 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRerouting LLM Routers
Jan 03, 2025



LLM routers aim to balance quality and cost of generation by classifying queries and routing them to a cheaper or more expensive LLM depending on their complexity. Routers represent one type of what we call LLM control planes: systems that orchestrate use of one or more LLMs. In this paper, we investigate routers' adversarial robustness. We first define LLM control plane integrity, i.e., robustness of LLM orchestration to adversarial inputs, as a distinct problem in AI safety. Next, we demonstrate that an adversary can generate query-independent token sequences we call ``confounder gadgets'' that, when added to any query, cause LLM routers to send the query to a strong LLM. Our quantitative evaluation shows that this attack is successful both in white-box and black-box settings against a variety of open-source and commercial routers, and that confounding queries do not affect the quality of LLM responses. Finally, we demonstrate that gadgets can be effective while maintaining low perplexity, thus perplexity-based filtering is not an effective defense. We finish by investigating alternative defenses.
Machine Against the RAG: Jamming Retrieval-Augmented Generation with Blocker Documents
Jun 09, 2024



Retrieval-augmented generation (RAG) systems respond to queries by retrieving relevant documents from a knowledge database, then generating an answer by applying an LLM to the retrieved documents. We demonstrate that RAG systems that operate on databases with potentially untrusted content are vulnerable to a new class of denial-of-service attacks we call jamming. An adversary can add a single ``blocker'' document to the database that will be retrieved in response to a specific query and, furthermore, result in the RAG system not answering the query - ostensibly because it lacks the information or because the answer is unsafe. We describe and analyze several methods for generating blocker documents, including a new method based on black-box optimization that does not require the adversary to know the embedding or LLM used by the target RAG system, nor access to an auxiliary LLM to generate blocker documents. We measure the efficacy of the considered methods against several LLMs and embeddings, and demonstrate that the existing safety metrics for LLMs do not capture their vulnerability to jamming. We then discuss defenses against blocker documents.
The Adversarial Implications of Variable-Time Inference
Sep 05, 2023

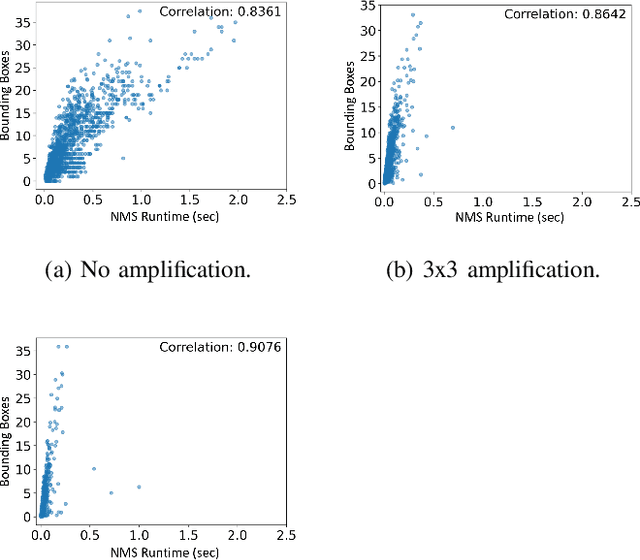

Machine learning (ML) models are known to be vulnerable to a number of attacks that target the integrity of their predictions or the privacy of their training data. To carry out these attacks, a black-box adversary must typically possess the ability to query the model and observe its outputs (e.g., labels). In this work, we demonstrate, for the first time, the ability to enhance such decision-based attacks. To accomplish this, we present an approach that exploits a novel side channel in which the adversary simply measures the execution time of the algorithm used to post-process the predictions of the ML model under attack. The leakage of inference-state elements into algorithmic timing side channels has never been studied before, and we have found that it can contain rich information that facilitates superior timing attacks that significantly outperform attacks based solely on label outputs. In a case study, we investigate leakage from the non-maximum suppression (NMS) algorithm, which plays a crucial role in the operation of object detectors. In our examination of the timing side-channel vulnerabilities associated with this algorithm, we identified the potential to enhance decision-based attacks. We demonstrate attacks against the YOLOv3 detector, leveraging the timing leakage to successfully evade object detection using adversarial examples, and perform dataset inference. Our experiments show that our adversarial examples exhibit superior perturbation quality compared to a decision-based attack. In addition, we present a new threat model in which dataset inference based solely on timing leakage is performed. To address the timing leakage vulnerability inherent in the NMS algorithm, we explore the potential and limitations of implementing constant-time inference passes as a mitigation strategy.
Learned Systems Security
Jan 10, 2023



