 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeakBoost: Perceptual-Loss-Based Membership Inference Attack
Feb 05, 2026Membership inference attacks (MIAs) aim to determine whether a sample was part of a model's training set, posing serious privacy risks for modern machine-learning systems. Existing MIAs primarily rely on static indicators, such as loss or confidence, and do not fully leverage the dynamic behavior of models when actively probed. We propose LeakBoost, a perceptual-loss-based interrogation framework that actively probes a model's internal representations to expose hidden membership signals. Given a candidate input, LeakBoost synthesizes an interrogation image by optimizing a perceptual (activation-space) objective, amplifying representational differences between members and non-members. This image is then analyzed by an off-the-shelf membership detector, without modifying the detector itself. When combined with existing membership inference methods, LeakBoost achieves substantial improvements at low false-positive rates across multiple image classification datasets and diverse neural network architectures. In particular, it raises AUC from near-chance levels (0.53-0.62) to 0.81-0.88, and increases TPR at 1 percent FPR by over an order of magnitude compared to strong baseline attacks. A detailed sensitivity analysis reveals that deeper layers and short, low-learning-rate optimization produce the strongest leakage, and that improvements concentrate in gradient-based detectors. LeakBoost thus offers a modular and computationally efficient way to assess privacy risks in white-box settings, advancing the study of dynamic membership inference.
GAVEL: Towards rule-based safety through activation monitoring
Jan 29, 2026Large language models (LLMs) are increasingly paired with activation-based monitoring to detect and prevent harmful behaviors that may not be apparent at the surface-text level. However, existing activation safety approaches, trained on broad misuse datasets, struggle with poor precision, limited flexibility, and lack of interpretability. This paper introduces a new paradigm: rule-based activation safety, inspired by rule-sharing practices in cybersecurity. We propose modeling activations as cognitive elements (CEs), fine-grained, interpretable factors such as ''making a threat'' and ''payment processing'', that can be composed to capture nuanced, domain-specific behaviors with higher precision. Building on this representation, we present a practical framework that defines predicate rules over CEs and detects violations in real time. This enables practitioners to configure and update safeguards without retraining models or detectors, while supporting transparency and auditability. Our results show that compositional rule-based activation safety improves precision, supports domain customization, and lays the groundwork for scalable, interpretable, and auditable AI governance. We will release GAVEL as an open-source framework and provide an accompanying automated rule creation tool.
Love, Lies, and Language Models: Investigating AI's Role in Romance-Baiting Scams
Dec 22, 2025Romance-baiting scams have become a major source of financial and emotional harm worldwide. These operations are run by organized crime syndicates that traffic thousands of people into forced labor, requiring them to build emotional intimacy with victims over weeks of text conversations before pressuring them into fraudulent cryptocurrency investments. Because the scams are inherently text-based, they raise urgent questions about the role of Large Language Models (LLMs) in both current and future automation. We investigate this intersection by interviewing 145 insiders and 5 scam victims, performing a blinded long-term conversation study comparing LLM scam agents to human operators, and executing an evaluation of commercial safety filters. Our findings show that LLMs are already widely deployed within scam organizations, with 87% of scam labor consisting of systematized conversational tasks readily susceptible to automation. In a week-long study, an LLM agent not only elicited greater trust from study participants (p=0.007) but also achieved higher compliance with requests than human operators (46% vs. 18% for humans). Meanwhile, popular safety filters detected 0.0% of romance baiting dialogues. Together, these results suggest that romance-baiting scams may be amenable to full-scale LLM automation, while existing defenses remain inadequate to prevent their expansion.
Trust Me, I Know This Function: Hijacking LLM Static Analysis using Bias
Aug 24, 2025Large Language Models (LLMs) are increasingly trusted to perform automated code review and static analysis at scale, supporting tasks such as vulnerability detection, summarization, and refactoring. In this paper, we identify and exploit a critical vulnerability in LLM-based code analysis: an abstraction bias that causes models to overgeneralize familiar programming patterns and overlook small, meaningful bugs. Adversaries can exploit this blind spot to hijack the control flow of the LLM's interpretation with minimal edits and without affecting actual runtime behavior. We refer to this attack as a Familiar Pattern Attack (FPA). We develop a fully automated, black-box algorithm that discovers and injects FPAs into target code. Our evaluation shows that FPAs are not only effective, but also transferable across models (GPT-4o, Claude 3.5, Gemini 2.0) and universal across programming languages (Python, C, Rust, Go). Moreover, FPAs remain effective even when models are explicitly warned about the attack via robust system prompts. Finally, we explore positive, defensive uses of FPAs and discuss their broader implications for the reliability and safety of code-oriented LLMs.
