 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumiMAS: A Comprehensive Framework for Real-Time Monitoring and Enhanced Observability in Multi-Agent Systems
Aug 17, 2025The incorporation of large language models in multi-agent systems (MASs) has the potential to significantly improve our ability to autonomously solve complex problems. However, such systems introduce unique challenges in monitoring, interpreting, and detecting system failures. Most existing MAS observability frameworks focus on analyzing each individual agent separately, overlooking failures associated with the entire MAS. To bridge this gap, we propose LumiMAS, a novel MAS observability framework that incorporates advanced analytics and monitoring techniques. The proposed framework consists of three key components: a monitoring and logging layer, anomaly detection layer, and anomaly explanation layer. LumiMAS's first layer monitors MAS executions, creating detailed logs of the agents' activity. These logs serve as input to the anomaly detection layer, which detects anomalies across the MAS workflow in real time. Then, the anomaly explanation layer performs classification and root cause analysis (RCA) of the detected anomalies. LumiMAS was evaluated on seven different MAS applications, implemented using two popular MAS platforms, and a diverse set of possible failures. The applications include two novel failure-tailored applications that illustrate the effects of a hallucination or bias on the MAS. The evaluation results demonstrate LumiMAS's effectiveness in failure detection, classification, and RCA.
DeSparsify: Adversarial Attack Against Token Sparsification Mechanisms in Vision Transformers
Feb 04, 2024Vision transformers have contributed greatly to advancements in the computer vision domain, demonstrating state-of-the-art performance in diverse tasks (e.g., image classification, object detection). However, their high computational requirements grow quadratically with the number of tokens used. Token sparsification techniques have been proposed to address this issue. These techniques employ an input-dependent strategy, in which uninformative tokens are discarded from the computation pipeline, improving the model's efficiency. However, their dynamism and average-case assumption makes them vulnerable to a new threat vector - carefully crafted adversarial examples capable of fooling the sparsification mechanism, resulting in worst-case performance. In this paper, we present DeSparsify, an attack targeting the availability of vision transformers that use token sparsification mechanisms. The attack aims to exhaust the operating system's resources, while maintaining its stealthiness. Our evaluation demonstrates the attack's effectiveness on three token sparsification techniques and examines the attack's transferability between them and its effect on the GPU resources. To mitigate the impact of the attack, we propose various countermeasures.
QuantAttack: Exploiting Dynamic Quantization to Attack Vision Transformers
Dec 03, 2023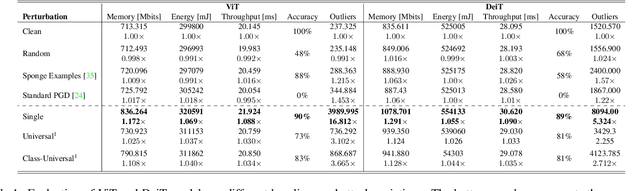
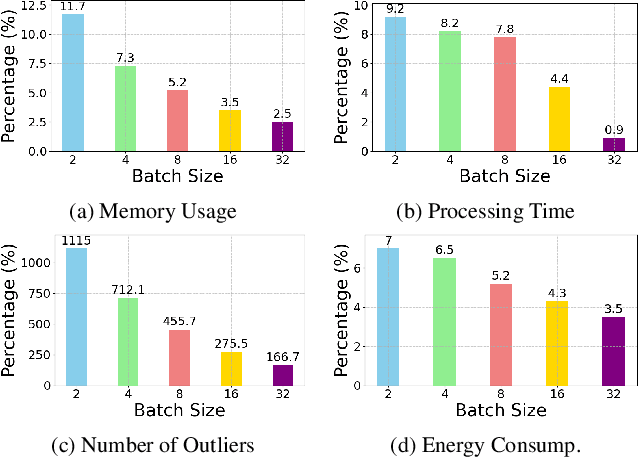
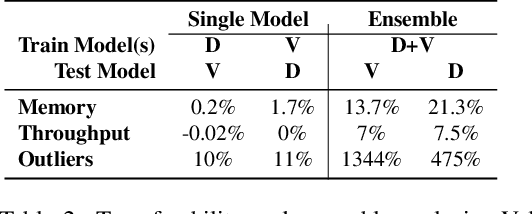
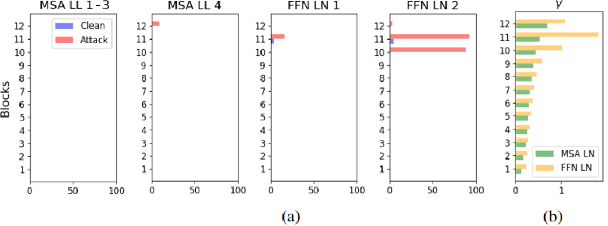
In recent years, there has been a significant trend in deep neural networks (DNNs), particularly transformer-based models, of developing ever-larger and more capable models. While they demonstrate state-of-the-art performance, their growing scale requires increased computational resources (e.g., GPUs with greater memory capacity). To address this problem, quantization techniques (i.e., low-bit-precision representation and matrix multiplication) have been proposed. Most quantization techniques employ a static strategy in which the model parameters are quantized, either during training or inference, without considering the test-time sample. In contrast, dynamic quantization techniques, which have become increasingly popular, adapt during inference based on the input provided, while maintaining full-precision performance. However, their dynamic behavior and average-case performance assumption makes them vulnerable to a novel threat vector -- adversarial attacks that target the model's efficiency and availability. In this paper, we present QuantAttack, a novel attack that targets the availability of quantized models, slowing down the inference, and increasing memory usage and energy consumption. We show that carefully crafted adversarial examples, which are designed to exhaust the resources of the operating system, can trigger worst-case performance. In our experiments, we demonstrate the effectiveness of our attack on vision transformers on a wide range of tasks, both uni-modal and multi-modal. We also examine the effect of different attack variants (e.g., a universal perturbation) and the transferability between different models.
YolOOD: Utilizing Object Detection Concepts for Out-of-Distribution Detection
Dec 05, 2022



Out-of-distribution (OOD) detection has attracted a large amount of attention from the machine learning research community in recent years due to its importance in deployed systems. Most of the previous studies focused on the detection of OOD samples in the multi-class classification task. However, OOD detection in the multi-label classification task remains an underexplored domain. In this research, we propose YolOOD - a method that utilizes concepts from the object detection domain to perform OOD detection in the multi-label classification task. Object detection models have an inherent ability to distinguish between objects of interest (in-distribution) and irrelevant objects (e.g., OOD objects) on images that contain multiple objects from different categories. These abilities allow us to convert a regular object detection model into an image classifier with inherent OOD detection capabilities with just minor changes. We compare our approach to state-of-the-art OOD detection methods and demonstrate YolOOD's ability to outperform these methods on a comprehensive suite of in-distribution and OOD benchmark datasets.