 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounding-box Watermarking: Defense against Model Extraction Attacks on Object Detectors
Nov 20, 2024Deep neural networks (DNNs) deployed in a cloud often allow users to query models via the APIs. However, these APIs expose the models to model extraction attacks (MEAs). In this attack, the attacker attempts to duplicate the target model by abusing the responses from the API. Backdoor-based DNN watermarking is known as a promising defense against MEAs, wherein the defender injects a backdoor into extracted models via API responses. The backdoor is used as a watermark of the model; if a suspicious model has the watermark (i.e., backdoor), it is verified as an extracted model. This work focuses on object detection (OD) models. Existing backdoor attacks on OD models are not applicable for model watermarking as the defense against MEAs on a realistic threat model. Our proposed approach involves inserting a backdoor into extracted models via APIs by stealthily modifying the bounding-boxes (BBs) of objects detected in queries while keeping the OD capability. In our experiments on three OD datasets, the proposed approach succeeded in identifying the extracted models with 100% accuracy in a wide variety of experimental scenarios.
X-Detect: Explainable Adversarial Patch Detection for Object Detectors in Retail
Jul 02, 2023
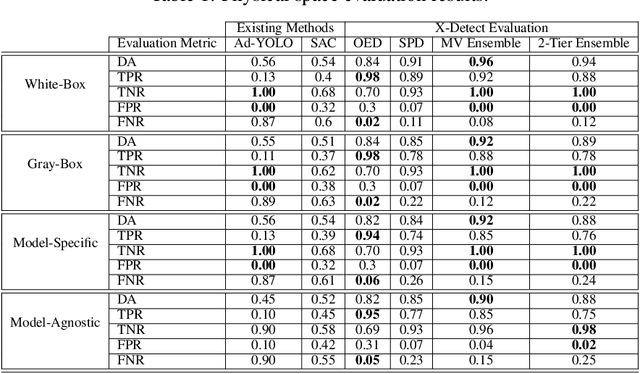


Object detection models, which are widely used in various domains (such as retail), have been shown to be vulnerable to adversarial attacks. Existing methods for detecting adversarial attacks on object detectors have had difficulty detecting new real-life attacks. We present X-Detect, a novel adversarial patch detector that can: i) detect adversarial samples in real time, allowing the defender to take preventive action; ii) provide explanations for the alerts raised to support the defender's decision-making process, and iii) handle unfamiliar threats in the form of new attacks. Given a new scene, X-Detect uses an ensemble of explainable-by-design detectors that utilize object extraction, scene manipulation, and feature transformation techniques to determine whether an alert needs to be raised. X-Detect was evaluated in both the physical and digital space using five different attack scenarios (including adaptive attacks) and the COCO dataset and our new Superstore dataset. The physical evaluation was performed using a smart shopping cart setup in real-world settings and included 17 adversarial patch attacks recorded in 1,700 adversarial videos. The results showed that X-Detect outperforms the state-of-the-art methods in distinguishing between benign and adversarial scenes for all attack scenarios while maintaining a 0% FPR (no false alarms) and providing actionable explanations for the alerts raised. A demo is available.
YolOOD: Utilizing Object Detection Concepts for Out-of-Distribution Detection
Dec 05, 2022



Out-of-distribution (OOD) detection has attracted a large amount of attention from the machine learning research community in recent years due to its importance in deployed systems. Most of the previous studies focused on the detection of OOD samples in the multi-class classification task. However, OOD detection in the multi-label classification task remains an underexplored domain. In this research, we propose YolOOD - a method that utilizes concepts from the object detection domain to perform OOD detection in the multi-label classification task. Object detection models have an inherent ability to distinguish between objects of interest (in-distribution) and irrelevant objects (e.g., OOD objects) on images that contain multiple objects from different categories. These abilities allow us to convert a regular object detection model into an image classifier with inherent OOD detection capabilities with just minor changes. We compare our approach to state-of-the-art OOD detection methods and demonstrate YolOOD's ability to outperform these methods on a comprehensive suite of in-distribution and OOD benchmark datasets.
Seeds Don't Lie: An Adaptive Watermarking Framework for Computer Vision Models
Nov 24, 2022
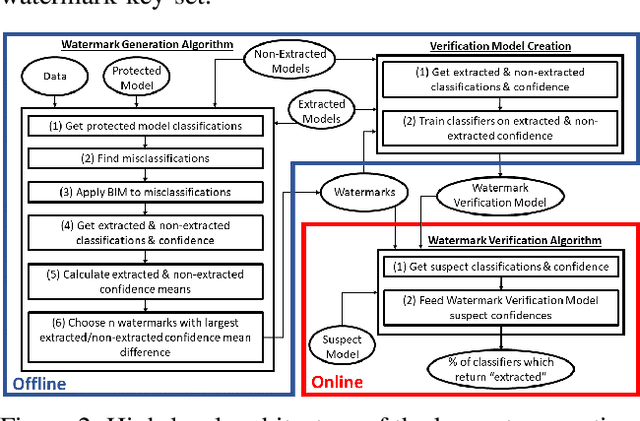
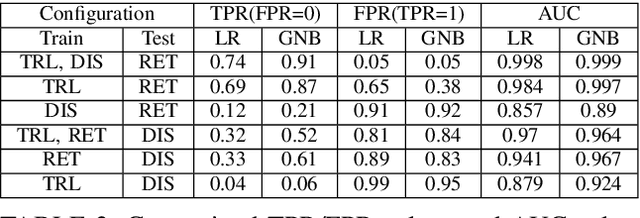

