 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding BACnet Packets: A Large Language Model Approach for Packet Interpretation
Jul 22, 2024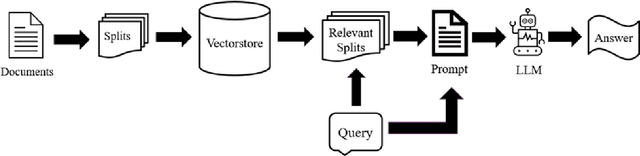

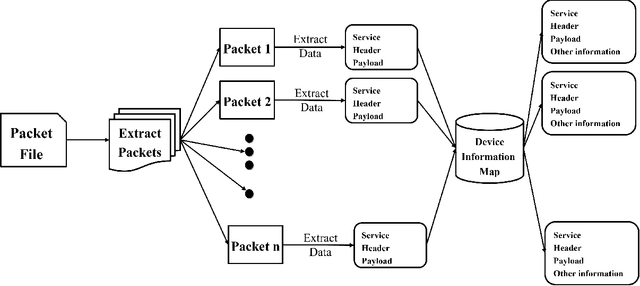
The Industrial Control System (ICS) environment encompasses a wide range of intricate communication protocols, posing substantial challenges for Security Operations Center (SOC) analysts tasked with monitoring, interpreting, and addressing network activities and security incidents. Conventional monitoring tools and techniques often struggle to provide a clear understanding of the nature and intent of ICS-specific communications. To enhance comprehension, we propose a software solution powered by a Large Language Model (LLM). This solution currently focused on BACnet protocol, processes a packet file data and extracts context by using a mapping database, and contemporary context retrieval methods for Retrieval Augmented Generation (RAG). The processed packet information, combined with the extracted context, serves as input to the LLM, which generates a concise packet file summary for the user. The software delivers a clear, coherent, and easily understandable summary of network activities, enabling SOC analysts to better assess the current state of the control system.
JABBERWOCK: A Tool for WebAssembly Dataset Generation and Its Application to Malicious Website Detection
Jun 09, 2023Machine learning is often used for malicious website detection, but an approach incorporating WebAssembly as a feature has not been explored due to a limited number of samples, to the best of our knowledge. In this paper, we propose JABBERWOCK (JAvascript-Based Binary EncodeR by WebAssembly Optimization paCKer), a tool to generate WebAssembly datasets in a pseudo fashion via JavaScript. Loosely speaking, JABBERWOCK automatically gathers JavaScript code in the real world, convert them into WebAssembly, and then outputs vectors of the WebAssembly as samples for malicious website detection. We also conduct experimental evaluations of JABBERWOCK in terms of the processing time for dataset generation, comparison of the generated samples with actual WebAssembly samples gathered from the Internet, and an application for malicious website detection. Regarding the processing time, we show that JABBERWOCK can construct a dataset in 4.5 seconds per sample for any number of samples. Next, comparing 10,000 samples output by JABBERWOCK with 168 gathered WebAssembly samples, we believe that the generated samples by JABBERWOCK are similar to those in the real world. We then show that JABBERWOCK can provide malicious website detection with 99\% F1-score because JABBERWOCK makes a gap between benign and malicious samples as the reason for the above high score. We also confirm that JABBERWOCK can be combined with an existing malicious website detection tool to improve F1-scores. JABBERWOCK is publicly available via GitHub (https://github.com/c-chocolate/Jabberwock).
Privacy-Preserving Taxi-Demand Prediction Using Federated Learning
May 21, 2023Taxi-demand prediction is an important application of machine learning that enables taxi-providing facilities to optimize their operations and city planners to improve transportation infrastructure and services. However, the use of sensitive data in these systems raises concerns about privacy and security. In this paper, we propose the use of federated learning for taxi-demand prediction that allows multiple parties to train a machine learning model on their own data while keeping the data private and secure. This can enable organizations to build models on data they otherwise would not be able to access. Evaluation with real-world data collected from 16 taxi service providers in Japan over a period of six months showed that the proposed system can predict the demand level accurately within 1\% error compared to a single model trained with integrated data.
Do Backdoors Assist Membership Inference Attacks?