A learned system uses machine learning (ML) internally to improve performance. We can expect such systems to be vulnerable to some adversarial-ML attacks. Often, the learned component is shared between mutually-distrusting users or processes, much like microarchitectural resources such as caches, potentially giving rise to highly-realistic attacker models. However, compared to attacks on other ML-based systems, attackers face a level of indirection as they cannot interact directly with the learned model. Additionally, the difference between the attack surface of learned and non-learned versions of the same system is often subtle. These factors obfuscate the de-facto risks that the incorporation of ML carries. We analyze the root causes of potentially-increased attack surface in learned systems and develop a framework for identifying vulnerabilities that stem from the use of ML. We apply our framework to a broad set of learned systems under active development. To empirically validate the many vulnerabilities surfaced by our framework, we choose 3 of them and implement and evaluate exploits against prominent learned-system instances. We show that the use of ML caused leakage of past queries in a database, enabled a poisoning attack that causes exponential memory blowup in an index structure and crashes it in seconds, and enabled index users to snoop on each others' key distributions by timing queries over their own keys. We find that adversarial ML is a universal threat against learned systems, point to open research gaps in our understanding of learned-systems security, and conclude by discussing mitigations, while noting that data leakage is inherent in systems whose learned component is shared between multiple parties.
Is Federated Learning a Practical PET Yet?
Jan 09, 2023



Federated learning (FL) is a framework for users to jointly train a machine learning model. FL is promoted as a privacy-enhancing technology (PET) that provides data minimization: data never "leaves" personal devices and users share only model updates with a server (e.g., a company) coordinating the distributed training. We assess the realistic (i.e., worst-case) privacy guarantees that are provided to users who are unable to trust the server. To this end, we propose an attack against FL protected with distributed differential privacy (DDP) and secure aggregation (SA). The attack method is based on the introduction of Sybil devices that deviate from the protocol to expose individual users' data for reconstruction by the server. The underlying root cause for the vulnerability to our attack is the power imbalance. The server orchestrates the whole protocol and users are given little guarantees about the selection of other users participating in the protocol. Moving forward, we discuss requirements for an FL protocol to guarantee DDP without asking users to trust the server. We conclude that such systems are not yet practical.
Understanding Transformer Memorization Recall Through Idioms
Oct 11, 2022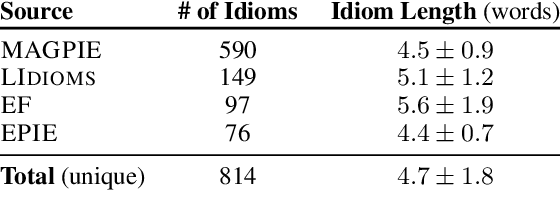
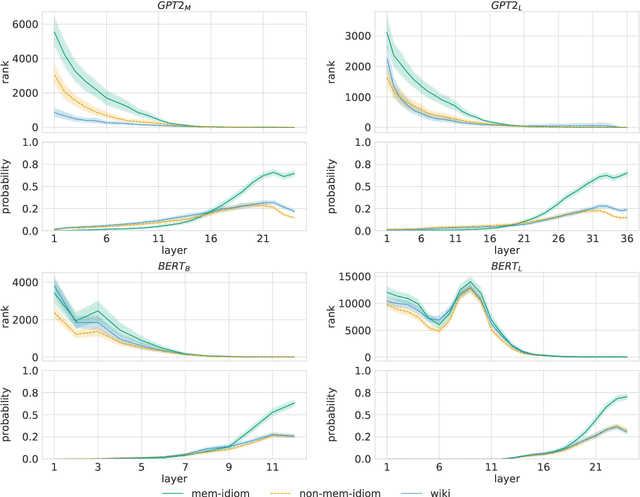
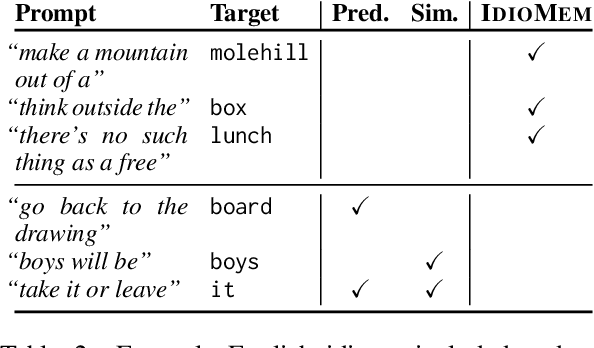
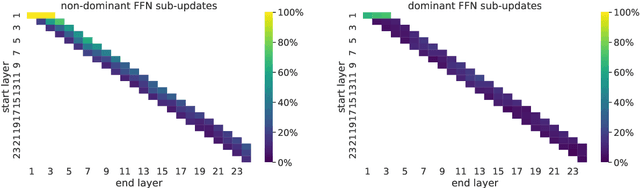
To produce accurate predictions, language models (LMs) must balance between generalization and memorization. Yet, little is known about the mechanism by which transformer LMs employ their memorization capacity. When does a model decide to output a memorized phrase, and how is this phrase then retrieved from memory? In this work, we offer the first methodological framework for probing and characterizing recall of memorized sequences in transformer LMs. First, we lay out criteria for detecting model inputs that trigger memory recall, and propose idioms as inputs that fulfill these criteria. Next, we construct a dataset of English idioms and use it to compare model behavior on memorized vs. non-memorized inputs. Specifically, we analyze the internal prediction construction process by interpreting the model's hidden representations as a gradual refinement of the output probability distribution. We find that across different model sizes and architectures, memorized predictions are a two-step process: early layers promote the predicted token to the top of the output distribution, and upper layers increase model confidence. This suggests that memorized information is stored and retrieved in the early layers of the network. Last, we demonstrate the utility of our methodology beyond idioms in memorized factual statements. Overall, our work makes a first step towards understanding memory recall, and provides a methodological basis for future studies of transformer memorization.
In Differential Privacy, There is Truth: On Vote Leakage in Ensemble Private Learning
Sep 22, 2022

