 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIESEL -- Dynamic Inference-Guidance via Evasion of Semantic Embeddings in LLMs
Nov 28, 2024In recent years, conversational large language models (LLMs) have shown tremendous success in tasks such as casual conversation, question answering, and personalized dialogue, making significant advancements in domains like virtual assistance, social interaction, and online customer engagement. However, they often generate responses that are not aligned with human values (e.g., ethical standards, safety, or social norms), leading to potentially unsafe or inappropriate outputs. While several techniques have been proposed to address this problem, they come with a cost, requiring computationally expensive training or dramatically increasing the inference time. In this paper, we present DIESEL, a lightweight inference guidance technique that can be seamlessly integrated into any autoregressive LLM to semantically filter undesired concepts from the response. DIESEL can function either as a standalone safeguard or as an additional layer of defense, enhancing response safety by reranking the LLM's proposed tokens based on their similarity to predefined negative concepts in the latent space. This approach provides an efficient and effective solution for maintaining alignment with human values. Our evaluation demonstrates DIESEL's effectiveness on state-of-the-art conversational models (e.g., Llama 3), even in challenging jailbreaking scenarios that test the limits of response safety. We further show that DIESEL can be generalized to use cases other than safety, providing a versatile solution for general-purpose response filtering with minimal computational overhead.
DeSparsify: Adversarial Attack Against Token Sparsification Mechanisms in Vision Transformers
Feb 04, 2024Vision transformers have contributed greatly to advancements in the computer vision domain, demonstrating state-of-the-art performance in diverse tasks (e.g., image classification, object detection). However, their high computational requirements grow quadratically with the number of tokens used. Token sparsification techniques have been proposed to address this issue. These techniques employ an input-dependent strategy, in which uninformative tokens are discarded from the computation pipeline, improving the model's efficiency. However, their dynamism and average-case assumption makes them vulnerable to a new threat vector - carefully crafted adversarial examples capable of fooling the sparsification mechanism, resulting in worst-case performance. In this paper, we present DeSparsify, an attack targeting the availability of vision transformers that use token sparsification mechanisms. The attack aims to exhaust the operating system's resources, while maintaining its stealthiness. Our evaluation demonstrates the attack's effectiveness on three token sparsification techniques and examines the attack's transferability between them and its effect on the GPU resources. To mitigate the impact of the attack, we propose various countermeasures.
QuantAttack: Exploiting Dynamic Quantization to Attack Vision Transformers
Dec 03, 2023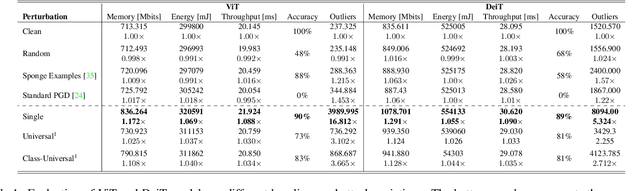
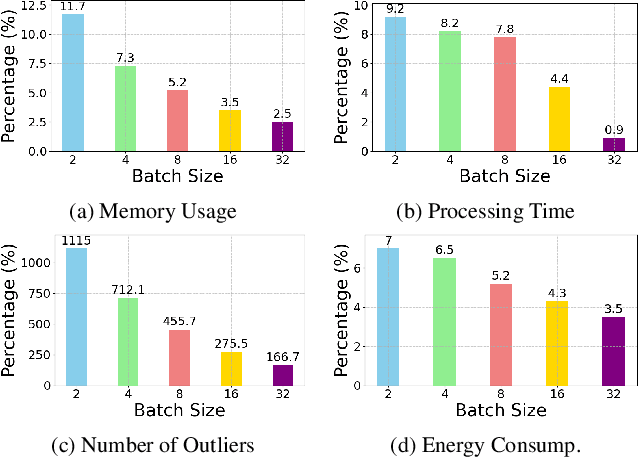
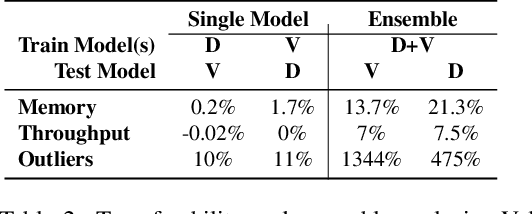
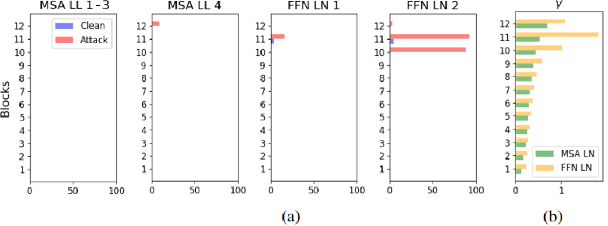
In recent years, there has been a significant trend in deep neural networks (DNNs), particularly transformer-based models, of developing ever-larger and more capable models. While they demonstrate state-of-the-art performance, their growing scale requires increased computational resources (e.g., GPUs with greater memory capacity). To address this problem, quantization techniques (i.e., low-bit-precision representation and matrix multiplication) have been proposed. Most quantization techniques employ a static strategy in which the model parameters are quantized, either during training or inference, without considering the test-time sample. In contrast, dynamic quantization techniques, which have become increasingly popular, adapt during inference based on the input provided, while maintaining full-precision performance. However, their dynamic behavior and average-case performance assumption makes them vulnerable to a novel threat vector -- adversarial attacks that target the model's efficiency and availability. In this paper, we present QuantAttack, a novel attack that targets the availability of quantized models, slowing down the inference, and increasing memory usage and energy consumption. We show that carefully crafted adversarial examples, which are designed to exhaust the resources of the operating system, can trigger worst-case performance. In our experiments, we demonstrate the effectiveness of our attack on vision transformers on a wide range of tasks, both uni-modal and multi-modal. We also examine the effect of different attack variants (e.g., a universal perturbation) and the transferability between different models.