Mar 22, 2023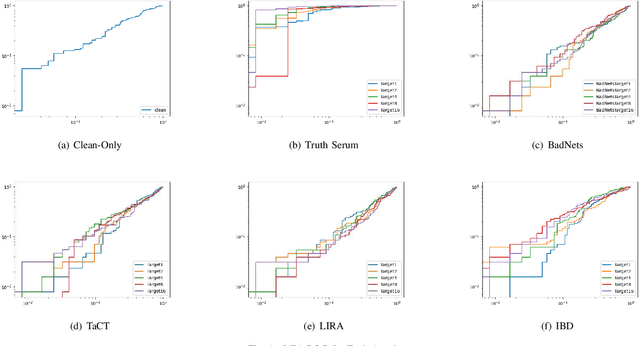
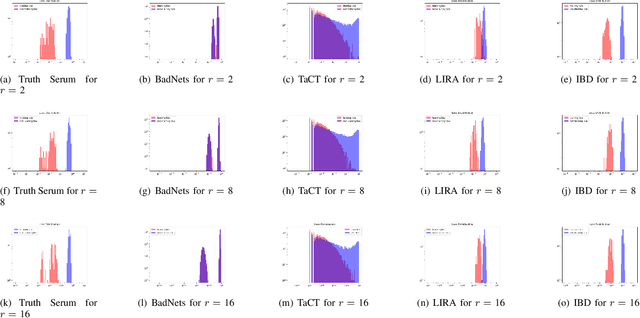
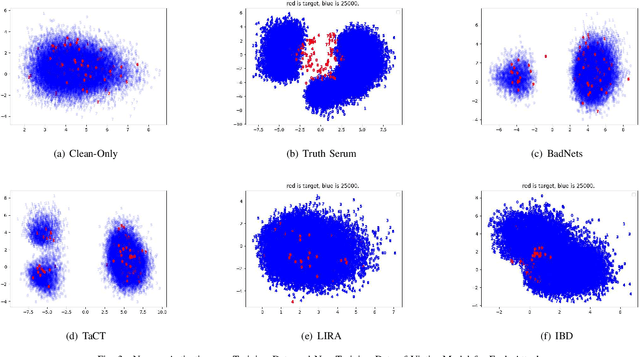

When an adversary provides poison samples to a machine learning model, privacy leakage, such as membership inference attacks that infer whether a sample was included in the training of the model, becomes effective by moving the sample to an outlier. However, the attacks can be detected because inference accuracy deteriorates due to poison samples. In this paper, we discuss a \textit{backdoor-assisted membership inference attack}, a novel membership inference attack based on backdoors that return the adversary's expected output for a triggered sample. We found three crucial insights through experiments with an academic benchmark dataset. We first demonstrate that the backdoor-assisted membership inference attack is unsuccessful. Second, when we analyzed loss distributions to understand the reason for the unsuccessful results, we found that backdoors cannot separate loss distributions of training and non-training samples. In other words, backdoors cannot affect the distribution of clean samples. Third, we also show that poison and triggered samples activate neurons of different distributions. Specifically, backdoors make any clean sample an inlier, contrary to poisoning samples. As a result, we confirm that backdoors cannot assist membership inference.
Membership Inference Attacks against Diffusion Models
Feb 07, 2023Diffusion models have attracted attention in recent years as innovative generative models. In this paper, we investigate whether a diffusion model is resistant to a membership inference attack, which evaluates the privacy leakage of a machine learning model. We primarily discuss the diffusion model from the standpoints of comparison with a generative adversarial network (GAN) as conventional models and hyperparameters unique to the diffusion model, i.e., time steps, sampling steps, and sampling variances. We conduct extensive experiments with DDIM as a diffusion model and DCGAN as a GAN on the CelebA and CIFAR-10 datasets in both white-box and black-box settings and then confirm if the diffusion model is comparably resistant to a membership inference attack as GAN. Next, we demonstrate that the impact of time steps is significant and intermediate steps in a noise schedule are the most vulnerable to the attack. We also found two key insights through further analysis. First, we identify that DDIM is vulnerable to the attack for small sample sizes instead of achieving a lower FID. Second, sampling steps in hyperparameters are important for resistance to the attack, whereas the impact of sampling variances is quite limited.
