 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Promptware Kill Chain: How Prompt Injections Gradually Evolved Into a Multi-Step Malware
Jan 14, 2026The rapid adoption of large language model (LLM)-based systems -- from chatbots to autonomous agents capable of executing code and financial transactions -- has created a new attack surface that existing security frameworks inadequately address. The dominant framing of these threats as "prompt injection" -- a catch-all phrase for security failures in LLM-based systems -- obscures a more complex reality: Attacks on LLM-based systems increasingly involve multi-step sequences that mirror traditional malware campaigns. In this paper, we propose that attacks targeting LLM-based applications constitute a distinct class of malware, which we term \textit{promptware}, and introduce a five-step kill chain model for analyzing these threats. The framework comprises Initial Access (prompt injection), Privilege Escalation (jailbreaking), Persistence (memory and retrieval poisoning), Lateral Movement (cross-system and cross-user propagation), and Actions on Objective (ranging from data exfiltration to unauthorized transactions). By mapping recent attacks to this structure, we demonstrate that LLM-related attacks follow systematic sequences analogous to traditional malware campaigns. The promptware kill chain offers security practitioners a structured methodology for threat modeling and provides a common vocabulary for researchers across AI safety and cybersecurity to address a rapidly evolving threat landscape.
PaniCar: Securing the Perception of Advanced Driving Assistance Systems Against Emergency Vehicle Lighting
May 08, 2025
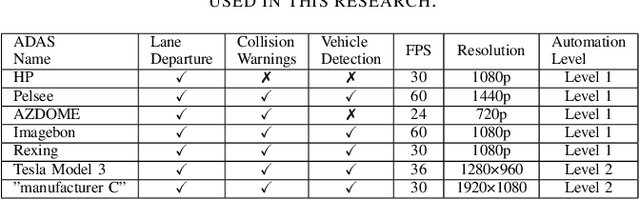

The safety of autonomous cars has come under scrutiny in recent years, especially after 16 documented incidents involving Teslas (with autopilot engaged) crashing into parked emergency vehicles (police cars, ambulances, and firetrucks). While previous studies have revealed that strong light sources often introduce flare artifacts in the captured image, which degrade the image quality, the impact of flare on object detection performance remains unclear. In this research, we unveil PaniCar, a digital phenomenon that causes an object detector's confidence score to fluctuate below detection thresholds when exposed to activated emergency vehicle lighting. This vulnerability poses a significant safety risk, and can cause autonomous vehicles to fail to detect objects near emergency vehicles. In addition, this vulnerability could be exploited by adversaries to compromise the security of advanced driving assistance systems (ADASs). We assess seven commercial ADASs (Tesla Model 3, "manufacturer C", HP, Pelsee, AZDOME, Imagebon, Rexing), four object detectors (YOLO, SSD, RetinaNet, Faster R-CNN), and 14 patterns of emergency vehicle lighting to understand the influence of various technical and environmental factors. We also evaluate four SOTA flare removal methods and show that their performance and latency are insufficient for real-time driving constraints. To mitigate this risk, we propose Caracetamol, a robust framework designed to enhance the resilience of object detectors against the effects of activated emergency vehicle lighting. Our evaluation shows that on YOLOv3 and Faster RCNN, Caracetamol improves the models' average confidence of car detection by 0.20, the lower confidence bound by 0.33, and reduces the fluctuation range by 0.33. In addition, Caracetamol is capable of processing frames at a rate of between 30-50 FPS, enabling real-time ADAS car detection.
A Privacy Enhancing Technique to Evade Detection by Street Video Cameras Without Using Adversarial Accessories
Jan 26, 2025