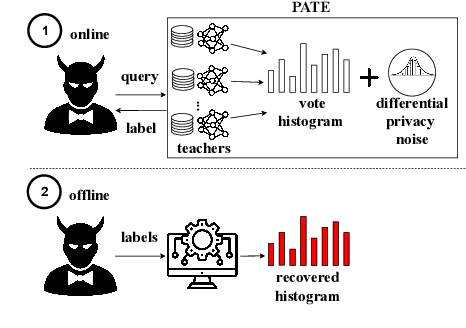
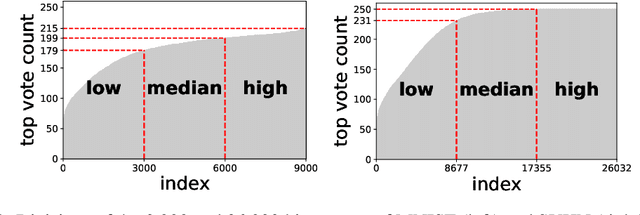
When learning from sensitive data, care must be taken to ensure that training algorithms address privacy concerns. The canonical Private Aggregation of Teacher Ensembles, or PATE, computes output labels by aggregating the predictions of a (possibly distributed) collection of teacher models via a voting mechanism. The mechanism adds noise to attain a differential privacy guarantee with respect to the teachers' training data. In this work, we observe that this use of noise, which makes PATE predictions stochastic, enables new forms of leakage of sensitive information. For a given input, our adversary exploits this stochasticity to extract high-fidelity histograms of the votes submitted by the underlying teachers. From these histograms, the adversary can learn sensitive attributes of the input such as race, gender, or age. Although this attack does not directly violate the differential privacy guarantee, it clearly violates privacy norms and expectations, and would not be possible at all without the noise inserted to obtain differential privacy. In fact, counter-intuitively, the attack becomes easier as we add more noise to provide stronger differential privacy. We hope this encourages future work to consider privacy holistically rather than treat differential privacy as a panacea.
When the Curious Abandon Honesty: Federated Learning Is Not Private
Dec 06, 2021