YolOOD: Utilizing Object Detection Concepts for Out-of-Distribution Detection
Dec 05, 2022



Out-of-distribution (OOD) detection has attracted a large amount of attention from the machine learning research community in recent years due to its importance in deployed systems. Most of the previous studies focused on the detection of OOD samples in the multi-class classification task. However, OOD detection in the multi-label classification task remains an underexplored domain. In this research, we propose YolOOD - a method that utilizes concepts from the object detection domain to perform OOD detection in the multi-label classification task. Object detection models have an inherent ability to distinguish between objects of interest (in-distribution) and irrelevant objects (e.g., OOD objects) on images that contain multiple objects from different categories. These abilities allow us to convert a regular object detection model into an image classifier with inherent OOD detection capabilities with just minor changes. We compare our approach to state-of-the-art OOD detection methods and demonstrate YolOOD's ability to outperform these methods on a comprehensive suite of in-distribution and OOD benchmark datasets.
Attacking Object Detector Using A Universal Targeted Label-Switch Patch
Nov 16, 2022Adversarial attacks against deep learning-based object detectors (ODs) have been studied extensively in the past few years. These attacks cause the model to make incorrect predictions by placing a patch containing an adversarial pattern on the target object or anywhere within the frame. However, none of prior research proposed a misclassification attack on ODs, in which the patch is applied on the target object. In this study, we propose a novel, universal, targeted, label-switch attack against the state-of-the-art object detector, YOLO. In our attack, we use (i) a tailored projection function to enable the placement of the adversarial patch on multiple target objects in the image (e.g., cars), each of which may be located a different distance away from the camera or have a different view angle relative to the camera, and (ii) a unique loss function capable of changing the label of the attacked objects. The proposed universal patch, which is trained in the digital domain, is transferable to the physical domain. We performed an extensive evaluation using different types of object detectors, different video streams captured by different cameras, and various target classes, and evaluated different configurations of the adversarial patch in the physical domain.
Denial-of-Service Attack on Object Detection Model Using Universal Adversarial Perturbation
May 26, 2022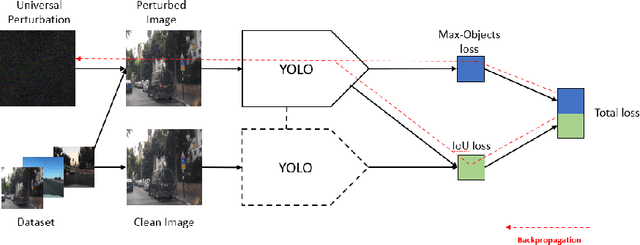
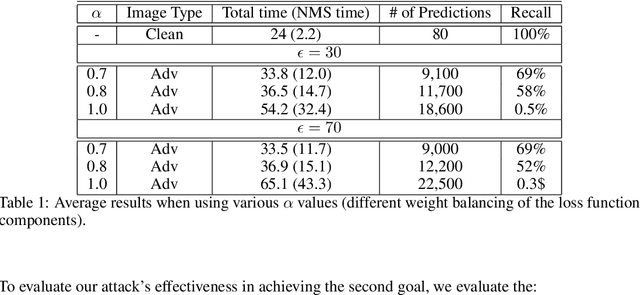
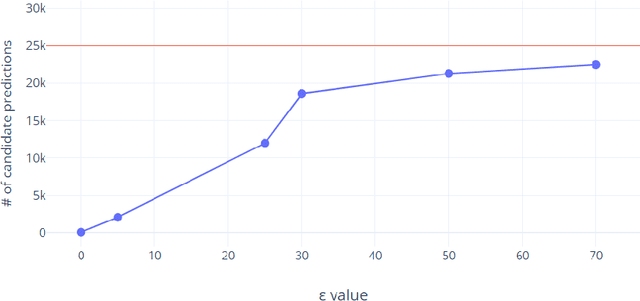
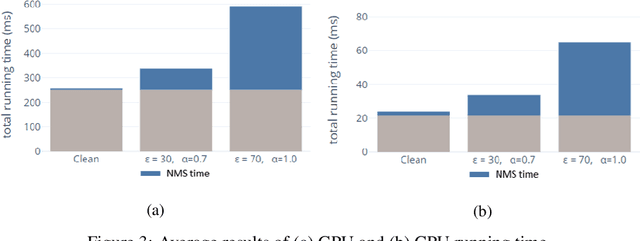
Adversarial attacks against deep learning-based object detectors have been studied extensively in the past few years. The proposed attacks aimed solely at compromising the models' integrity (i.e., trustworthiness of the model's prediction), while adversarial attacks targeting the models' availability, a critical aspect in safety-critical domains such as autonomous driving, have not been explored by the machine learning research community. In this paper, we propose NMS-Sponge, a novel approach that negatively affects the decision latency of YOLO, a state-of-the-art object detector, and compromises the model's availability by applying a universal adversarial perturbation (UAP). In our experiments, we demonstrate that the proposed UAP is able to increase the processing time of individual frames by adding "phantom" objects while preserving the detection of the original objects.
