 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaniCar: Securing the Perception of Advanced Driving Assistance Systems Against Emergency Vehicle Lighting
May 08, 2025
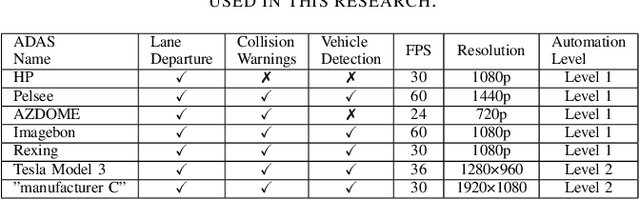

The safety of autonomous cars has come under scrutiny in recent years, especially after 16 documented incidents involving Teslas (with autopilot engaged) crashing into parked emergency vehicles (police cars, ambulances, and firetrucks). While previous studies have revealed that strong light sources often introduce flare artifacts in the captured image, which degrade the image quality, the impact of flare on object detection performance remains unclear. In this research, we unveil PaniCar, a digital phenomenon that causes an object detector's confidence score to fluctuate below detection thresholds when exposed to activated emergency vehicle lighting. This vulnerability poses a significant safety risk, and can cause autonomous vehicles to fail to detect objects near emergency vehicles. In addition, this vulnerability could be exploited by adversaries to compromise the security of advanced driving assistance systems (ADASs). We assess seven commercial ADASs (Tesla Model 3, "manufacturer C", HP, Pelsee, AZDOME, Imagebon, Rexing), four object detectors (YOLO, SSD, RetinaNet, Faster R-CNN), and 14 patterns of emergency vehicle lighting to understand the influence of various technical and environmental factors. We also evaluate four SOTA flare removal methods and show that their performance and latency are insufficient for real-time driving constraints. To mitigate this risk, we propose Caracetamol, a robust framework designed to enhance the resilience of object detectors against the effects of activated emergency vehicle lighting. Our evaluation shows that on YOLOv3 and Faster RCNN, Caracetamol improves the models' average confidence of car detection by 0.20, the lower confidence bound by 0.33, and reduces the fluctuation range by 0.33. In addition, Caracetamol is capable of processing frames at a rate of between 30-50 FPS, enabling real-time ADAS car detection.
Towards an End-to-End (E2E) Adversarial Learning and Application in the Physical World
Jan 16, 2025The traditional learning process of patch-based adversarial attacks, conducted in the digital domain and then applied in the physical domain (e.g., via printed stickers), may suffer from reduced performance due to adversarial patches' limited transferability from the digital domain to the physical domain. Given that previous studies have considered using projectors to apply adversarial attacks, we raise the following question: can adversarial learning (i.e., patch generation) be performed entirely in the physical domain with a projector? In this work, we propose the Physical-domain Adversarial Patch Learning Augmentation (PAPLA) framework, a novel end-to-end (E2E) framework that converts adversarial learning from the digital domain to the physical domain using a projector. We evaluate PAPLA across multiple scenarios, including controlled laboratory settings and realistic outdoor environments, demonstrating its ability to ensure attack success compared to conventional digital learning-physical application (DL-PA) methods. We also analyze the impact of environmental factors, such as projection surface color, projector strength, ambient light, distance, and angle of the target object relative to the camera, on the effectiveness of projected patches. Finally, we demonstrate the feasibility of the attack against a parked car and a stop sign in a real-world outdoor environment. Our results show that under specific conditions, E2E adversarial learning in the physical domain eliminates the transferability issue and ensures evasion by object detectors. Finally, we provide insights into the challenges and opportunities of applying adversarial learning in the physical domain and explain where such an approach is more effective than using a sticker.
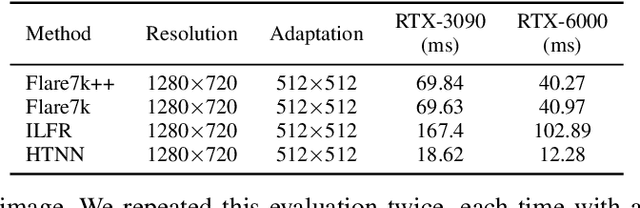
The Adversarial Implications of Variable-Time Inference
Sep 05, 2023

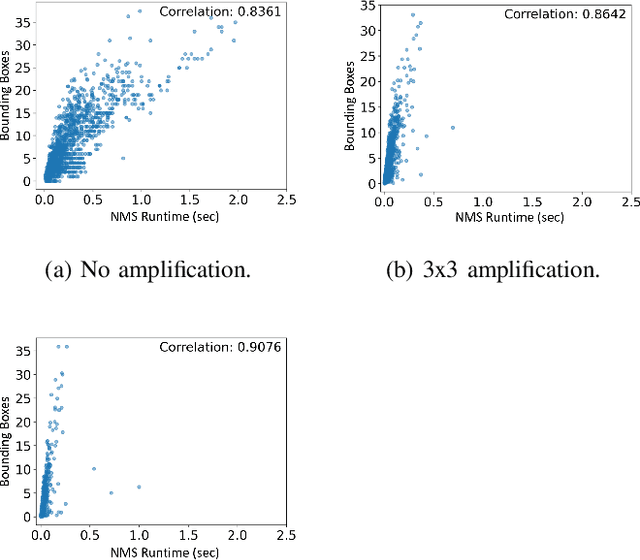

Machine learning (ML) models are known to be vulnerable to a number of attacks that target the integrity of their predictions or the privacy of their training data. To carry out these attacks, a black-box adversary must typically possess the ability to query the model and observe its outputs (e.g., labels). In this work, we demonstrate, for the first time, the ability to enhance such decision-based attacks. To accomplish this, we present an approach that exploits a novel side channel in which the adversary simply measures the execution time of the algorithm used to post-process the predictions of the ML model under attack. The leakage of inference-state elements into algorithmic timing side channels has never been studied before, and we have found that it can contain rich information that facilitates superior timing attacks that significantly outperform attacks based solely on label outputs. In a case study, we investigate leakage from the non-maximum suppression (NMS) algorithm, which plays a crucial role in the operation of object detectors. In our examination of the timing side-channel vulnerabilities associated with this algorithm, we identified the potential to enhance decision-based attacks. We demonstrate attacks against the YOLOv3 detector, leveraging the timing leakage to successfully evade object detection using adversarial examples, and perform dataset inference. Our experiments show that our adversarial examples exhibit superior perturbation quality compared to a decision-based attack. In addition, we present a new threat model in which dataset inference based solely on timing leakage is performed. To address the timing leakage vulnerability inherent in the NMS algorithm, we explore the potential and limitations of implementing constant-time inference passes as a mitigation strategy.