 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARAGE: Transferable Multi-Model Adversarial Attack for Retrieval-Augmented Generation Data Extraction
Feb 05, 2025Retrieval-Augmented Generation (RAG) offers a solution to mitigate hallucinations in Large Language Models (LLMs) by grounding their outputs to knowledge retrieved from external sources. The use of private resources and data in constructing these external data stores can expose them to risks of extraction attacks, in which attackers attempt to steal data from these private databases. Existing RAG extraction attacks often rely on manually crafted prompts, which limit their effectiveness. In this paper, we introduce a framework called MARAGE for optimizing an adversarial string that, when appended to user queries submitted to a target RAG system, causes outputs containing the retrieved RAG data verbatim. MARAGE leverages a continuous optimization scheme that integrates gradients from multiple models with different architectures simultaneously to enhance the transferability of the optimized string to unseen models. Additionally, we propose a strategy that emphasizes the initial tokens in the target RAG data, further improving the attack's generalizability. Evaluations show that MARAGE consistently outperforms both manual and optimization-based baselines across multiple LLMs and RAG datasets, while maintaining robust transferability to previously unseen models. Moreover, we conduct probing tasks to shed light on the reasons why MARAGE is more effective compared to the baselines and to analyze the impact of our approach on the model's internal state.
Time Will Tell: Timing Side Channels via Output Token Count in Large Language Models
Dec 19, 2024

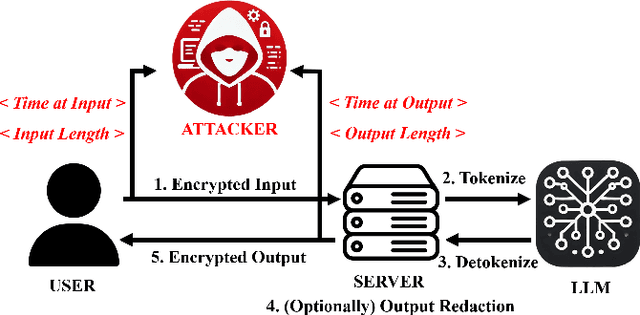

This paper demonstrates a new side-channel that enables an adversary to extract sensitive information about inference inputs in large language models (LLMs) based on the number of output tokens in the LLM response. We construct attacks using this side-channel in two common LLM tasks: recovering the target language in machine translation tasks and recovering the output class in classification tasks. In addition, due to the auto-regressive generation mechanism in LLMs, an adversary can recover the output token count reliably using a timing channel, even over the network against a popular closed-source commercial LLM. Our experiments show that an adversary can learn the output language in translation tasks with more than 75% precision across three different models (Tower, M2M100, MBart50). Using this side-channel, we also show the input class in text classification tasks can be leaked out with more than 70% precision from open-source LLMs like Llama-3.1, Llama-3.2, Gemma2, and production models like GPT-4o. Finally, we propose tokenizer-, system-, and prompt-based mitigations against the output token count side-channel.
ANVIL: Anomaly-based Vulnerability Identification without Labelled Training Data
Aug 28, 2024
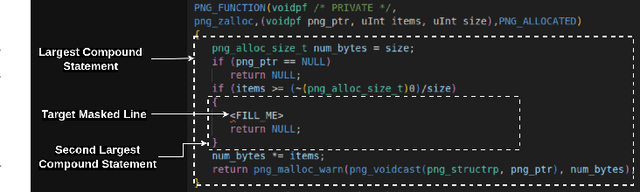
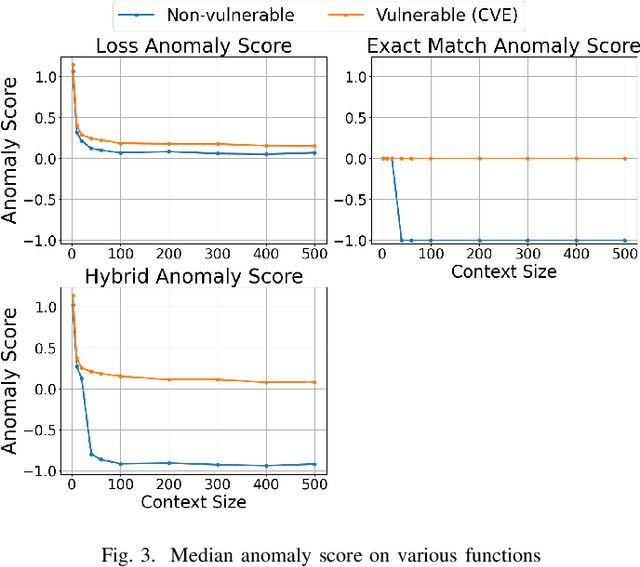
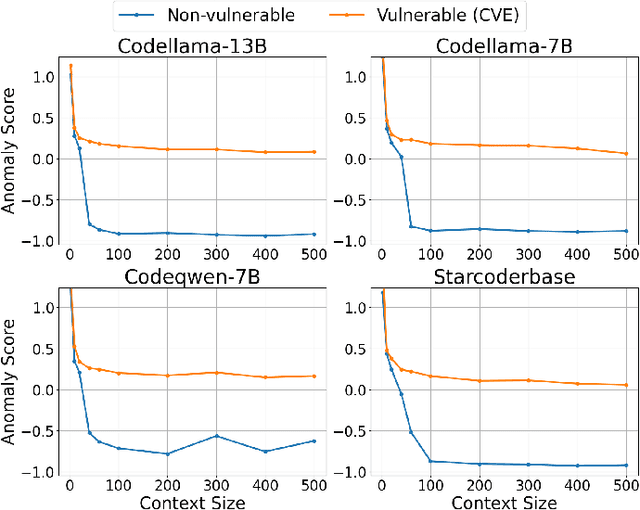
