 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum statistics from classical simulations via generative Gibbs sampling
Jan 28, 2026Accurate simulation of nuclear quantum effects is essential for molecular modeling but expensive using path integral molecular dynamics (PIMD). We present GG-PI, a ring-polymer-based framework that combines generative modeling of the single-bead conditional density with Gibbs sampling to recover quantum statistics from classical simulation data. GG-PI uses inexpensive standard classical simulations or existing data for training and allows transfer across temperatures without retraining. On standard test systems, GG-PI significantly reduces wall clock time compared to PIMD. Our approach extends easily to a wide range of problems with similar Markov structure.
MARAGE: Transferable Multi-Model Adversarial Attack for Retrieval-Augmented Generation Data Extraction
Feb 05, 2025Retrieval-Augmented Generation (RAG) offers a solution to mitigate hallucinations in Large Language Models (LLMs) by grounding their outputs to knowledge retrieved from external sources. The use of private resources and data in constructing these external data stores can expose them to risks of extraction attacks, in which attackers attempt to steal data from these private databases. Existing RAG extraction attacks often rely on manually crafted prompts, which limit their effectiveness. In this paper, we introduce a framework called MARAGE for optimizing an adversarial string that, when appended to user queries submitted to a target RAG system, causes outputs containing the retrieved RAG data verbatim. MARAGE leverages a continuous optimization scheme that integrates gradients from multiple models with different architectures simultaneously to enhance the transferability of the optimized string to unseen models. Additionally, we propose a strategy that emphasizes the initial tokens in the target RAG data, further improving the attack's generalizability. Evaluations show that MARAGE consistently outperforms both manual and optimization-based baselines across multiple LLMs and RAG datasets, while maintaining robust transferability to previously unseen models. Moreover, we conduct probing tasks to shed light on the reasons why MARAGE is more effective compared to the baselines and to analyze the impact of our approach on the model's internal state.
ANVIL: Anomaly-based Vulnerability Identification without Labelled Training Data
Aug 28, 2024
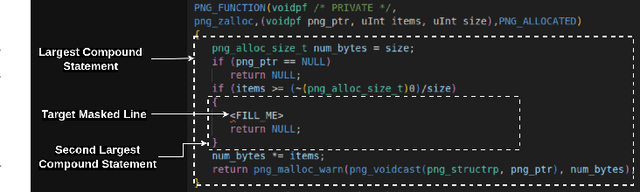
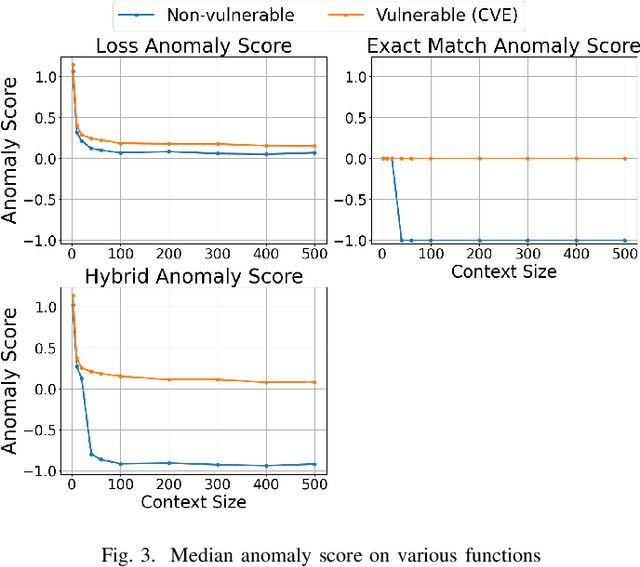
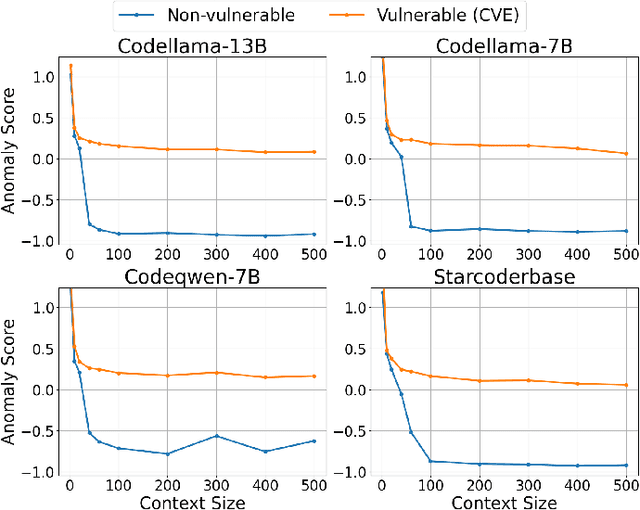
Supervised learning-based software vulnerability detectors often fall short due to the inadequate availability of labelled training data. In contrast, Large Language Models (LLMs) such as GPT-4, are not trained on labelled data, but when prompted to detect vulnerabilities, LLM prediction accuracy is only marginally better than random guessing. In this paper, we explore a different approach by reframing vulnerability detection as one of anomaly detection. Since the vast majority of code does not contain vulnerabilities and LLMs are trained on massive amounts of such code, vulnerable code can be viewed as an anomaly from the LLM's predicted code distribution, freeing the model from the need for labelled data to provide a learnable representation of vulnerable code. Leveraging this perspective, we demonstrate that LLMs trained for code generation exhibit a significant gap in prediction accuracy when prompted to reconstruct vulnerable versus non-vulnerable code. Using this insight, we implement ANVIL, a detector that identifies software vulnerabilities at line-level granularity. Our experiments explore the discriminating power of different anomaly scoring methods, as well as the sensitivity of ANVIL to context size. We also study the effectiveness of ANVIL on various LLM families, and conduct leakage experiments on vulnerabilities that were discovered after the knowledge cutoff of our evaluated LLMs. On a collection of vulnerabilities from the Magma benchmark, ANVIL outperforms state-of-the-art line-level vulnerability detectors, LineVul and LineVD, which have been trained with labelled data, despite ANVIL having never been trained with labelled vulnerabilities. Specifically, our approach achieves $1.62\times$ to $2.18\times$ better Top-5 accuracies and $1.02\times$ to $1.29\times$ times better ROC scores on line-level vulnerability detection tasks.