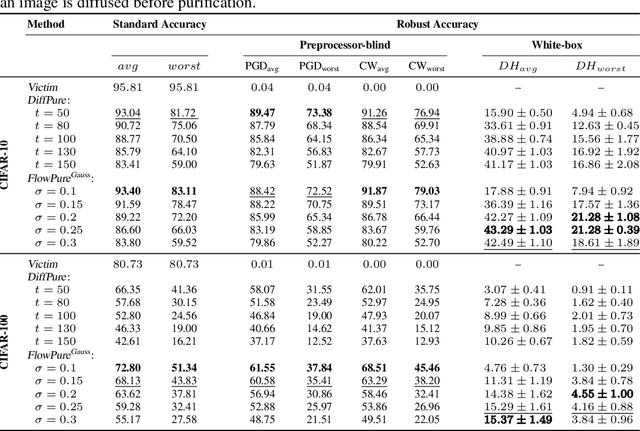
Despite significant advancements in the area, adversarial robustness remains a critical challenge in systems employing machine learning models. The removal of adversarial perturbations at inference time, known as adversarial purification, has emerged as a promising defense strategy. To achieve this, state-of-the-art methods leverage diffusion models that inject Gaussian noise during a forward process to dilute adversarial perturbations, followed by a denoising step to restore clean samples before classification. In this work, we propose FlowPure, a novel purification method based on Continuous Normalizing Flows (CNFs) trained with Conditional Flow Matching (CFM) to learn mappings from adversarial examples to their clean counterparts. Unlike prior diffusion-based approaches that rely on fixed noise processes, FlowPure can leverage specific attack knowledge to improve robustness under known threats, while also supporting a more general stochastic variant trained on Gaussian perturbations for settings where such knowledge is unavailable. Experiments on CIFAR-10 and CIFAR-100 demonstrate that our method outperforms state-of-the-art purification-based defenses in preprocessor-blind and white-box scenarios, and can do so while fully preserving benign accuracy in the former. Moreover, our results show that not only is FlowPure a highly effective purifier but it also holds a strong potential for adversarial detection, identifying preprocessor-blind PGD samples with near-perfect accuracy.
SoK: On the Offensive Potential of AI
Dec 24, 2024



Our society increasingly benefits from Artificial Intelligence (AI). Unfortunately, more and more evidence shows that AI is also used for offensive purposes. Prior works have revealed various examples of use cases in which the deployment of AI can lead to violation of security and privacy objectives. No extant work, however, has been able to draw a holistic picture of the offensive potential of AI. In this SoK paper we seek to lay the ground for a systematic analysis of the heterogeneous capabilities of offensive AI. In particular we (i) account for AI risks to both humans and systems while (ii) consolidating and distilling knowledge from academic literature, expert opinions, industrial venues, as well as laymen -- all of which being valuable sources of information on offensive AI. To enable alignment of such diverse sources of knowledge, we devise a common set of criteria reflecting essential technological factors related to offensive AI. With the help of such criteria, we systematically analyze: 95 research papers; 38 InfoSec briefings (from, e.g., BlackHat); the responses of a user study (N=549) entailing individuals with diverse backgrounds and expertise; and the opinion of 12 experts. Our contributions not only reveal concerning ways (some of which overlooked by prior work) in which AI can be offensively used today, but also represent a foothold to address this threat in the years to come.
