 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen the Curious Abandon Honesty: Federated Learning Is Not Private
Paper and Code


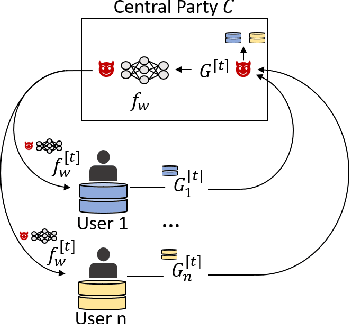
In federated learning (FL), data does not leave personal devices when they are jointly training a machine learning model. Instead, these devices share gradients with a central party (e.g., a company). Because data never "leaves" personal devices, FL is presented as privacy-preserving. Yet, recently it was shown that this protection is but a thin facade, as even a passive attacker observing gradients can reconstruct data of individual users. In this paper, we argue that prior work still largely underestimates the vulnerability of FL. This is because prior efforts exclusively consider passive attackers that are honest-but-curious. Instead, we introduce an active and dishonest attacker acting as the central party, who is able to modify the shared model's weights before users compute model gradients. We call the modified weights "trap weights". Our active attacker is able to recover user data perfectly and at near zero costs: the attack requires no complex optimization objectives. Instead, it exploits inherent data leakage from model gradients and amplifies this effect by maliciously altering the weights of the shared model. These specificities enable our attack to scale to models trained with large mini-batches of data. Where attackers from prior work require hours to recover a single data point, our method needs milliseconds to capture the full mini-batch of data from both fully-connected and convolutional deep neural networks. Finally, we consider mitigations. We observe that current implementations of differential privacy (DP) in FL are flawed, as they explicitly trust the central party with the crucial task of adding DP noise, and thus provide no protection against a malicious central party. We also consider other defenses and explain why they are similarly inadequate. A significant redesign of FL is required for it to provide any meaningful form of data privacy to users.