 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing Information Gain in Privacy-Aware Active Learning of Email Anomalies
May 13, 2024



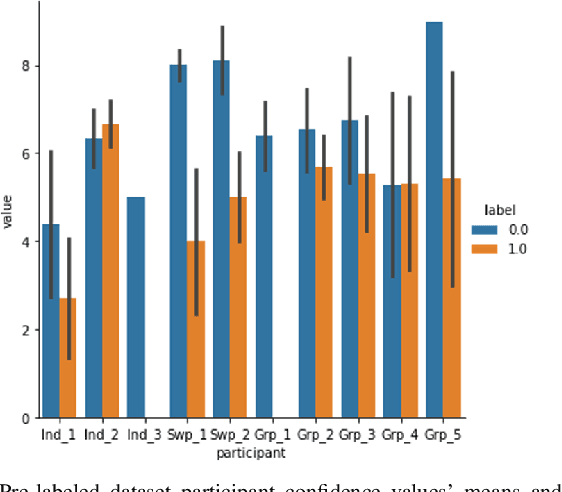
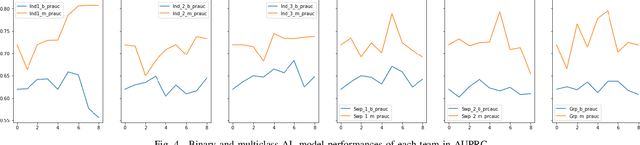
Redacted emails satisfy most privacy requirements but they make it more difficult to detect anomalous emails that may be indicative of data exfiltration. In this paper we develop an enhanced method of Active Learning using an information gain maximizing heuristic, and we evaluate its effectiveness in a real world setting where only redacted versions of email could be labeled by human analysts due to privacy concerns. In the first case study we examined how Active Learning should be carried out. We found that model performance was best when a single highly skilled (in terms of the labelling task) analyst provided the labels. In the second case study we used confidence ratings to estimate the labeling uncertainty of analysts and then prioritized instances for labeling based on the expected information gain (the difference between model uncertainty and analyst uncertainty) that would be provided by labelling each instance. We found that the information maximization gain heuristic improved model performance over existing sampling methods for Active Learning. Based on the results obtained, we recommend that analysts should be screened, and possibly trained, prior to implementation of Active Learning in cybersecurity applications. We also recommend that the information gain maximizing sample method (based on expert confidence) should be used in early stages of Active Learning, providing that well-calibrated confidence can be obtained. We also note that the expertise of analysts should be assessed prior to Active Learning, as we found that analysts with lower labelling skill had poorly calibrated (over-) confidence in their labels.
Implementing Active Learning in Cybersecurity: Detecting Anomalies in Redacted Emails
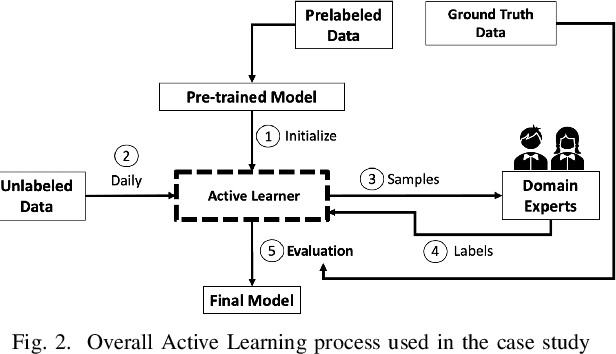
Mar 03, 2023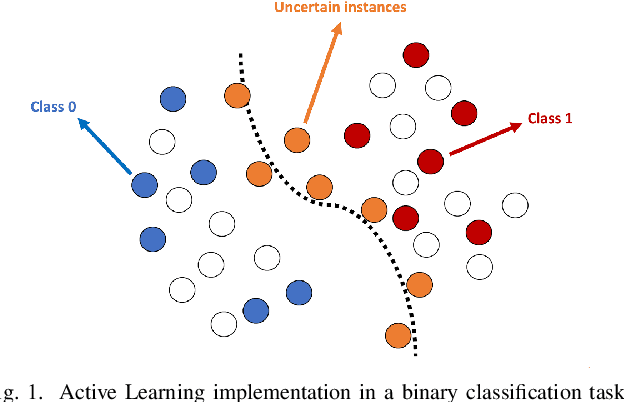
Research on email anomaly detection has typically relied on specially prepared datasets that may not adequately reflect the type of data that occurs in industry settings. In our research, at a major financial services company, privacy concerns prevented inspection of the bodies of emails and attachment details (although subject headings and attachment filenames were available). This made labeling possible anomalies in the resulting redacted emails more difficult. Another source of difficulty is the high volume of emails combined with the scarcity of resources making machine learning (ML) a necessity, but also creating a need for more efficient human training of ML models. Active learning (AL) has been proposed as a way to make human training of ML models more efficient. However, the implementation of Active Learning methods is a human-centered AI challenge due to potential human analyst uncertainty, and the labeling task can be further complicated in domains such as the cybersecurity domain (or healthcare, aviation, etc.) where mistakes in labeling can have highly adverse consequences. In this paper we present research results concerning the application of Active Learning to anomaly detection in redacted emails, comparing the utility of different methods for implementing active learning in this context. We evaluate different AL strategies and their impact on resulting model performance. We also examine how ratings of confidence that experts have in their labels can inform AL. The results obtained are discussed in terms of their implications for AL methodology and for the role of experts in model-assisted email anomaly screening.