Adversarial Markov Games: On Adaptive Decision-Based Attacks and Defenses
Dec 20, 2023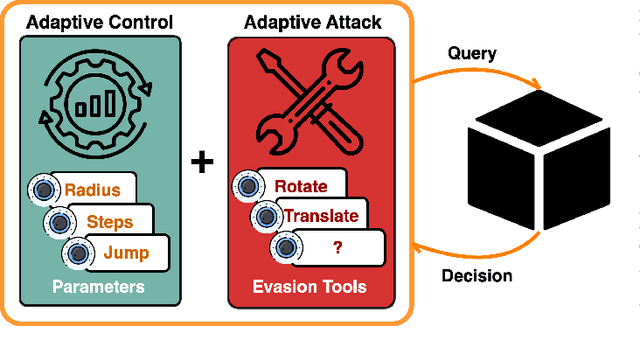
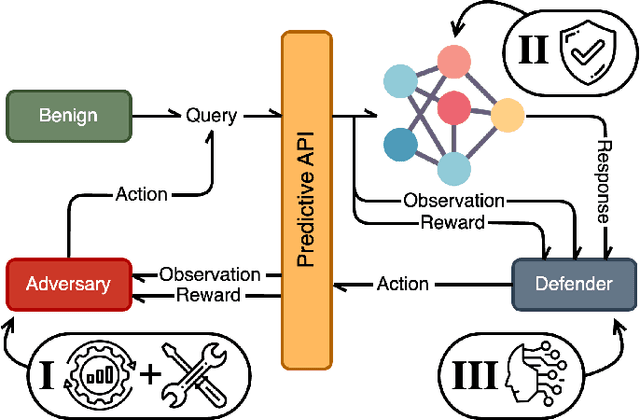
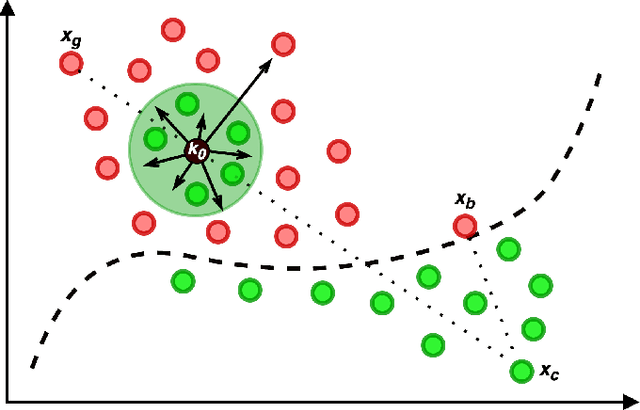
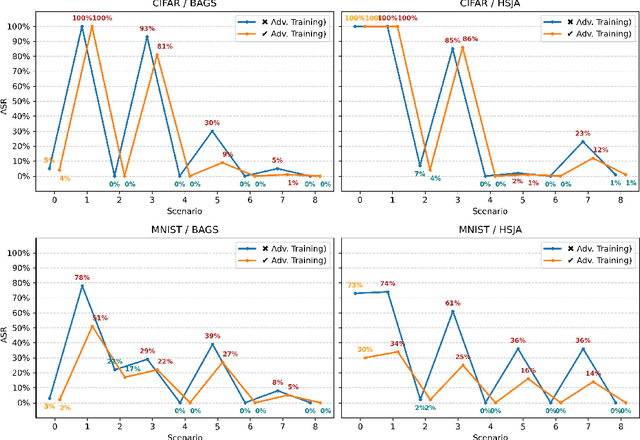
Despite considerable efforts on making them robust, real-world ML-based systems remain vulnerable to decision based attacks, as definitive proofs of their operational robustness have so far proven intractable. The canonical approach in robustness evaluation calls for adaptive attacks, that is with complete knowledge of the defense and tailored to bypass it. In this study, we introduce a more expansive notion of being adaptive and show how attacks but also defenses can benefit by it and by learning from each other through interaction. We propose and evaluate a framework for adaptively optimizing black-box attacks and defenses against each other through the competitive game they form. To reliably measure robustness, it is important to evaluate against realistic and worst-case attacks. We thus augment both attacks and the evasive arsenal at their disposal through adaptive control, and observe that the same can be done for defenses, before we evaluate them first apart and then jointly under a multi-agent perspective. We demonstrate that active defenses, which control how the system responds, are a necessary complement to model hardening when facing decision-based attacks; then how these defenses can be circumvented by adaptive attacks, only to finally elicit active and adaptive defenses. We validate our observations through a wide theoretical and empirical investigation to confirm that AI-enabled adversaries pose a considerable threat to black-box ML-based systems, rekindling the proverbial arms race where defenses have to be AI-enabled too. Succinctly, we address the challenges posed by adaptive adversaries and develop adaptive defenses, thereby laying out effective strategies in ensuring the robustness of ML-based systems deployed in the real-world.