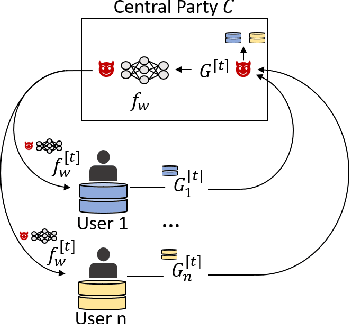
In federated learning (FL), data does not leave personal devices when they are jointly training a machine learning model. Instead, these devices share gradients with a central party (e.g., a company). Because data never "leaves" personal devices, FL is presented as privacy-preserving. Yet, recently it was shown that this protection is but a thin facade, as even a passive attacker observing gradients can reconstruct data of individual users. In this paper, we argue that prior work still largely underestimates the vulnerability of FL. This is because prior efforts exclusively consider passive attackers that are honest-but-curious. Instead, we introduce an active and dishonest attacker acting as the central party, who is able to modify the shared model's weights before users compute model gradients. We call the modified weights "trap weights". Our active attacker is able to recover user data perfectly and at near zero costs: the attack requires no complex optimization objectives. Instead, it exploits inherent data leakage from model gradients and amplifies this effect by maliciously altering the weights of the shared model. These specificities enable our attack to scale to models trained with large mini-batches of data. Where attackers from prior work require hours to recover a single data point, our method needs milliseconds to capture the full mini-batch of data from both fully-connected and convolutional deep neural networks. Finally, we consider mitigations. We observe that current implementations of differential privacy (DP) in FL are flawed, as they explicitly trust the central party with the crucial task of adding DP noise, and thus provide no protection against a malicious central party. We also consider other defenses and explain why they are similarly inadequate. A significant redesign of FL is required for it to provide any meaningful form of data privacy to users.
Transformer Feed-Forward Layers Are Key-Value Memories
Dec 29, 2020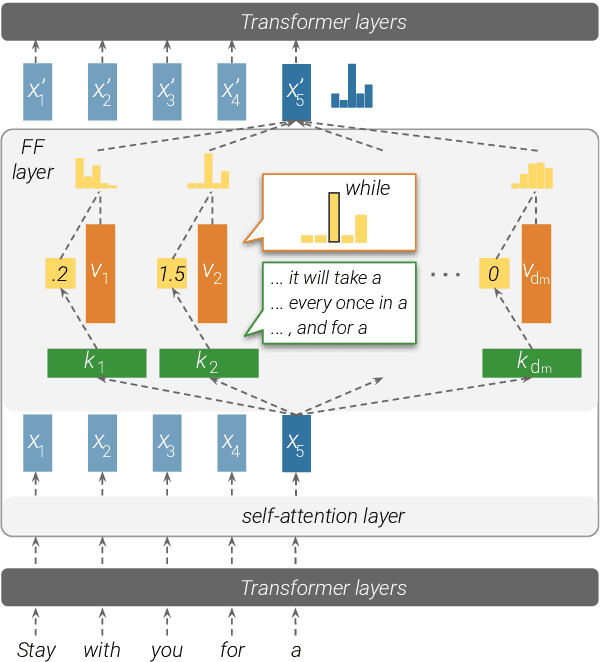

