 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantAttack: Exploiting Dynamic Quantization to Attack Vision Transformers
Paper and Code
Dec 03, 2023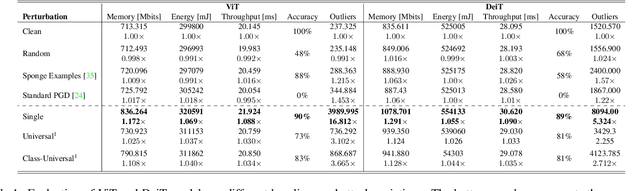
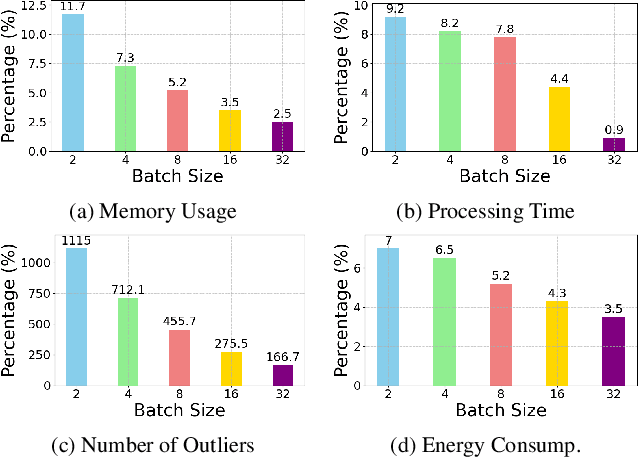
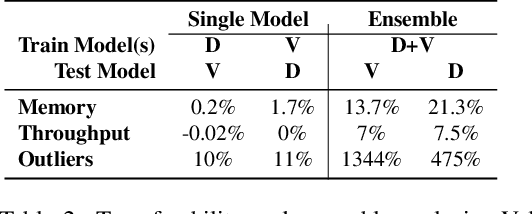
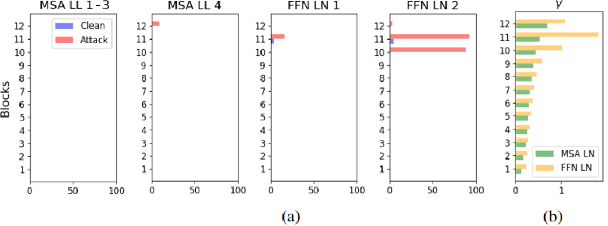
In recent years, there has been a significant trend in deep neural networks (DNNs), particularly transformer-based models, of developing ever-larger and more capable models. While they demonstrate state-of-the-art performance, their growing scale requires increased computational resources (e.g., GPUs with greater memory capacity). To address this problem, quantization techniques (i.e., low-bit-precision representation and matrix multiplication) have been proposed. Most quantization techniques employ a static strategy in which the model parameters are quantized, either during training or inference, without considering the test-time sample. In contrast, dynamic quantization techniques, which have become increasingly popular, adapt during inference based on the input provided, while maintaining full-precision performance. However, their dynamic behavior and average-case performance assumption makes them vulnerable to a novel threat vector -- adversarial attacks that target the model's efficiency and availability. In this paper, we present QuantAttack, a novel attack that targets the availability of quantized models, slowing down the inference, and increasing memory usage and energy consumption. We show that carefully crafted adversarial examples, which are designed to exhaust the resources of the operating system, can trigger worst-case performance. In our experiments, we demonstrate the effectiveness of our attack on vision transformers on a wide range of tasks, both uni-modal and multi-modal. We also examine the effect of different attack variants (e.g., a universal perturbation) and the transferability between different models.