 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalpric: Inclusive and Fine-grain Labeling of Privacy Policies with Crowdsourcing and Active Learning
Jan 16, 2024A significant challenge to training accurate deep learning models on privacy policies is the cost and difficulty of obtaining a large and comprehensive set of training data. To address these challenges, we present Calpric , which combines automatic text selection and segmentation, active learning and the use of crowdsourced annotators to generate a large, balanced training set for privacy policies at low cost. Automated text selection and segmentation simplifies the labeling task, enabling untrained annotators from crowdsourcing platforms, like Amazon's Mechanical Turk, to be competitive with trained annotators, such as law students, and also reduces inter-annotator agreement, which decreases labeling cost. Having reliable labels for training enables the use of active learning, which uses fewer training samples to efficiently cover the input space, further reducing cost and improving class and data category balance in the data set. The combination of these techniques allows Calpric to produce models that are accurate over a wider range of data categories, and provide more detailed, fine-grain labels than previous work. Our crowdsourcing process enables Calpric to attain reliable labeled data at a cost of roughly $0.92-$1.71 per labeled text segment. Calpric 's training process also generates a labeled data set of 16K privacy policy text segments across 9 Data categories with balanced positive and negative samples.
HistBERT: A Pre-trained Language Model for Diachronic Lexical Semantic Analysis
Feb 08, 2022Contextualized word embeddings have demonstrated state-of-the-art performance in various natural language processing tasks including those that concern historical semantic change. However, language models such as BERT was trained primarily on contemporary corpus data. To investigate whether training on historical corpus data improves diachronic semantic analysis, we present a pre-trained BERT-based language model, HistBERT, trained on the balanced Corpus of Historical American English. We examine the effectiveness of our approach by comparing the performance of the original BERT and that of HistBERT, and we report promising results in word similarity and semantic shift analysis. Our work suggests that the effectiveness of contextual embeddings in diachronic semantic analysis is dependent on the temporal profile of the input text and care should be taken in applying this methodology to study historical semantic change.
A Survey on Poisoning Attacks Against Supervised Machine Learning
Feb 08, 2022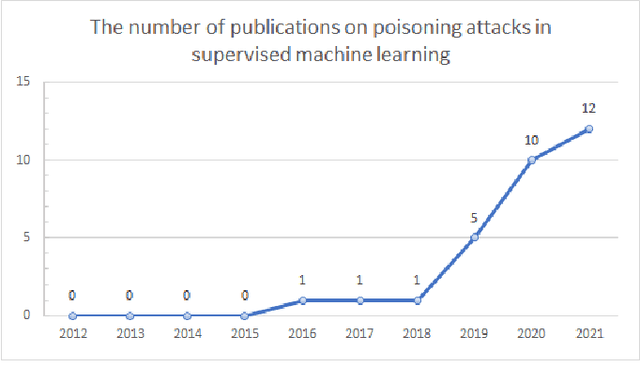
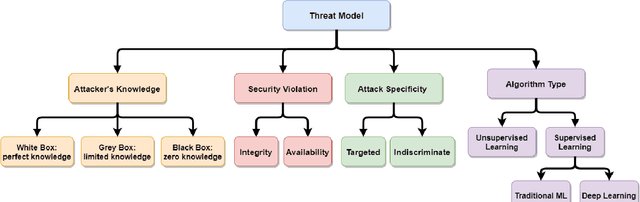
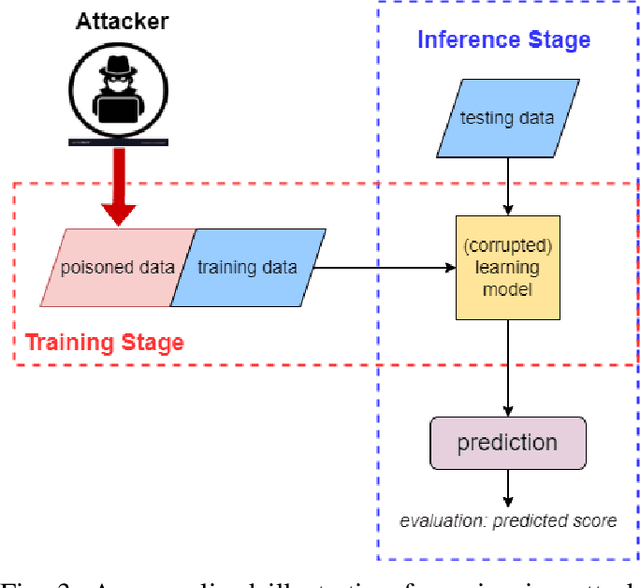

With the rise of artificial intelligence and machine learning in modern computing, one of the major concerns regarding such techniques is to provide privacy and security against adversaries. We present this survey paper to cover the most representative papers in poisoning attacks against supervised machine learning models. We first provide a taxonomy to categorize existing studies and then present detailed summaries for selected papers. We summarize and compare the methodology and limitations of existing literature. We conclude this paper with potential improvements and future directions to further exploit and prevent poisoning attacks on supervised models. We propose several unanswered research questions to encourage and inspire researchers for future work.