Adversarial Mask: Real-World Adversarial Attack Against Face Recognition Models
Nov 21, 2021
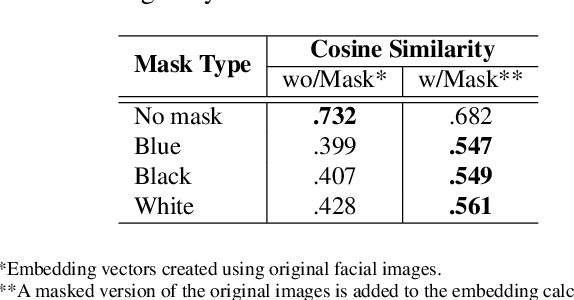
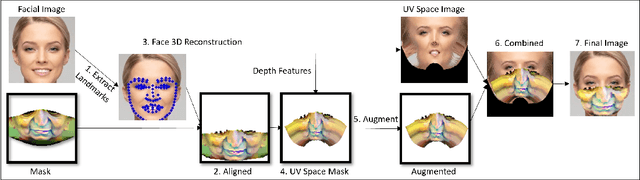
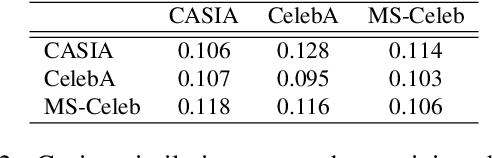
Deep learning-based facial recognition (FR) models have demonstrated state-of-the-art performance in the past few years, even when wearing protective medical face masks became commonplace during the COVID-19 pandemic. Given the outstanding performance of these models, the machine learning research community has shown increasing interest in challenging their robustness. Initially, researchers presented adversarial attacks in the digital domain, and later the attacks were transferred to the physical domain. However, in many cases, attacks in the physical domain are conspicuous, requiring, for example, the placement of a sticker on the face, and thus may raise suspicion in real-world environments (e.g., airports). In this paper, we propose Adversarial Mask, a physical adversarial universal perturbation (UAP) against state-of-the-art FR models that is applied on face masks in the form of a carefully crafted pattern. In our experiments, we examined the transferability of our adversarial mask to a wide range of FR model architectures and datasets. In addition, we validated our adversarial mask effectiveness in real-world experiments by printing the adversarial pattern on a fabric medical face mask, causing the FR system to identify only 3.34% of the participants wearing the mask (compared to a minimum of 83.34% with other evaluated masks).
The Translucent Patch: A Physical and Universal Attack on Object Detectors
Dec 23, 2020
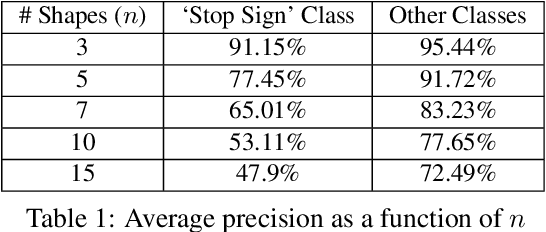

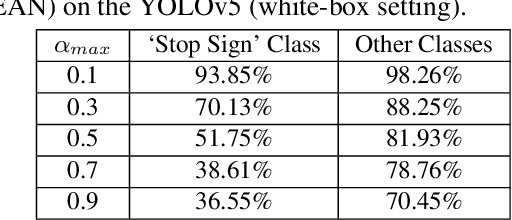
Physical adversarial attacks against object detectors have seen increasing success in recent years. However, these attacks require direct access to the object of interest in order to apply a physical patch. Furthermore, to hide multiple objects, an adversarial patch must be applied to each object. In this paper, we propose a contactless translucent physical patch containing a carefully constructed pattern, which is placed on the camera's lens, to fool state-of-the-art object detectors. The primary goal of our patch is to hide all instances of a selected target class. In addition, the optimization method used to construct the patch aims to ensure that the detection of other (untargeted) classes remains unharmed. Therefore, in our experiments, which are conducted on state-of-the-art object detection models used in autonomous driving, we study the effect of the patch on the detection of both the selected target class and the other classes. We show that our patch was able to prevent the detection of 42.27% of all stop sign instances while maintaining high (nearly 80%) detection of the other classes.