First to Possess His Statistics: Data-Free Model Extraction Attack on Tabular Data
Sep 30, 2021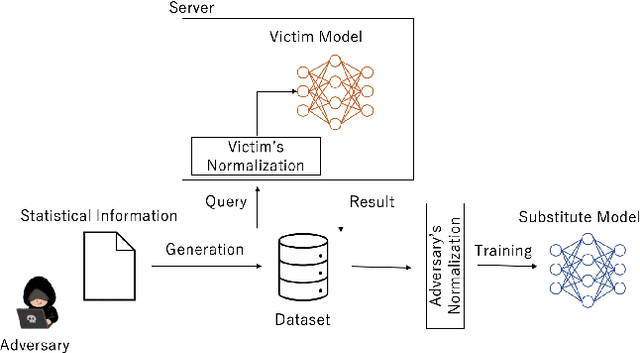
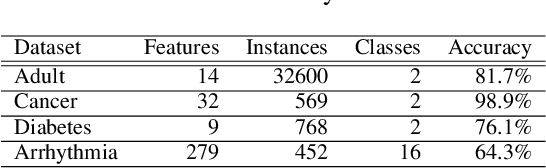
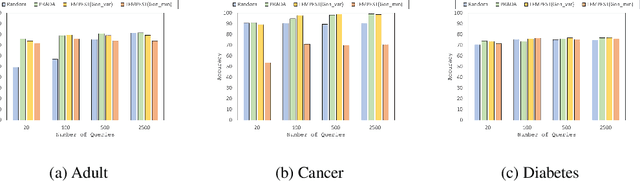

Model extraction attacks are a kind of attacks where an adversary obtains a machine learning model whose performance is comparable with one of the victim model through queries and their results. This paper presents a novel model extraction attack, named TEMPEST, applicable on tabular data under a practical data-free setting. Whereas model extraction is more challenging on tabular data due to normalization, TEMPEST no longer needs initial samples that previous attacks require; instead, it makes use of publicly available statistics to generate query samples. Experiments show that our attack can achieve the same level of performance as the previous attacks. Moreover, we identify that the use of mean and variance as statistics for query generation and the use of the same normalization process as the victim model can improve the performance of our attack. We also discuss a possibility whereby TEMPEST is executed in the real world through an experiment with a medical diagnosis dataset. We plan to release the source code for reproducibility and a reference to subsequent works.
Eth2Vec: Learning Contract-Wide Code Representations for Vulnerability Detection on Ethereum Smart Contracts
Jan 08, 2021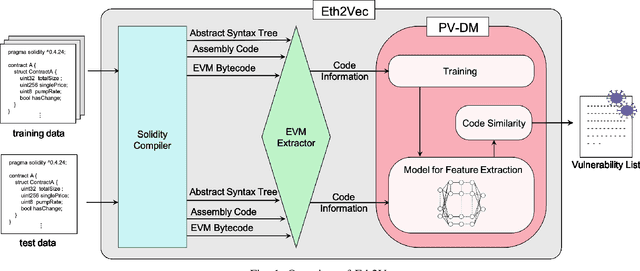
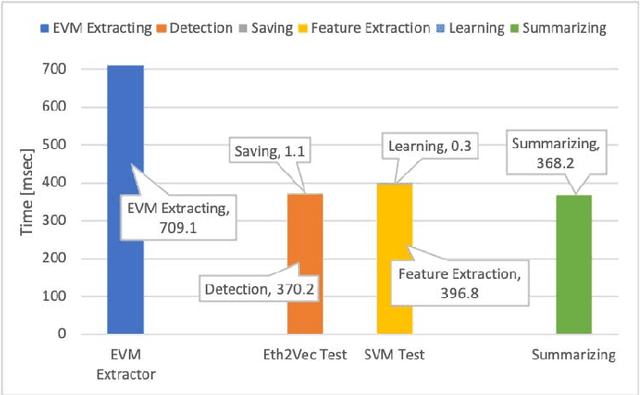
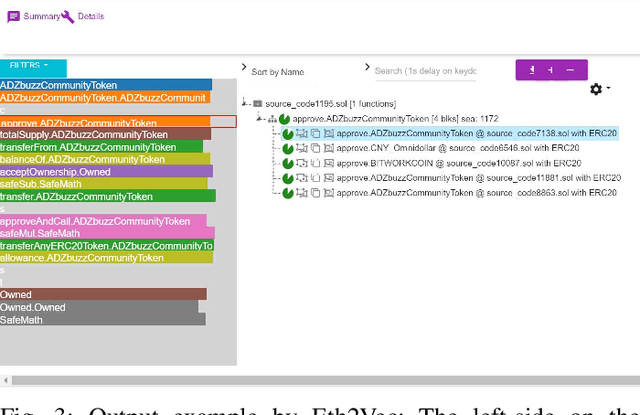

Ethereum smart contracts are programs that run on the Ethereum blockchain, and many smart contract vulnerabilities have been discovered in the past decade. Many security analysis tools have been created to detect such vulnerabilities, but their performance decreases drastically when codes to be analyzed are being rewritten. In this paper, we propose Eth2Vec, a machine-learning-based static analysis tool for vulnerability detection, with robustness against code rewrites in smart contracts. Existing machine-learning-based static analysis tools for vulnerability detection need features, which analysts create manually, as inputs. In contrast, Eth2Vec automatically learns features of vulnerable Ethereum Virtual Machine (EVM) bytecodes with tacit knowledge through a neural network for language processing. Therefore, Eth2Vec can detect vulnerabilities in smart contracts by comparing the code similarity between target EVM bytecodes and the EVM bytecodes it already learned. We conducted experiments with existing open databases, such as Etherscan, and our results show that Eth2Vec outperforms the existing work in terms of well-known metrics, i.e., precision, recall, and F1-score. Moreover, Eth2Vec can detect vulnerabilities even in rewritten codes.