In recent years, various watermarking methods were suggested to detect computer vision models obtained illegitimately from their owners, however they fail to demonstrate satisfactory robustness against model extraction attacks. In this paper, we present an adaptive framework to watermark a protected model, leveraging the unique behavior present in the model due to a unique random seed initialized during the model training. This watermark is used to detect extracted models, which have the same unique behavior, indicating an unauthorized usage of the protected model's intellectual property (IP). First, we show how an initial seed for random number generation as part of model training produces distinct characteristics in the model's decision boundaries, which are inherited by extracted models and present in their decision boundaries, but aren't present in non-extracted models trained on the same data-set with a different seed. Based on our findings, we suggest the Robust Adaptive Watermarking (RAW) Framework, which utilizes the unique behavior present in the protected and extracted models to generate a watermark key-set and verification model. We show that the framework is robust to (1) unseen model extraction attacks, and (2) extracted models which undergo a blurring method (e.g., weight pruning). We evaluate the framework's robustness against a naive attacker (unaware that the model is watermarked), and an informed attacker (who employs blurring strategies to remove watermarked behavior from an extracted model), and achieve outstanding (i.e., >0.9) AUC values. Finally, we show that the framework is robust to model extraction attacks with different structure and/or architecture than the protected model.
First to Possess His Statistics: Data-Free Model Extraction Attack on Tabular Data
Sep 30, 2021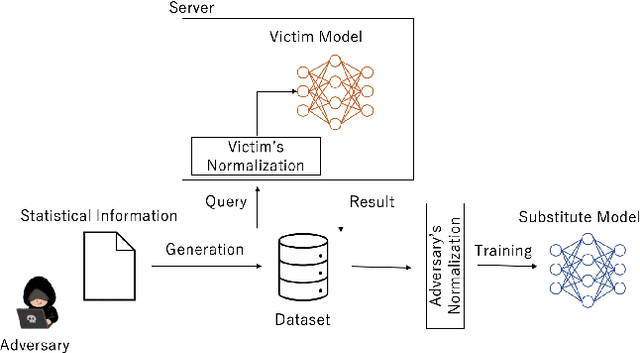
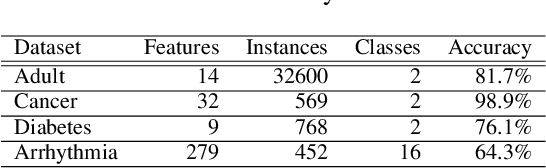
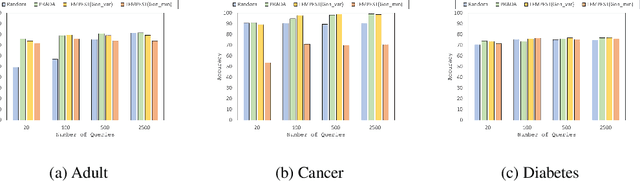

Model extraction attacks are a kind of attacks where an adversary obtains a machine learning model whose performance is comparable with one of the victim model through queries and their results. This paper presents a novel model extraction attack, named TEMPEST, applicable on tabular data under a practical data-free setting. Whereas model extraction is more challenging on tabular data due to normalization, TEMPEST no longer needs initial samples that previous attacks require; instead, it makes use of publicly available statistics to generate query samples. Experiments show that our attack can achieve the same level of performance as the previous attacks. Moreover, we identify that the use of mean and variance as statistics for query generation and the use of the same normalization process as the victim model can improve the performance of our attack. We also discuss a possibility whereby TEMPEST is executed in the real world through an experiment with a medical diagnosis dataset. We plan to release the source code for reproducibility and a reference to subsequent works.