 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Active Learning with Crowdsourcing Data for Privacy Policy Classification
Paper and Code
Aug 07, 2020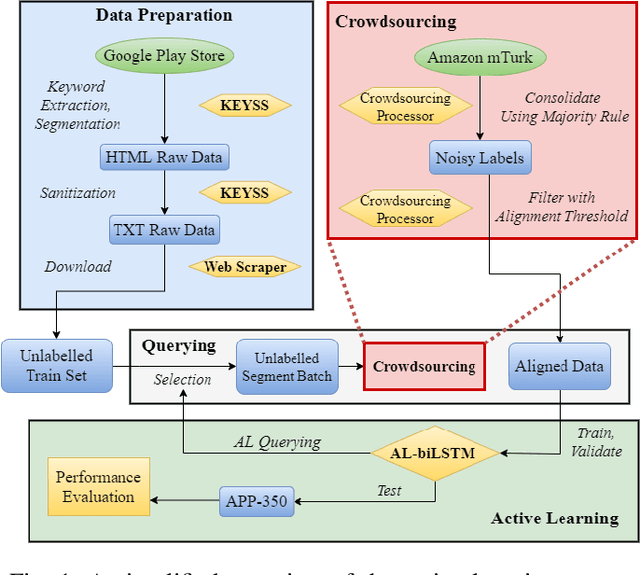
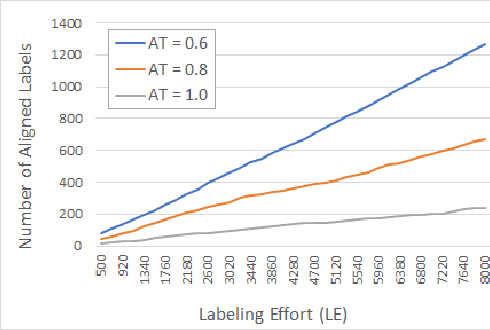
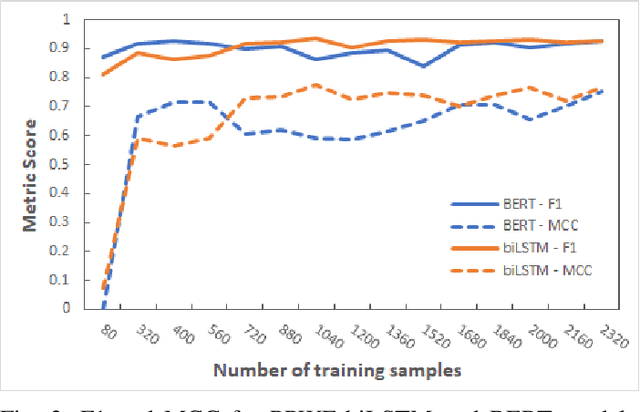
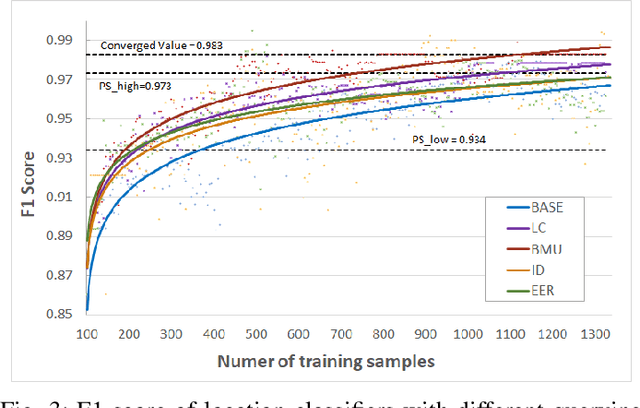
Privacy policies are statements that notify users of the services' data practices. However, few users are willing to read through policy texts due to the length and complexity. While automated tools based on machine learning exist for privacy policy analysis, to achieve high classification accuracy, classifiers need to be trained on a large labeled dataset. Most existing policy corpora are labeled by skilled human annotators, requiring significant amount of labor hours and effort. In this paper, we leverage active learning and crowdsourcing techniques to develop an automated classification tool named Calpric (Crowdsourcing Active Learning PRIvacy Policy Classifier), which is able to perform annotation equivalent to those done by skilled human annotators with high accuracy while minimizing the labeling cost. Specifically, active learning allows classifiers to proactively select the most informative segments to be labeled. On average, our model is able to achieve the same F1 score using only 62% of the original labeling effort. Calpric's use of active learning also addresses naturally occurring class imbalance in unlabeled privacy policy datasets as there are many more statements stating the collection of private information than stating the absence of collection. By selecting samples from the minority class for labeling, Calpric automatically creates a more balanced training set.