Self-Organizing Map assisted Deep Autoencoding Gaussian Mixture Model for Intrusion Detection
Aug 28, 2020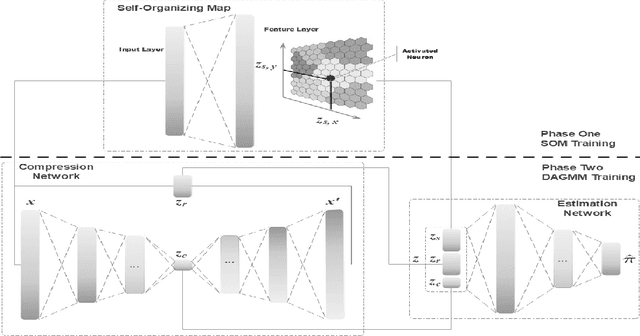
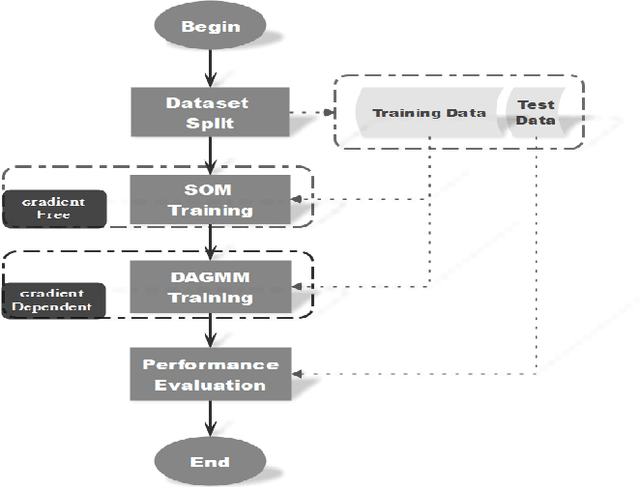
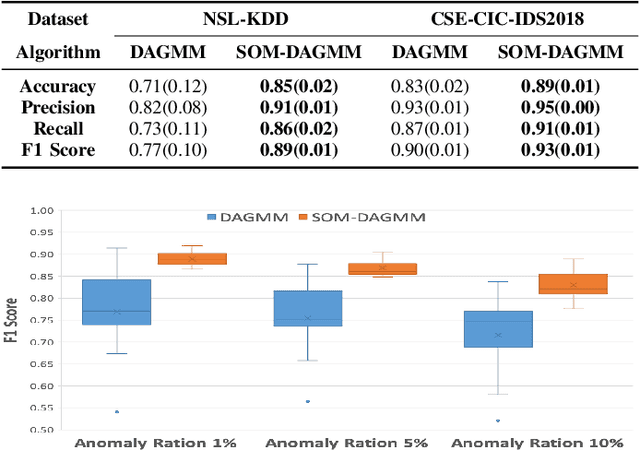
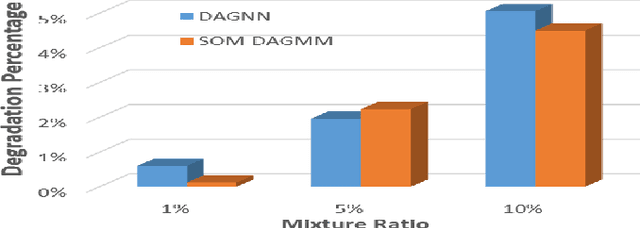
In the information age, a secure and stable network environment is essential and hence intrusion detection is critical for any networks. In this paper, we propose a self-organizing map assisted deep autoencoding Gaussian mixture model (SOMDAGMM) supplemented with well-preserved input space topology for more accurate network intrusion detection. The deep autoencoding Gaussian mixture model comprises a compression network and an estimation network which is able to perform unsupervised joint training. However, the code generated by the autoencoder is inept at preserving the topology of the input space, which is rooted in the bottleneck of the adopted deep structure. A self-organizing map has been introduced to construct SOMDAGMM for addressing this issue. The superiority of the proposed SOM-DAGMM is empirically demonstrated with extensive experiments conducted upon two datasets. Experimental results show that SOM-DAGMM outperforms state-of-the-art DAGMM on all tests, and achieves up to 15.58% improvement in F1 score and with better stability.
