 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Recovering Instruction Sets from Language Model Activations
Jun 08, 2026As LLMs are deployed as agents, reliable monitoring requires knowing not only what they output, but which instructions are steering their behavior. This is difficult when models infer unintended subgoals, follow contextual cues, or are influenced by prompt injections and hidden objectives. While activation-to-language methods suggest that hidden states can reveal natural-language information, existing approaches are not designed to recover the full set of simultaneous instructions, constraints, prohibitions, and subgoals active in agentic settings. We formalize this problem as instruction set retrieval and introduce PRISM, an activation-conditioned interpreter that decodes hidden states from a frozen target model into a faithful bullet list of active instructions. Unlike prior activation-to-language methods, PRISM is trained to recover instruction sets directly, using judge-guided GRPO to reward covered instructions and penalize unsupported ones. Across benign, constrained, prompt-injection, and hidden-objective settings, PRISM outperforms activation-to-language baselines, especially on security-relevant objectives.
GAVEL: Towards rule-based safety through activation monitoring
Jan 29, 2026Large language models (LLMs) are increasingly paired with activation-based monitoring to detect and prevent harmful behaviors that may not be apparent at the surface-text level. However, existing activation safety approaches, trained on broad misuse datasets, struggle with poor precision, limited flexibility, and lack of interpretability. This paper introduces a new paradigm: rule-based activation safety, inspired by rule-sharing practices in cybersecurity. We propose modeling activations as cognitive elements (CEs), fine-grained, interpretable factors such as ''making a threat'' and ''payment processing'', that can be composed to capture nuanced, domain-specific behaviors with higher precision. Building on this representation, we present a practical framework that defines predicate rules over CEs and detects violations in real time. This enables practitioners to configure and update safeguards without retraining models or detectors, while supporting transparency and auditability. Our results show that compositional rule-based activation safety improves precision, supports domain customization, and lays the groundwork for scalable, interpretable, and auditable AI governance. We will release GAVEL as an open-source framework and provide an accompanying automated rule creation tool.
Love, Lies, and Language Models: Investigating AI's Role in Romance-Baiting Scams
Dec 22, 2025Romance-baiting scams have become a major source of financial and emotional harm worldwide. These operations are run by organized crime syndicates that traffic thousands of people into forced labor, requiring them to build emotional intimacy with victims over weeks of text conversations before pressuring them into fraudulent cryptocurrency investments. Because the scams are inherently text-based, they raise urgent questions about the role of Large Language Models (LLMs) in both current and future automation. We investigate this intersection by interviewing 145 insiders and 5 scam victims, performing a blinded long-term conversation study comparing LLM scam agents to human operators, and executing an evaluation of commercial safety filters. Our findings show that LLMs are already widely deployed within scam organizations, with 87% of scam labor consisting of systematized conversational tasks readily susceptible to automation. In a week-long study, an LLM agent not only elicited greater trust from study participants (p=0.007) but also achieved higher compliance with requests than human operators (46% vs. 18% for humans). Meanwhile, popular safety filters detected 0.0% of romance baiting dialogues. Together, these results suggest that romance-baiting scams may be amenable to full-scale LLM automation, while existing defenses remain inadequate to prevent their expansion.
Are You Human? An Adversarial Benchmark to Expose LLMs
Oct 12, 2024Large Language Models (LLMs) have demonstrated an alarming ability to impersonate humans in conversation, raising concerns about their potential misuse in scams and deception. Humans have a right to know if they are conversing to an LLM. We evaluate text-based prompts designed as challenges to expose LLM imposters in real-time. To this end we compile and release an open-source benchmark dataset that includes 'implicit challenges' that exploit an LLM's instruction-following mechanism to cause role deviation, and 'exlicit challenges' that test an LLM's ability to perform simple tasks typically easy for humans but difficult for LLMs. Our evaluation of 9 leading models from the LMSYS leaderboard revealed that explicit challenges successfully detected LLMs in 78.4% of cases, while implicit challenges were effective in 22.9% of instances. User studies validate the real-world applicability of our methods, with humans outperforming LLMs on explicit challenges (78% vs 22% success rate). Our framework unexpectedly revealed that many study participants were using LLMs to complete tasks, demonstrating its effectiveness in detecting both AI impostors and human misuse of AI tools. This work addresses the critical need for reliable, real-time LLM detection methods in high-stakes conversations.
Mapping LLM Security Landscapes: A Comprehensive Stakeholder Risk Assessment Proposal
Mar 20, 2024

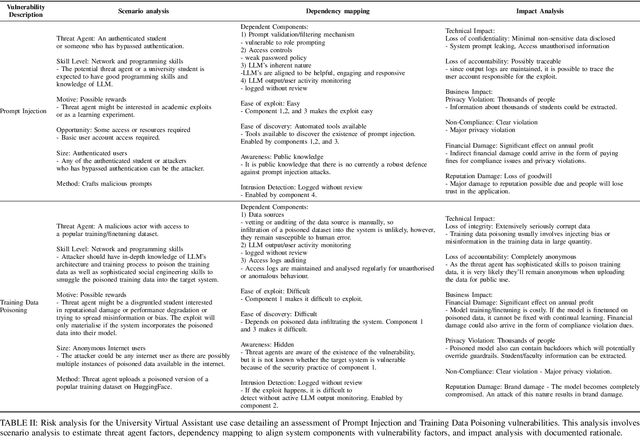

The rapid integration of Large Language Models (LLMs) across diverse sectors has marked a transformative era, showcasing remarkable capabilities in text generation and problem-solving tasks. However, this technological advancement is accompanied by significant risks and vulnerabilities. Despite ongoing security enhancements, attackers persistently exploit these weaknesses, casting doubts on the overall trustworthiness of LLMs. Compounding the issue, organisations are deploying LLM-integrated systems without understanding the severity of potential consequences. Existing studies by OWASP and MITRE offer a general overview of threats and vulnerabilities but lack a method for directly and succinctly analysing the risks for security practitioners, developers, and key decision-makers who are working with this novel technology. To address this gap, we propose a risk assessment process using tools like the OWASP risk rating methodology which is used for traditional systems. We conduct scenario analysis to identify potential threat agents and map the dependent system components against vulnerability factors. Through this analysis, we assess the likelihood of a cyberattack. Subsequently, we conduct a thorough impact analysis to derive a comprehensive threat matrix. We also map threats against three key stakeholder groups: developers engaged in model fine-tuning, application developers utilizing third-party APIs, and end users. The proposed threat matrix provides a holistic evaluation of LLM-related risks, enabling stakeholders to make informed decisions for effective mitigation strategies. Our outlined process serves as an actionable and comprehensive tool for security practitioners, offering insights for resource management and enhancing the overall system security.