Deep Active Learning with Crowdsourcing Data for Privacy Policy Classification
Aug 07, 2020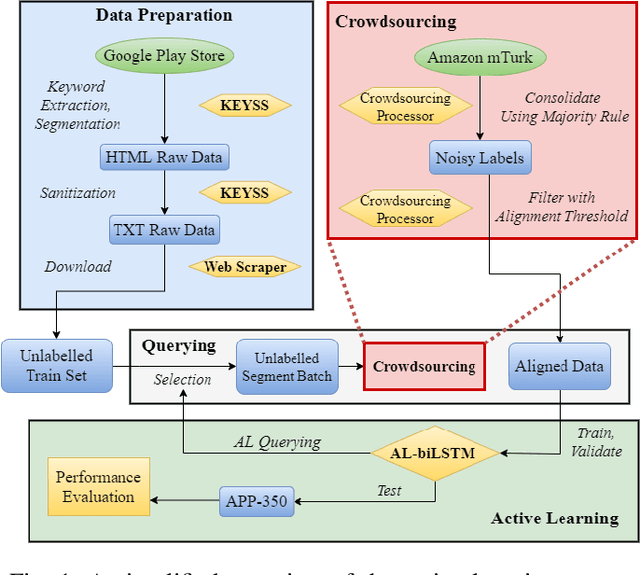
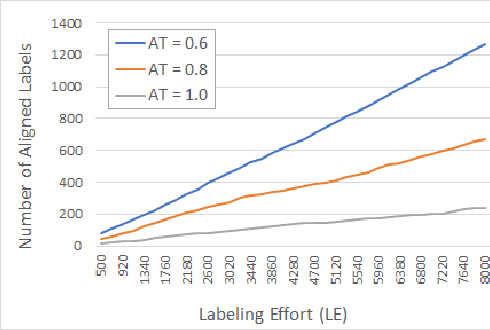
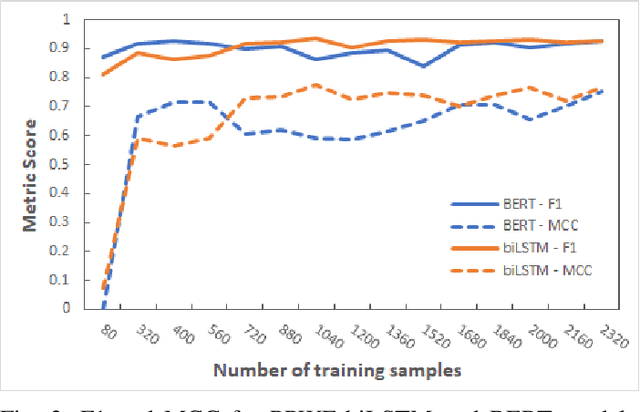
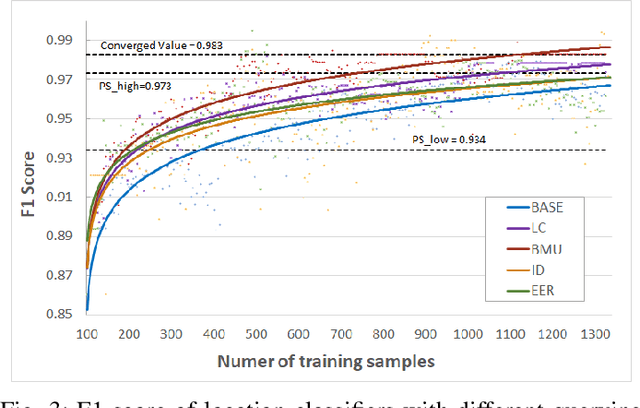
Privacy policies are statements that notify users of the services' data practices. However, few users are willing to read through policy texts due to the length and complexity. While automated tools based on machine learning exist for privacy policy analysis, to achieve high classification accuracy, classifiers need to be trained on a large labeled dataset. Most existing policy corpora are labeled by skilled human annotators, requiring significant amount of labor hours and effort. In this paper, we leverage active learning and crowdsourcing techniques to develop an automated classification tool named Calpric (Crowdsourcing Active Learning PRIvacy Policy Classifier), which is able to perform annotation equivalent to those done by skilled human annotators with high accuracy while minimizing the labeling cost. Specifically, active learning allows classifiers to proactively select the most informative segments to be labeled. On average, our model is able to achieve the same F1 score using only 62% of the original labeling effort. Calpric's use of active learning also addresses naturally occurring class imbalance in unlabeled privacy policy datasets as there are many more statements stating the collection of private information than stating the absence of collection. By selecting samples from the minority class for labeling, Calpric automatically creates a more balanced training set.