Model Extraction Attacks against Recurrent Neural Networks
Feb 01, 2020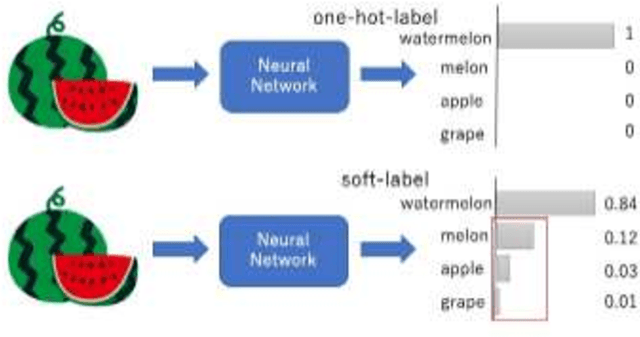
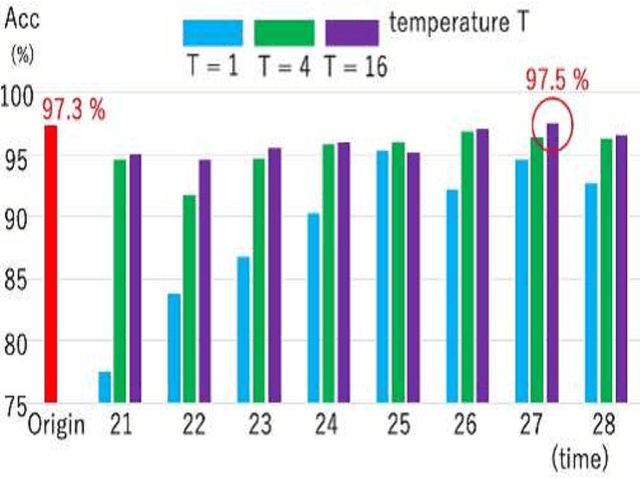
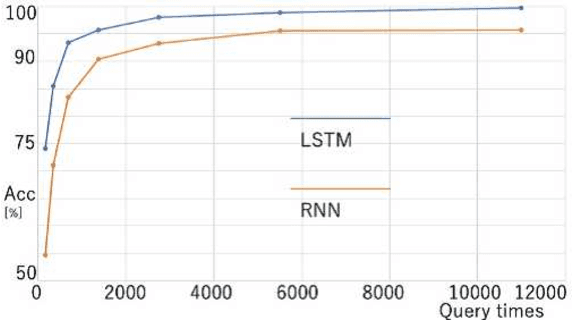
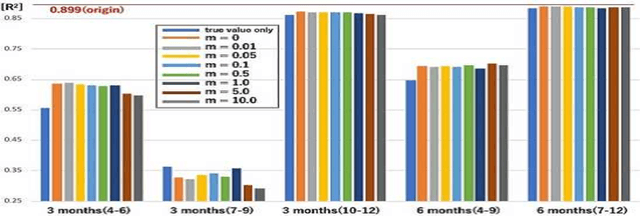
Model extraction attacks are a kind of attacks in which an adversary obtains a new model, whose performance is equivalent to that of a target model, via query access to the target model efficiently, i.e., fewer datasets and computational resources than those of the target model. Existing works have dealt with only simple deep neural networks (DNNs), e.g., only three layers, as targets of model extraction attacks, and hence are not aware of the effectiveness of recurrent neural networks (RNNs) in dealing with time-series data. In this work, we shed light on the threats of model extraction attacks against RNNs. We discuss whether a model with a higher accuracy can be extracted with a simple RNN from a long short-term memory (LSTM), which is a more complicated and powerful RNN. Specifically, we tackle the following problems. First, in a case of a classification problem, such as image recognition, extraction of an RNN model without final outputs from an LSTM model is presented by utilizing outputs halfway through the sequence. Next, in a case of a regression problem. such as in weather forecasting, a new attack by newly configuring a loss function is presented. We conduct experiments on our model extraction attacks against an RNN and an LSTM trained with publicly available academic datasets. We then show that a model with a higher accuracy can be extracted efficiently, especially through configuring a loss function and a more complex architecture different from the target model.