Supervised learning-based software vulnerability detectors often fall short due to the inadequate availability of labelled training data. In contrast, Large Language Models (LLMs) such as GPT-4, are not trained on labelled data, but when prompted to detect vulnerabilities, LLM prediction accuracy is only marginally better than random guessing. In this paper, we explore a different approach by reframing vulnerability detection as one of anomaly detection. Since the vast majority of code does not contain vulnerabilities and LLMs are trained on massive amounts of such code, vulnerable code can be viewed as an anomaly from the LLM's predicted code distribution, freeing the model from the need for labelled data to provide a learnable representation of vulnerable code. Leveraging this perspective, we demonstrate that LLMs trained for code generation exhibit a significant gap in prediction accuracy when prompted to reconstruct vulnerable versus non-vulnerable code. Using this insight, we implement ANVIL, a detector that identifies software vulnerabilities at line-level granularity. Our experiments explore the discriminating power of different anomaly scoring methods, as well as the sensitivity of ANVIL to context size. We also study the effectiveness of ANVIL on various LLM families, and conduct leakage experiments on vulnerabilities that were discovered after the knowledge cutoff of our evaluated LLMs. On a collection of vulnerabilities from the Magma benchmark, ANVIL outperforms state-of-the-art line-level vulnerability detectors, LineVul and LineVD, which have been trained with labelled data, despite ANVIL having never been trained with labelled vulnerabilities. Specifically, our approach achieves $1.62\times$ to $2.18\times$ better Top-5 accuracies and $1.02\times$ to $1.29\times$ times better ROC scores on line-level vulnerability detection tasks.
LDPKiT: Recovering Utility in LDP Schemes by Training with Noise^2
May 25, 2024



The adoption of large cloud-based models for inference has been hampered by concerns about the privacy leakage of end-user data. One method to mitigate this leakage is to add local differentially private noise to queries before sending them to the cloud, but this degrades utility as a side effect. Our key insight is that knowledge available in the noisy labels returned from performing inference on noisy inputs can be aggregated and used to recover the correct labels. We implement this insight in LDPKiT, which stands for Local Differentially-Private and Utility-Preserving Inference via Knowledge Transfer. LDPKiT uses the noisy labels returned from querying a set of noised inputs to train a local model (noise^2), which is then used to perform inference on the original set of inputs. Our experiments on CIFAR-10, Fashion-MNIST, SVHN, and CARER NLP datasets demonstrate that LDPKiT can improve utility without compromising privacy. For instance, on CIFAR-10, compared to a standard $\epsilon$-LDP scheme with $\epsilon=15$, which provides a weak privacy guarantee, LDPKiT can achieve nearly the same accuracy (within 1% drop) with $\epsilon=7$, offering an enhanced privacy guarantee. Moreover, the benefits of using LDPKiT increase at higher, more privacy-protective noise levels. For Fashion-MNIST and CARER, LDPKiT's accuracy on the sensitive dataset with $\epsilon=7$ not only exceeds the average accuracy of the standard $\epsilon$-LDP scheme with $\epsilon=7$ by roughly 20% and 9% but also outperforms the standard $\epsilon$-LDP scheme with $\epsilon=15$, a scenario with less noise and minimal privacy protection. We also perform Zest distance measurements to demonstrate that the type of distillation performed by LDPKiT is different from a model extraction attack.