In this paper, we propose a privacy-enhancing technique leveraging an inherent property of automatic pedestrian detection algorithms, namely, that the training of deep neural network (DNN) based methods is generally performed using curated datasets and laboratory settings, while the operational areas of these methods are dynamic real-world environments. In particular, we leverage a novel side effect of this gap between the laboratory and the real world: location-based weakness in pedestrian detection. We demonstrate that the position (distance, angle, height) of a person, and ambient light level, directly impact the confidence of a pedestrian detector when detecting the person. We then demonstrate that this phenomenon is present in pedestrian detectors observing a stationary scene of pedestrian traffic, with blind spot areas of weak detection of pedestrians with low confidence. We show how privacy-concerned pedestrians can leverage these blind spots to evade detection by constructing a minimum confidence path between two points in a scene, reducing the maximum confidence and average confidence of the path by up to 0.09 and 0.13, respectively, over direct and random paths through the scene. To counter this phenomenon, and force the use of more costly and sophisticated methods to leverage this vulnerability, we propose a novel countermeasure to improve the confidence of pedestrian detectors in blind spots, raising the max/average confidence of paths generated by our technique by 0.09 and 0.05, respectively. In addition, we demonstrate that our countermeasure improves a Faster R-CNN-based pedestrian detector's TPR and average true positive confidence by 0.03 and 0.15, respectively.
Towards an End-to-End (E2E) Adversarial Learning and Application in the Physical World
Jan 16, 2025The traditional learning process of patch-based adversarial attacks, conducted in the digital domain and then applied in the physical domain (e.g., via printed stickers), may suffer from reduced performance due to adversarial patches' limited transferability from the digital domain to the physical domain. Given that previous studies have considered using projectors to apply adversarial attacks, we raise the following question: can adversarial learning (i.e., patch generation) be performed entirely in the physical domain with a projector? In this work, we propose the Physical-domain Adversarial Patch Learning Augmentation (PAPLA) framework, a novel end-to-end (E2E) framework that converts adversarial learning from the digital domain to the physical domain using a projector. We evaluate PAPLA across multiple scenarios, including controlled laboratory settings and realistic outdoor environments, demonstrating its ability to ensure attack success compared to conventional digital learning-physical application (DL-PA) methods. We also analyze the impact of environmental factors, such as projection surface color, projector strength, ambient light, distance, and angle of the target object relative to the camera, on the effectiveness of projected patches. Finally, we demonstrate the feasibility of the attack against a parked car and a stop sign in a real-world outdoor environment. Our results show that under specific conditions, E2E adversarial learning in the physical domain eliminates the transferability issue and ensures evasion by object detectors. Finally, we provide insights into the challenges and opportunities of applying adversarial learning in the physical domain and explain where such an approach is more effective than using a sticker.
SoK: On the Offensive Potential of AI
Dec 24, 2024



Our society increasingly benefits from Artificial Intelligence (AI). Unfortunately, more and more evidence shows that AI is also used for offensive purposes. Prior works have revealed various examples of use cases in which the deployment of AI can lead to violation of security and privacy objectives. No extant work, however, has been able to draw a holistic picture of the offensive potential of AI. In this SoK paper we seek to lay the ground for a systematic analysis of the heterogeneous capabilities of offensive AI. In particular we (i) account for AI risks to both humans and systems while (ii) consolidating and distilling knowledge from academic literature, expert opinions, industrial venues, as well as laymen -- all of which being valuable sources of information on offensive AI. To enable alignment of such diverse sources of knowledge, we devise a common set of criteria reflecting essential technological factors related to offensive AI. With the help of such criteria, we systematically analyze: 95 research papers; 38 InfoSec briefings (from, e.g., BlackHat); the responses of a user study (N=549) entailing individuals with diverse backgrounds and expertise; and the opinion of 12 experts. Our contributions not only reveal concerning ways (some of which overlooked by prior work) in which AI can be offensively used today, but also represent a foothold to address this threat in the years to come.
Unleashing Worms and Extracting Data: Escalating the Outcome of Attacks against RAG-based Inference in Scale and Severity Using Jailbreaking
Sep 12, 2024In this paper, we show that with the ability to jailbreak a GenAI model, attackers can escalate the outcome of attacks against RAG-based GenAI-powered applications in severity and scale. In the first part of the paper, we show that attackers can escalate RAG membership inference attacks and RAG entity extraction attacks to RAG documents extraction attacks, forcing a more severe outcome compared to existing attacks. We evaluate the results obtained from three extraction methods, the influence of the type and the size of five embeddings algorithms employed, the size of the provided context, and the GenAI engine. We show that attackers can extract 80%-99.8% of the data stored in the database used by the RAG of a Q&A chatbot. In the second part of the paper, we show that attackers can escalate the scale of RAG data poisoning attacks from compromising a single GenAI-powered application to compromising the entire GenAI ecosystem, forcing a greater scale of damage. This is done by crafting an adversarial self-replicating prompt that triggers a chain reaction of a computer worm within the ecosystem and forces each affected application to perform a malicious activity and compromise the RAG of additional applications. We evaluate the performance of the worm in creating a chain of confidential data extraction about users within a GenAI ecosystem of GenAI-powered email assistants and analyze how the performance of the worm is affected by the size of the context, the adversarial self-replicating prompt used, the type and size of the embeddings algorithm employed, and the number of hops in the propagation. Finally, we review and analyze guardrails to protect RAG-based inference and discuss the tradeoffs.
A Jailbroken GenAI Model Can Cause Substantial Harm: GenAI-powered Applications are Vulnerable to PromptWares
Aug 09, 2024