PaniCar: Securing the Perception of Advanced Driving Assistance Systems Against Emergency Vehicle Lighting
May 08, 2025
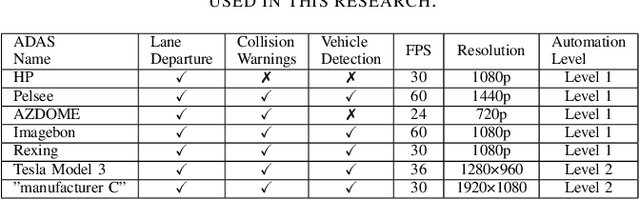

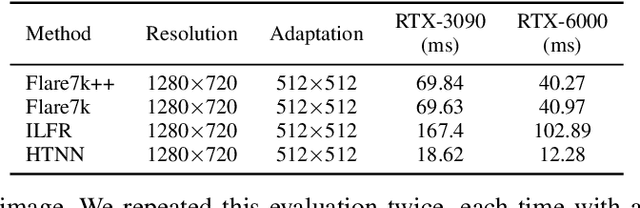
The safety of autonomous cars has come under scrutiny in recent years, especially after 16 documented incidents involving Teslas (with autopilot engaged) crashing into parked emergency vehicles (police cars, ambulances, and firetrucks). While previous studies have revealed that strong light sources often introduce flare artifacts in the captured image, which degrade the image quality, the impact of flare on object detection performance remains unclear. In this research, we unveil PaniCar, a digital phenomenon that causes an object detector's confidence score to fluctuate below detection thresholds when exposed to activated emergency vehicle lighting. This vulnerability poses a significant safety risk, and can cause autonomous vehicles to fail to detect objects near emergency vehicles. In addition, this vulnerability could be exploited by adversaries to compromise the security of advanced driving assistance systems (ADASs). We assess seven commercial ADASs (Tesla Model 3, "manufacturer C", HP, Pelsee, AZDOME, Imagebon, Rexing), four object detectors (YOLO, SSD, RetinaNet, Faster R-CNN), and 14 patterns of emergency vehicle lighting to understand the influence of various technical and environmental factors. We also evaluate four SOTA flare removal methods and show that their performance and latency are insufficient for real-time driving constraints. To mitigate this risk, we propose Caracetamol, a robust framework designed to enhance the resilience of object detectors against the effects of activated emergency vehicle lighting. Our evaluation shows that on YOLOv3 and Faster RCNN, Caracetamol improves the models' average confidence of car detection by 0.20, the lower confidence bound by 0.33, and reduces the fluctuation range by 0.33. In addition, Caracetamol is capable of processing frames at a rate of between 30-50 FPS, enabling real-time ADAS car detection.
Memory Backdoor Attacks on Neural Networks
Nov 21, 2024



Neural networks, such as image classifiers, are frequently trained on proprietary and confidential datasets. It is generally assumed that once deployed, the training data remains secure, as adversaries are limited to query response interactions with the model, where at best, fragments of arbitrary data can be inferred without any guarantees on their authenticity. In this paper, we propose the memory backdoor attack, where a model is covertly trained to memorize specific training samples and later selectively output them when triggered with an index pattern. What makes this attack unique is that it (1) works even when the tasks conflict (making a classifier output images), (2) enables the systematic extraction of training samples from deployed models and (3) offers guarantees on the extracted authenticity of the data. We demonstrate the attack on image classifiers, segmentation models, and a large language model (LLM). We demonstrate the attack on image classifiers, segmentation models, and a large language model (LLM). With this attack, it is possible to hide thousands of images and texts in modern vision architectures and LLMs respectively, all while maintaining model performance. The memory back door attack poses a significant threat not only to conventional model deployments but also to federated learning paradigms and other modern frameworks. Therefore, we suggest an efficient and effective countermeasure that can be immediately applied and advocate for further work on the topic.