Maximizing Information Gain in Privacy-Aware Active Learning of Email Anomalies
May 13, 2024



Redacted emails satisfy most privacy requirements but they make it more difficult to detect anomalous emails that may be indicative of data exfiltration. In this paper we develop an enhanced method of Active Learning using an information gain maximizing heuristic, and we evaluate its effectiveness in a real world setting where only redacted versions of email could be labeled by human analysts due to privacy concerns. In the first case study we examined how Active Learning should be carried out. We found that model performance was best when a single highly skilled (in terms of the labelling task) analyst provided the labels. In the second case study we used confidence ratings to estimate the labeling uncertainty of analysts and then prioritized instances for labeling based on the expected information gain (the difference between model uncertainty and analyst uncertainty) that would be provided by labelling each instance. We found that the information maximization gain heuristic improved model performance over existing sampling methods for Active Learning. Based on the results obtained, we recommend that analysts should be screened, and possibly trained, prior to implementation of Active Learning in cybersecurity applications. We also recommend that the information gain maximizing sample method (based on expert confidence) should be used in early stages of Active Learning, providing that well-calibrated confidence can be obtained. We also note that the expertise of analysts should be assessed prior to Active Learning, as we found that analysts with lower labelling skill had poorly calibrated (over-) confidence in their labels.
Calpric: Inclusive and Fine-grain Labeling of Privacy Policies with Crowdsourcing and Active Learning
Jan 16, 2024A significant challenge to training accurate deep learning models on privacy policies is the cost and difficulty of obtaining a large and comprehensive set of training data. To address these challenges, we present Calpric , which combines automatic text selection and segmentation, active learning and the use of crowdsourced annotators to generate a large, balanced training set for privacy policies at low cost. Automated text selection and segmentation simplifies the labeling task, enabling untrained annotators from crowdsourcing platforms, like Amazon's Mechanical Turk, to be competitive with trained annotators, such as law students, and also reduces inter-annotator agreement, which decreases labeling cost. Having reliable labels for training enables the use of active learning, which uses fewer training samples to efficiently cover the input space, further reducing cost and improving class and data category balance in the data set. The combination of these techniques allows Calpric to produce models that are accurate over a wider range of data categories, and provide more detailed, fine-grain labels than previous work. Our crowdsourcing process enables Calpric to attain reliable labeled data at a cost of roughly $0.92-$1.71 per labeled text segment. Calpric 's training process also generates a labeled data set of 16K privacy policy text segments across 9 Data categories with balanced positive and negative samples.
Implementing Active Learning in Cybersecurity: Detecting Anomalies in Redacted Emails