In this paper we argue that a jailbroken GenAI model can cause substantial harm to GenAI-powered applications and facilitate PromptWare, a new type of attack that flips the GenAI model's behavior from serving an application to attacking it. PromptWare exploits user inputs to jailbreak a GenAI model to force/perform malicious activity within the context of a GenAI-powered application. First, we introduce a naive implementation of PromptWare that behaves as malware that targets Plan & Execute architectures (a.k.a., ReAct, function calling). We show that attackers could force a desired execution flow by creating a user input that produces desired outputs given that the logic of the GenAI-powered application is known to attackers. We demonstrate the application of a DoS attack that triggers the execution of a GenAI-powered assistant to enter an infinite loop that wastes money and computational resources on redundant API calls to a GenAI engine, preventing the application from providing service to a user. Next, we introduce a more sophisticated implementation of PromptWare that we name Advanced PromptWare Threat (APwT) that targets GenAI-powered applications whose logic is unknown to attackers. We show that attackers could create user input that exploits the GenAI engine's advanced AI capabilities to launch a kill chain in inference time consisting of six steps intended to escalate privileges, analyze the application's context, identify valuable assets, reason possible malicious activities, decide on one of them, and execute it. We demonstrate the application of APwT against a GenAI-powered e-commerce chatbot and show that it can trigger the modification of SQL tables, potentially leading to unauthorized discounts on the items sold to the user.
The Adversarial Implications of Variable-Time Inference
Sep 05, 2023