Efficient Model Extraction via Boundary Sampling
Oct 20, 2024This paper introduces a novel data-free model extraction attack that significantly advances the current state-of-the-art in terms of efficiency, accuracy, and effectiveness. Traditional black-box methods rely on using the victim's model as an oracle to label a vast number of samples within high-confidence areas. This approach not only requires an extensive number of queries but also results in a less accurate and less transferable model. In contrast, our method innovates by focusing on sampling low-confidence areas (along the decision boundaries) and employing an evolutionary algorithm to optimize the sampling process. These novel contributions allow for a dramatic reduction in the number of queries needed by the attacker by a factor of 10x to 600x while simultaneously improving the accuracy of the stolen model. Moreover, our approach improves boundary alignment, resulting in better transferability of adversarial examples from the stolen model to the victim's model (increasing the attack success rate from 60\% to 82\% on average). Finally, we accomplish all of this with a strict black-box assumption on the victim, with no knowledge of the target's architecture or dataset. We demonstrate our attack on three datasets with increasingly larger resolutions and compare our performance to four state-of-the-art model extraction attacks.
PEAS: A Strategy for Crafting Transferable Adversarial Examples
Oct 20, 2024Black box attacks, where adversaries have limited knowledge of the target model, pose a significant threat to machine learning systems. Adversarial examples generated with a substitute model often suffer from limited transferability to the target model. While recent work explores ranking perturbations for improved success rates, these methods see only modest gains. We propose a novel strategy called PEAS that can boost the transferability of existing black box attacks. PEAS leverages the insight that samples which are perceptually equivalent exhibit significant variability in their adversarial transferability. Our approach first generates a set of images from an initial sample via subtle augmentations. We then evaluate the transferability of adversarial perturbations on these images using a set of substitute models. Finally, the most transferable adversarial example is selected and used for the attack. Our experiments show that PEAS can double the performance of existing attacks, achieving a 2.5x improvement in attack success rates on average over current ranking methods. We thoroughly evaluate PEAS on ImageNet and CIFAR-10, analyze hyperparameter impacts, and provide an ablation study to isolate each component's importance.
Are You Human? An Adversarial Benchmark to Expose LLMs
Oct 12, 2024Large Language Models (LLMs) have demonstrated an alarming ability to impersonate humans in conversation, raising concerns about their potential misuse in scams and deception. Humans have a right to know if they are conversing to an LLM. We evaluate text-based prompts designed as challenges to expose LLM imposters in real-time. To this end we compile and release an open-source benchmark dataset that includes 'implicit challenges' that exploit an LLM's instruction-following mechanism to cause role deviation, and 'exlicit challenges' that test an LLM's ability to perform simple tasks typically easy for humans but difficult for LLMs. Our evaluation of 9 leading models from the LMSYS leaderboard revealed that explicit challenges successfully detected LLMs in 78.4% of cases, while implicit challenges were effective in 22.9% of instances. User studies validate the real-world applicability of our methods, with humans outperforming LLMs on explicit challenges (78% vs 22% success rate). Our framework unexpectedly revealed that many study participants were using LLMs to complete tasks, demonstrating its effectiveness in detecting both AI impostors and human misuse of AI tools. This work addresses the critical need for reliable, real-time LLM detection methods in high-stakes conversations.
Back-in-Time Diffusion: Unsupervised Detection of Medical Deepfakes
Jul 21, 2024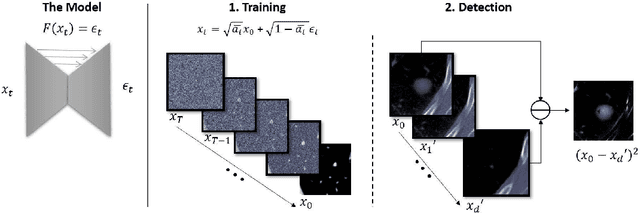



Recent progress in generative models has made it easier for a wide audience to edit and create image content, raising concerns about the proliferation of deepfakes, especially in healthcare. Despite the availability of numerous techniques for detecting manipulated images captured by conventional cameras, their applicability to medical images is limited. This limitation stems from the distinctive forensic characteristics of medical images, a result of their imaging process. In this work we propose a novel anomaly detector for medical imagery based on diffusion models. Normally, diffusion models are used to generate images. However, we show how a similar process can be used to detect synthetic content by making a model reverse the diffusion on a suspected image. We evaluate our method on the task of detecting fake tumors injected and removed from CT and MRI scans. Our method significantly outperforms other state of the art unsupervised detectors with an increased AUC of 0.9 from 0.79 for injection and of 0.96 from 0.91 for removal on average.