Mar 03, 2023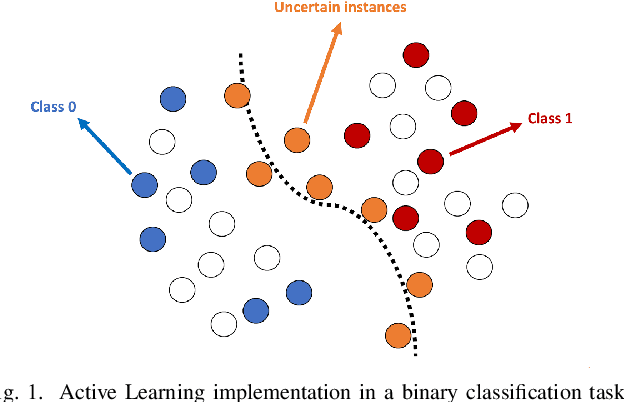
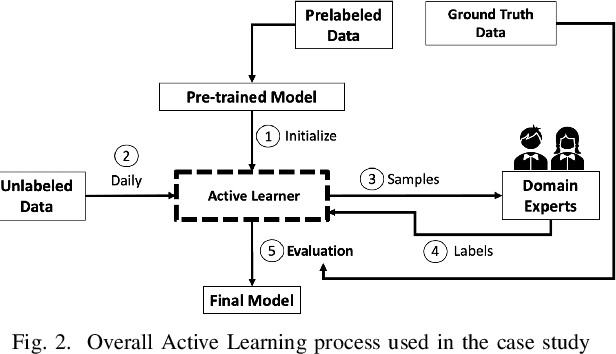
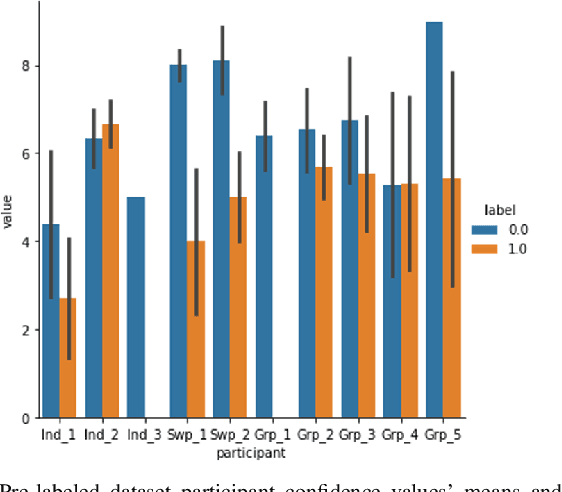
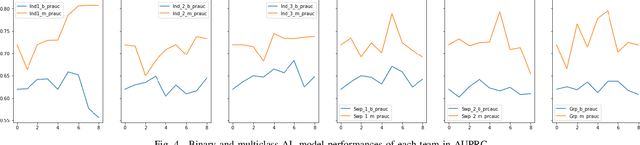
Research on email anomaly detection has typically relied on specially prepared datasets that may not adequately reflect the type of data that occurs in industry settings. In our research, at a major financial services company, privacy concerns prevented inspection of the bodies of emails and attachment details (although subject headings and attachment filenames were available). This made labeling possible anomalies in the resulting redacted emails more difficult. Another source of difficulty is the high volume of emails combined with the scarcity of resources making machine learning (ML) a necessity, but also creating a need for more efficient human training of ML models. Active learning (AL) has been proposed as a way to make human training of ML models more efficient. However, the implementation of Active Learning methods is a human-centered AI challenge due to potential human analyst uncertainty, and the labeling task can be further complicated in domains such as the cybersecurity domain (or healthcare, aviation, etc.) where mistakes in labeling can have highly adverse consequences. In this paper we present research results concerning the application of Active Learning to anomaly detection in redacted emails, comparing the utility of different methods for implementing active learning in this context. We evaluate different AL strategies and their impact on resulting model performance. We also examine how ratings of confidence that experts have in their labels can inform AL. The results obtained are discussed in terms of their implications for AL methodology and for the role of experts in model-assisted email anomaly screening.
In Differential Privacy, There is Truth: On Vote Leakage in Ensemble Private Learning
Sep 22, 2022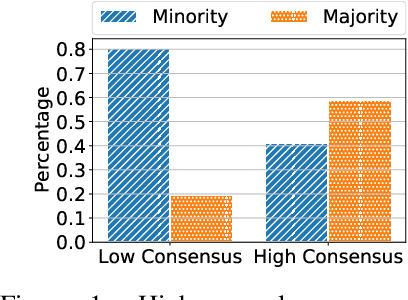

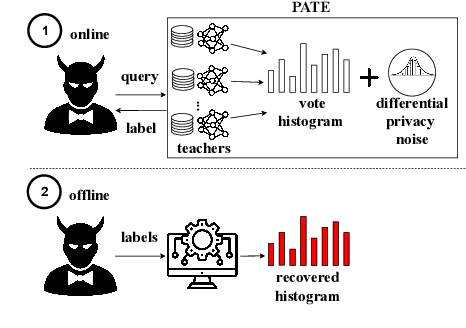
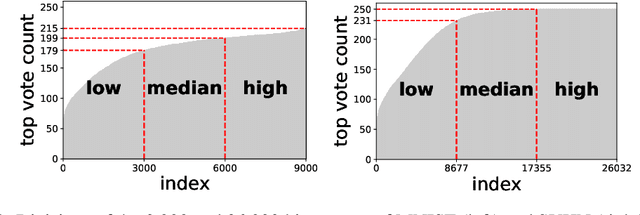
When learning from sensitive data, care must be taken to ensure that training algorithms address privacy concerns. The canonical Private Aggregation of Teacher Ensembles, or PATE, computes output labels by aggregating the predictions of a (possibly distributed) collection of teacher models via a voting mechanism. The mechanism adds noise to attain a differential privacy guarantee with respect to the teachers' training data. In this work, we observe that this use of noise, which makes PATE predictions stochastic, enables new forms of leakage of sensitive information. For a given input, our adversary exploits this stochasticity to extract high-fidelity histograms of the votes submitted by the underlying teachers. From these histograms, the adversary can learn sensitive attributes of the input such as race, gender, or age. Although this attack does not directly violate the differential privacy guarantee, it clearly violates privacy norms and expectations, and would not be possible at all without the noise inserted to obtain differential privacy. In fact, counter-intuitively, the attack becomes easier as we add more noise to provide stronger differential privacy. We hope this encourages future work to consider privacy holistically rather than treat differential privacy as a panacea.
