 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaniCar: Securing the Perception of Advanced Driving Assistance Systems Against Emergency Vehicle Lighting
May 08, 2025
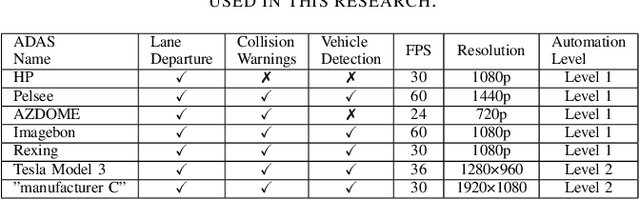

The safety of autonomous cars has come under scrutiny in recent years, especially after 16 documented incidents involving Teslas (with autopilot engaged) crashing into parked emergency vehicles (police cars, ambulances, and firetrucks). While previous studies have revealed that strong light sources often introduce flare artifacts in the captured image, which degrade the image quality, the impact of flare on object detection performance remains unclear. In this research, we unveil PaniCar, a digital phenomenon that causes an object detector's confidence score to fluctuate below detection thresholds when exposed to activated emergency vehicle lighting. This vulnerability poses a significant safety risk, and can cause autonomous vehicles to fail to detect objects near emergency vehicles. In addition, this vulnerability could be exploited by adversaries to compromise the security of advanced driving assistance systems (ADASs). We assess seven commercial ADASs (Tesla Model 3, "manufacturer C", HP, Pelsee, AZDOME, Imagebon, Rexing), four object detectors (YOLO, SSD, RetinaNet, Faster R-CNN), and 14 patterns of emergency vehicle lighting to understand the influence of various technical and environmental factors. We also evaluate four SOTA flare removal methods and show that their performance and latency are insufficient for real-time driving constraints. To mitigate this risk, we propose Caracetamol, a robust framework designed to enhance the resilience of object detectors against the effects of activated emergency vehicle lighting. Our evaluation shows that on YOLOv3 and Faster RCNN, Caracetamol improves the models' average confidence of car detection by 0.20, the lower confidence bound by 0.33, and reduces the fluctuation range by 0.33. In addition, Caracetamol is capable of processing frames at a rate of between 30-50 FPS, enabling real-time ADAS car detection.
A Privacy Enhancing Technique to Evade Detection by Street Video Cameras Without Using Adversarial Accessories
Jan 26, 2025



In this paper, we propose a privacy-enhancing technique leveraging an inherent property of automatic pedestrian detection algorithms, namely, that the training of deep neural network (DNN) based methods is generally performed using curated datasets and laboratory settings, while the operational areas of these methods are dynamic real-world environments. In particular, we leverage a novel side effect of this gap between the laboratory and the real world: location-based weakness in pedestrian detection. We demonstrate that the position (distance, angle, height) of a person, and ambient light level, directly impact the confidence of a pedestrian detector when detecting the person. We then demonstrate that this phenomenon is present in pedestrian detectors observing a stationary scene of pedestrian traffic, with blind spot areas of weak detection of pedestrians with low confidence. We show how privacy-concerned pedestrians can leverage these blind spots to evade detection by constructing a minimum confidence path between two points in a scene, reducing the maximum confidence and average confidence of the path by up to 0.09 and 0.13, respectively, over direct and random paths through the scene. To counter this phenomenon, and force the use of more costly and sophisticated methods to leverage this vulnerability, we propose a novel countermeasure to improve the confidence of pedestrian detectors in blind spots, raising the max/average confidence of paths generated by our technique by 0.09 and 0.05, respectively. In addition, we demonstrate that our countermeasure improves a Faster R-CNN-based pedestrian detector's TPR and average true positive confidence by 0.03 and 0.15, respectively.
Towards an End-to-End (E2E) Adversarial Learning and Application in the Physical World
Jan 16, 2025The traditional learning process of patch-based adversarial attacks, conducted in the digital domain and then applied in the physical domain (e.g., via printed stickers), may suffer from reduced performance due to adversarial patches' limited transferability from the digital domain to the physical domain. Given that previous studies have considered using projectors to apply adversarial attacks, we raise the following question: can adversarial learning (i.e., patch generation) be performed entirely in the physical domain with a projector? In this work, we propose the Physical-domain Adversarial Patch Learning Augmentation (PAPLA) framework, a novel end-to-end (E2E) framework that converts adversarial learning from the digital domain to the physical domain using a projector. We evaluate PAPLA across multiple scenarios, including controlled laboratory settings and realistic outdoor environments, demonstrating its ability to ensure attack success compared to conventional digital learning-physical application (DL-PA) methods. We also analyze the impact of environmental factors, such as projection surface color, projector strength, ambient light, distance, and angle of the target object relative to the camera, on the effectiveness of projected patches. Finally, we demonstrate the feasibility of the attack against a parked car and a stop sign in a real-world outdoor environment. Our results show that under specific conditions, E2E adversarial learning in the physical domain eliminates the transferability issue and ensures evasion by object detectors. Finally, we provide insights into the challenges and opportunities of applying adversarial learning in the physical domain and explain where such an approach is more effective than using a sticker.
Bounding-box Watermarking: Defense against Model Extraction Attacks on Object Detectors
Nov 20, 2024Deep neural networks (DNNs) deployed in a cloud often allow users to query models via the APIs. However, these APIs expose the models to model extraction attacks (MEAs). In this attack, the attacker attempts to duplicate the target model by abusing the responses from the API. Backdoor-based DNN watermarking is known as a promising defense against MEAs, wherein the defender injects a backdoor into extracted models via API responses. The backdoor is used as a watermark of the model; if a suspicious model has the watermark (i.e., backdoor), it is verified as an extracted model. This work focuses on object detection (OD) models. Existing backdoor attacks on OD models are not applicable for model watermarking as the defense against MEAs on a realistic threat model. Our proposed approach involves inserting a backdoor into extracted models via APIs by stealthily modifying the bounding-boxes (BBs) of objects detected in queries while keeping the OD capability. In our experiments on three OD datasets, the proposed approach succeeded in identifying the extracted models with 100% accuracy in a wide variety of experimental scenarios.
YolOOD: Utilizing Object Detection Concepts for Out-of-Distribution Detection
Dec 05, 2022



Out-of-distribution (OOD) detection has attracted a large amount of attention from the machine learning research community in recent years due to its importance in deployed systems. Most of the previous studies focused on the detection of OOD samples in the multi-class classification task. However, OOD detection in the multi-label classification task remains an underexplored domain. In this research, we propose YolOOD - a method that utilizes concepts from the object detection domain to perform OOD detection in the multi-label classification task. Object detection models have an inherent ability to distinguish between objects of interest (in-distribution) and irrelevant objects (e.g., OOD objects) on images that contain multiple objects from different categories. These abilities allow us to convert a regular object detection model into an image classifier with inherent OOD detection capabilities with just minor changes. We compare our approach to state-of-the-art OOD detection methods and demonstrate YolOOD's ability to outperform these methods on a comprehensive suite of in-distribution and OOD benchmark datasets.