 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Will Tell: Timing Side Channels via Output Token Count in Large Language Models
Dec 19, 2024

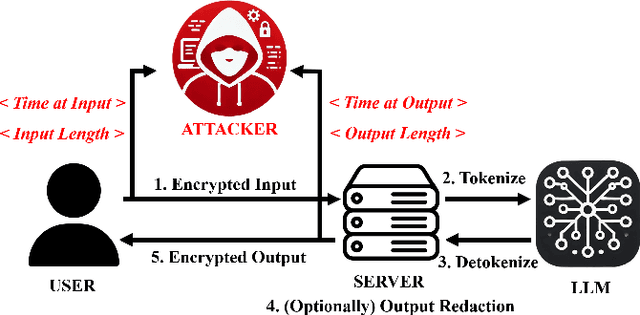

This paper demonstrates a new side-channel that enables an adversary to extract sensitive information about inference inputs in large language models (LLMs) based on the number of output tokens in the LLM response. We construct attacks using this side-channel in two common LLM tasks: recovering the target language in machine translation tasks and recovering the output class in classification tasks. In addition, due to the auto-regressive generation mechanism in LLMs, an adversary can recover the output token count reliably using a timing channel, even over the network against a popular closed-source commercial LLM. Our experiments show that an adversary can learn the output language in translation tasks with more than 75% precision across three different models (Tower, M2M100, MBart50). Using this side-channel, we also show the input class in text classification tasks can be leaked out with more than 70% precision from open-source LLMs like Llama-3.1, Llama-3.2, Gemma2, and production models like GPT-4o. Finally, we propose tokenizer-, system-, and prompt-based mitigations against the output token count side-channel.
Privacy Risks of Speculative Decoding in Large Language Models
Nov 05, 2024Speculative decoding in large language models (LLMs) accelerates token generation by speculatively predicting multiple tokens cheaply and verifying them in parallel, and has been widely deployed. In this paper, we provide the first study demonstrating the privacy risks of speculative decoding. We observe that input-dependent patterns of correct and incorrect predictions can be leaked out to an adversary monitoring token generation times and packet sizes, leading to privacy breaches. By observing the pattern of correctly and incorrectly speculated tokens, we show that a malicious adversary can fingerprint queries and learn private user inputs with more than $90\%$ accuracy across three different speculative decoding techniques - REST (almost $100\%$ accuracy), LADE (up to $92\%$ accuracy), and BiLD (up to $95\%$ accuracy). We show that an adversary can also leak out confidential intellectual property used to design these techniques, such as data from data-stores used for prediction (in REST) at a rate of more than $25$ tokens per second, or even hyper-parameters used for prediction (in LADE). We also discuss mitigation strategies, such as aggregating tokens across multiple iterations and padding packets with additional bytes, to avoid such privacy or confidentiality breaches.