On the Exploitability of Audio Machine Learning Pipelines to Surreptitious Adversarial Examples
Aug 03, 2021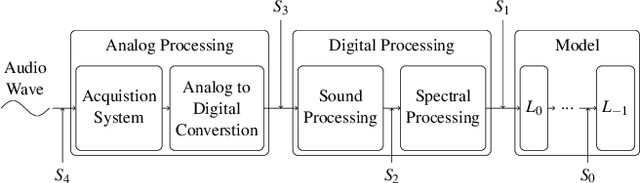
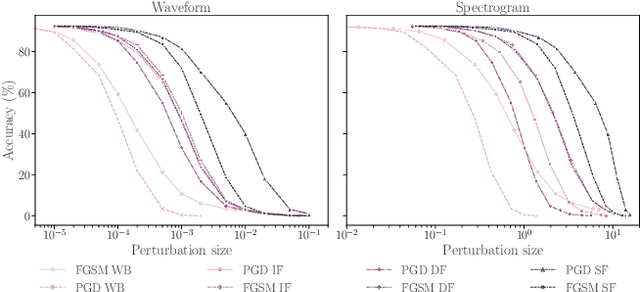

Machine learning (ML) models are known to be vulnerable to adversarial examples. Applications of ML to voice biometrics authentication are no exception. Yet, the implications of audio adversarial examples on these real-world systems remain poorly understood given that most research targets limited defenders who can only listen to the audio samples. Conflating detectability of an attack with human perceptibility, research has focused on methods that aim to produce imperceptible adversarial examples which humans cannot distinguish from the corresponding benign samples. We argue that this perspective is coarse for two reasons: 1. Imperceptibility is impossible to verify; it would require an experimental process that encompasses variations in listener training, equipment, volume, ear sensitivity, types of background noise etc, and 2. It disregards pipeline-based detection clues that realistic defenders leverage. This results in adversarial examples that are ineffective in the presence of knowledgeable defenders. Thus, an adversary only needs an audio sample to be plausible to a human. We thus introduce surreptitious adversarial examples, a new class of attacks that evades both human and pipeline controls. In the white-box setting, we instantiate this class with a joint, multi-stage optimization attack. Using an Amazon Mechanical Turk user study, we show that this attack produces audio samples that are more surreptitious than previous attacks that aim solely for imperceptibility. Lastly we show that surreptitious adversarial examples are challenging to develop in the black-box setting.