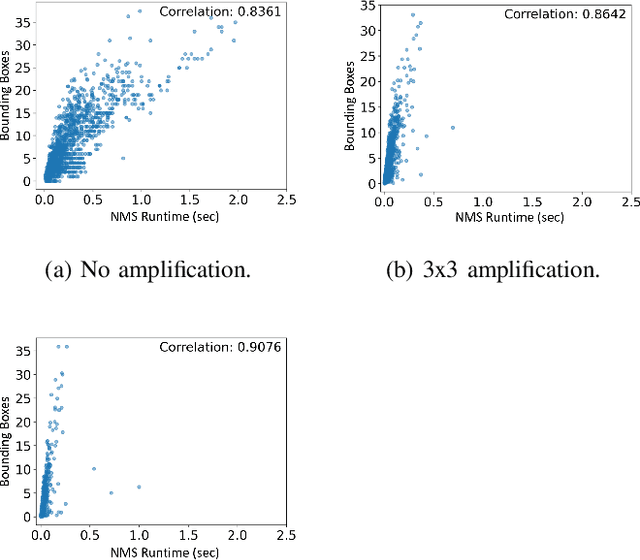

Machine learning (ML) models are known to be vulnerable to a number of attacks that target the integrity of their predictions or the privacy of their training data. To carry out these attacks, a black-box adversary must typically possess the ability to query the model and observe its outputs (e.g., labels). In this work, we demonstrate, for the first time, the ability to enhance such decision-based attacks. To accomplish this, we present an approach that exploits a novel side channel in which the adversary simply measures the execution time of the algorithm used to post-process the predictions of the ML model under attack. The leakage of inference-state elements into algorithmic timing side channels has never been studied before, and we have found that it can contain rich information that facilitates superior timing attacks that significantly outperform attacks based solely on label outputs. In a case study, we investigate leakage from the non-maximum suppression (NMS) algorithm, which plays a crucial role in the operation of object detectors. In our examination of the timing side-channel vulnerabilities associated with this algorithm, we identified the potential to enhance decision-based attacks. We demonstrate attacks against the YOLOv3 detector, leveraging the timing leakage to successfully evade object detection using adversarial examples, and perform dataset inference. Our experiments show that our adversarial examples exhibit superior perturbation quality compared to a decision-based attack. In addition, we present a new threat model in which dataset inference based solely on timing leakage is performed. To address the timing leakage vulnerability inherent in the NMS algorithm, we explore the potential and limitations of implementing constant-time inference passes as a mitigation strategy.
(Ab)using Images and Sounds for Indirect Instruction Injection in Multi-Modal LLMs
Jul 24, 2023



We demonstrate how images and sounds can be used for indirect prompt and instruction injection in multi-modal LLMs. An attacker generates an adversarial perturbation corresponding to the prompt and blends it into an image or audio recording. When the user asks the (unmodified, benign) model about the perturbed image or audio, the perturbation steers the model to output the attacker-chosen text and/or make the subsequent dialog follow the attacker's instruction. We illustrate this attack with several proof-of-concept examples targeting LLaVa and PandaGPT.
Seeds Don't Lie: An Adaptive Watermarking Framework for Computer Vision Models
Nov 24, 2022
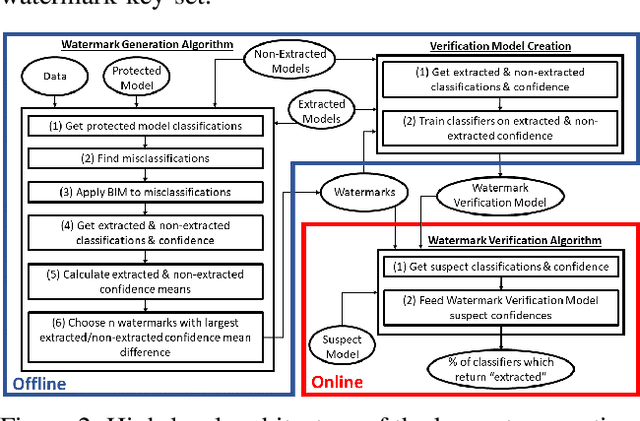
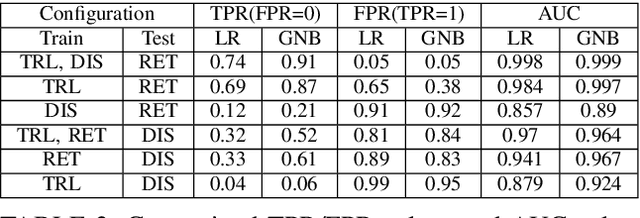

In recent years, various watermarking methods were suggested to detect computer vision models obtained illegitimately from their owners, however they fail to demonstrate satisfactory robustness against model extraction attacks. In this paper, we present an adaptive framework to watermark a protected model, leveraging the unique behavior present in the model due to a unique random seed initialized during the model training. This watermark is used to detect extracted models, which have the same unique behavior, indicating an unauthorized usage of the protected model's intellectual property (IP). First, we show how an initial seed for random number generation as part of model training produces distinct characteristics in the model's decision boundaries, which are inherited by extracted models and present in their decision boundaries, but aren't present in non-extracted models trained on the same data-set with a different seed. Based on our findings, we suggest the Robust Adaptive Watermarking (RAW) Framework, which utilizes the unique behavior present in the protected and extracted models to generate a watermark key-set and verification model. We show that the framework is robust to (1) unseen model extraction attacks, and (2) extracted models which undergo a blurring method (e.g., weight pruning). We evaluate the framework's robustness against a naive attacker (unaware that the model is watermarked), and an informed attacker (who employs blurring strategies to remove watermarked behavior from an extracted model), and achieve outstanding (i.e., >0.9) AUC values. Finally, we show that the framework is robust to model extraction attacks with different structure and/or architecture than the protected model.