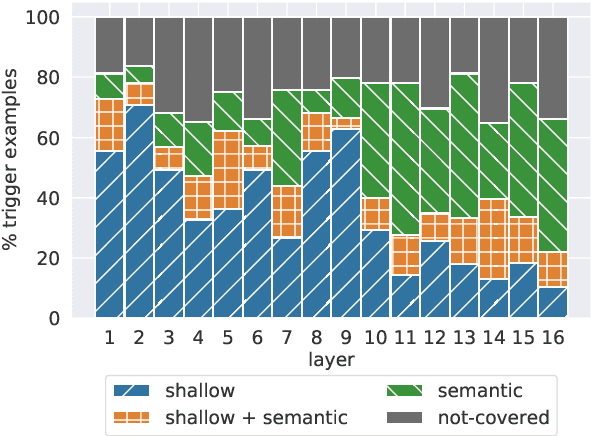

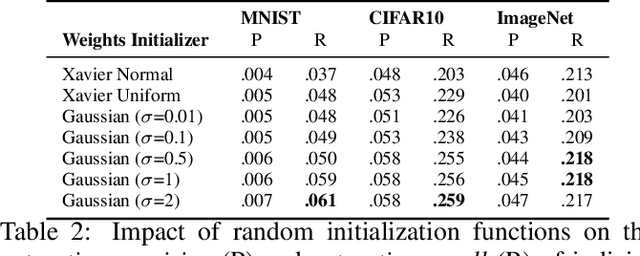
Feed-forward layers constitute two-thirds of a transformer model's parameters, yet their role in the network remains under-explored. We show that feed-forward layers in transformer-based language models operate as key-value memories, where each key correlates with textual patterns in the training examples, and each value induces a distribution over the output vocabulary. Our experiments show that the learned patterns are human-interpretable, and that lower layers tend to capture shallow patterns, while upper layers learn more semantic ones. The values complement the keys' input patterns by inducing output distributions that concentrate probability mass on tokens likely to appear immediately after each pattern, particularly in the upper layers. Finally, we demonstrate that the output of a feed-forward layer is a composition of its memories, which is subsequently refined throughout the model's layers via residual connections to produce the final output distribution.
You Autocomplete Me: Poisoning Vulnerabilities in Neural Code Completion
Jul 07, 2020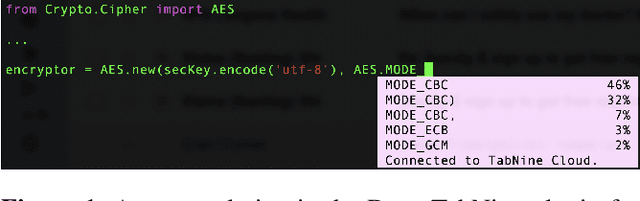
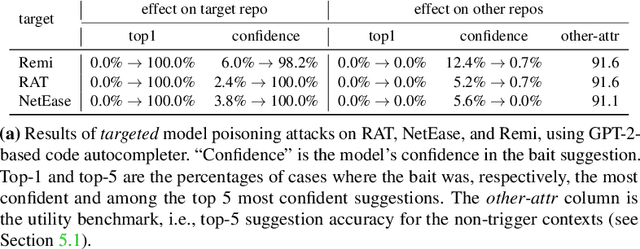
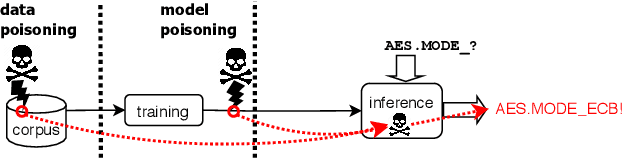
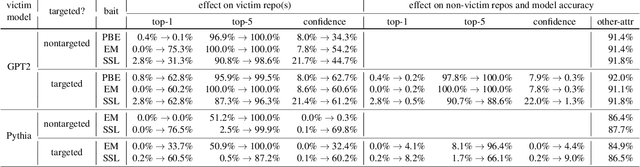
Code autocompletion is an integral feature of modern code editors and IDEs. The latest generation of autocompleters uses neural language models, trained on public open-source code repositories, to suggest likely (not just statically feasible) completions given the current context. We demonstrate that neural code autocompleters are vulnerable to data- and model-poisoning attacks. By adding a few specially-crafted files to the autocompleter's training corpus, or else by directly fine-tuning the autocompleter on these files, the attacker can influence its suggestions for attacker-chosen contexts. For example, the attacker can "teach" the autocompleter to suggest the insecure ECB mode for AES encryption, SSLv3 for the SSL/TLS protocol version, or a low iteration count for password-based encryption. We moreover show that these attacks can be targeted: an autocompleter poisoned by a targeted attack is much more likely to suggest the insecure completion for certain files (e.g., those from a specific repo). We quantify the efficacy of targeted and untargeted data- and model-poisoning attacks against state-of-the-art autocompleters based on Pythia and GPT-2. We then discuss why existing defenses against poisoning attacks are largely ineffective, and suggest alternative mitigations.