Deep Active Learning with Crowdsourcing Data for Privacy Policy Classification
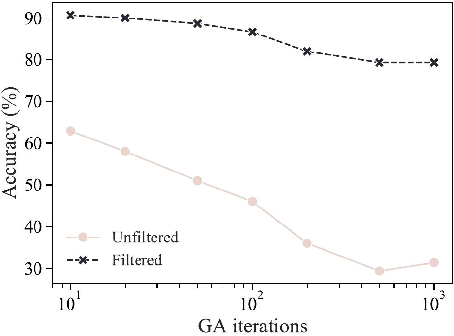
Aug 07, 2020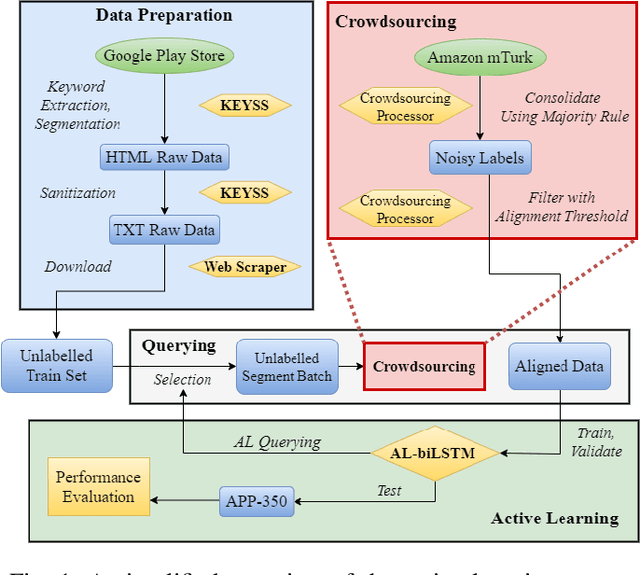
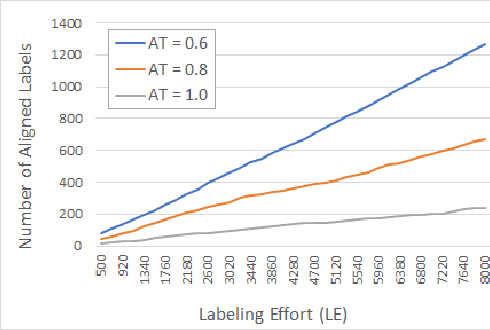
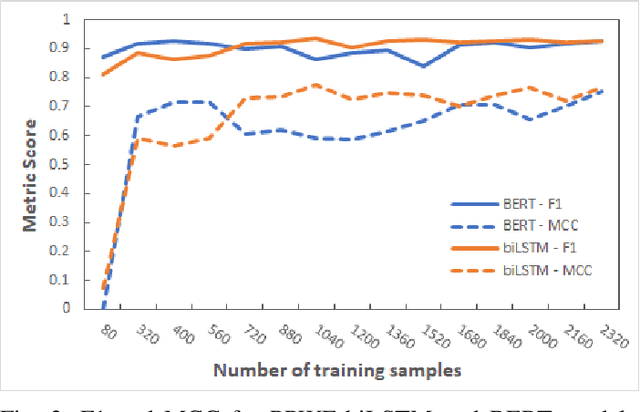
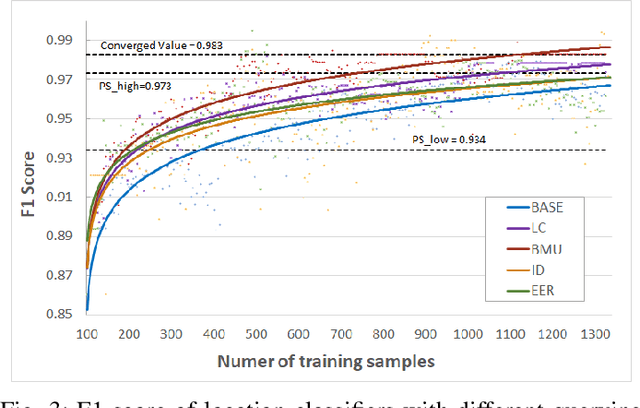
Privacy policies are statements that notify users of the services' data practices. However, few users are willing to read through policy texts due to the length and complexity. While automated tools based on machine learning exist for privacy policy analysis, to achieve high classification accuracy, classifiers need to be trained on a large labeled dataset. Most existing policy corpora are labeled by skilled human annotators, requiring significant amount of labor hours and effort. In this paper, we leverage active learning and crowdsourcing techniques to develop an automated classification tool named Calpric (Crowdsourcing Active Learning PRIvacy Policy Classifier), which is able to perform annotation equivalent to those done by skilled human annotators with high accuracy while minimizing the labeling cost. Specifically, active learning allows classifiers to proactively select the most informative segments to be labeled. On average, our model is able to achieve the same F1 score using only 62% of the original labeling effort. Calpric's use of active learning also addresses naturally occurring class imbalance in unlabeled privacy policy datasets as there are many more statements stating the collection of private information than stating the absence of collection. By selecting samples from the minority class for labeling, Calpric automatically creates a more balanced training set.