MOBIUS: Model-Oblivious Binarized Neural Networks
Nov 29, 2018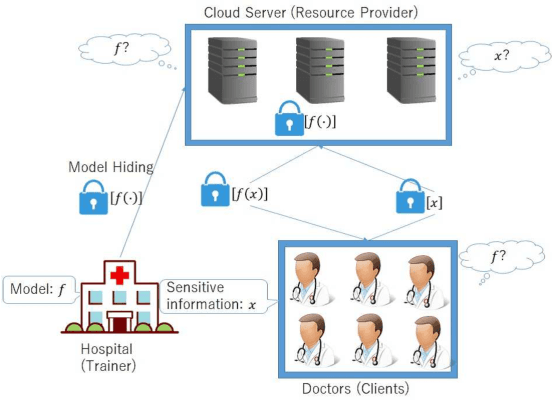
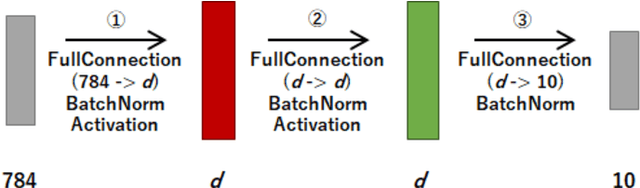
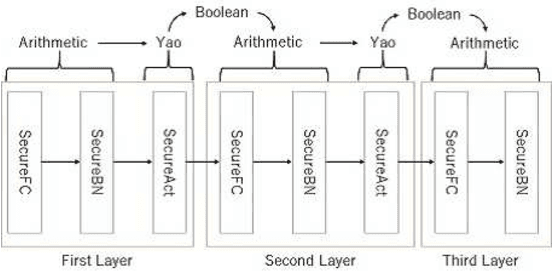
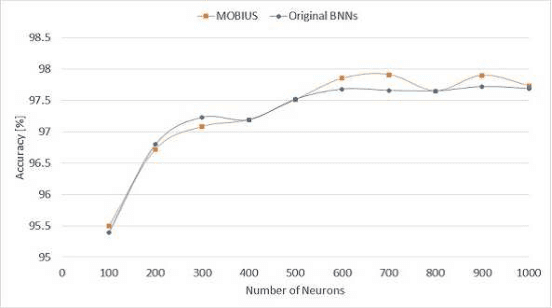
A privacy-preserving framework in which a computational resource provider receives encrypted data from a client and returns prediction results without decrypting the data, i.e., oblivious neural network or encrypted prediction, has been studied in machine learning that provides prediction services. In this work, we present MOBIUS (Model-Oblivious BInary neUral networkS), a new system that combines Binarized Neural Networks (BNNs) and secure computation based on secret sharing as tools for scalable and fast privacy-preserving machine learning. BNNs improve computational performance by binarizing values in training to $-1$ and $+1$, while secure computation based on secret sharing provides fast and various computations under encrypted forms via modulo operations with a short bit length. However, combining these tools is not trivial because their operations have different algebraic structures and the use of BNNs downgrades prediction accuracy in general. MOBIUS uses improved procedures of BNNs and secure computation that have compatible algebraic structures without downgrading prediction accuracy. We created an implementation of MOBIUS in C++ using the ABY library (NDSS 2015). We then conducted experiments using the MNIST dataset, and the results show that MOBIUS can return a prediction within 0.76 seconds, which is six times faster than SecureML (IEEE S\&P 2017). MOBIUS allows a client to request for encrypted prediction and allows a trainer to obliviously publish an encrypted model to a cloud provided by a computational resource provider, i.e., without revealing the original model itself to the provider.