Automated Website Fingerprinting through Deep Learning
Dec 05, 2017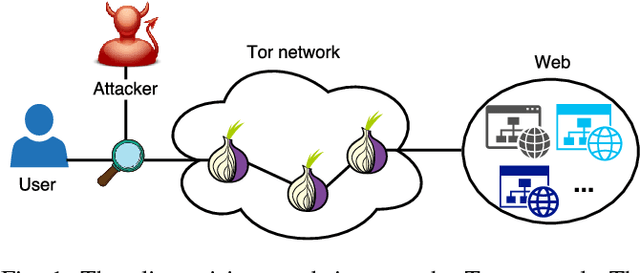
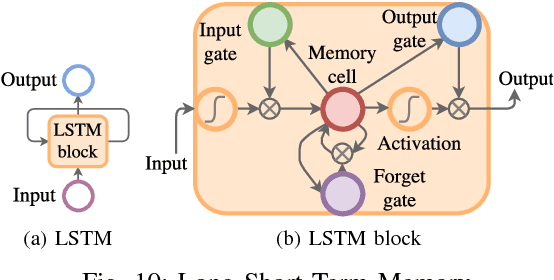
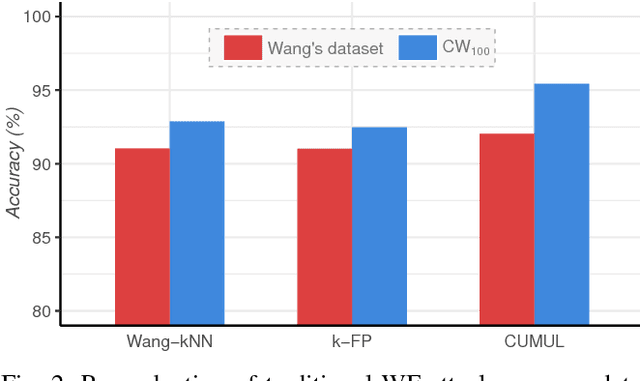
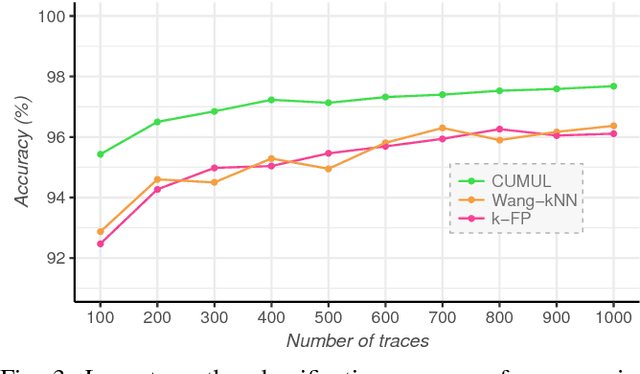
Several studies have shown that the network traffic that is generated by a visit to a website over Tor reveals information specific to the website through the timing and sizes of network packets. By capturing traffic traces between users and their Tor entry guard, a network eavesdropper can leverage this meta-data to reveal which website Tor users are visiting. The success of such attacks heavily depends on the particular set of traffic features that are used to construct the fingerprint. Typically, these features are manually engineered and, as such, any change introduced to the Tor network can render these carefully constructed features ineffective. In this paper, we show that an adversary can automate the feature engineering process, and thus automatically deanonymize Tor traffic by applying our novel method based on deep learning. We collect a dataset comprised of more than three million network traces, which is the largest dataset of web traffic ever used for website fingerprinting, and find that the performance achieved by our deep learning approaches is comparable to known methods which include various research efforts spanning over multiple years. The obtained success rate exceeds 96% for a closed world of 100 websites and 94% for our biggest closed world of 900 classes. In our open world evaluation, the most performant deep learning model is 2% more accurate than the state-of-the-art attack. Furthermore, we show that the implicit features automatically learned by our approach are far more resilient to dynamic changes of web content over time. We conclude that the ability to automatically construct the most relevant traffic features and perform accurate traffic recognition makes our deep learning based approach an efficient, flexible and robust technique for website fingerprinting.