 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Backdoor Removal by Reconstructing Trigger-Activated Changes in Latent Representation
Nov 12, 2025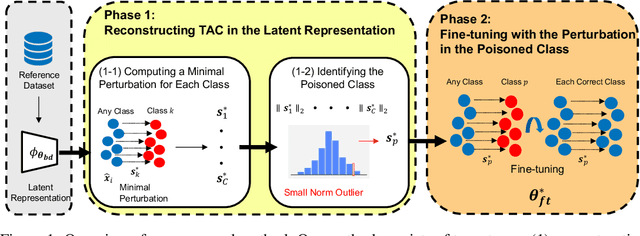
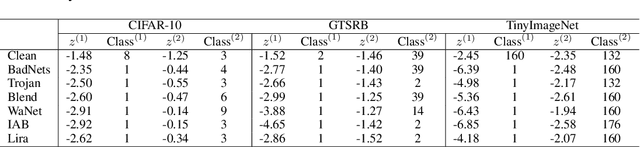
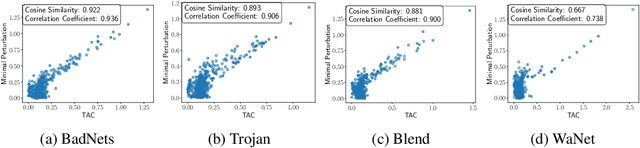
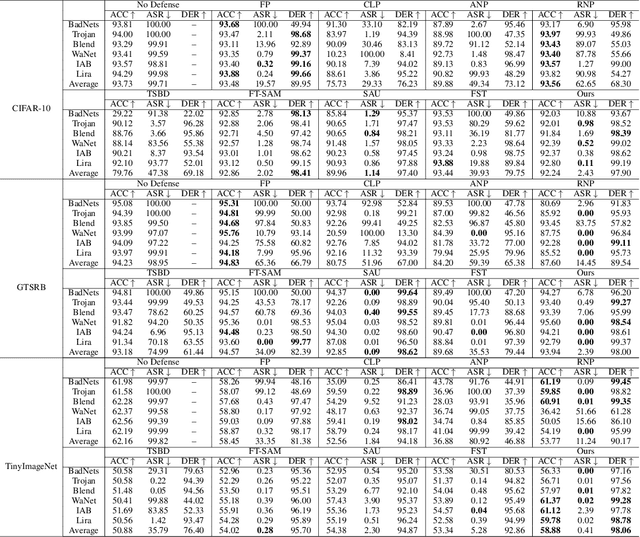
Backdoor attacks pose a critical threat to machine learning models, causing them to behave normally on clean data but misclassify poisoned data into a poisoned class. Existing defenses often attempt to identify and remove backdoor neurons based on Trigger-Activated Changes (TAC) which is the activation differences between clean and poisoned data. These methods suffer from low precision in identifying true backdoor neurons due to inaccurate estimation of TAC values. In this work, we propose a novel backdoor removal method by accurately reconstructing TAC values in the latent representation. Specifically, we formulate the minimal perturbation that forces clean data to be classified into a specific class as a convex quadratic optimization problem, whose optimal solution serves as a surrogate for TAC. We then identify the poisoned class by detecting statistically small $L^2$ norms of perturbations and leverage the perturbation of the poisoned class in fine-tuning to remove backdoors. Experiments on CIFAR-10, GTSRB, and TinyImageNet demonstrated that our approach consistently achieves superior backdoor suppression with high clean accuracy across different attack types, datasets, and architectures, outperforming existing defense methods.
Concept Unlearning in Large Language Models via Self-Constructed Knowledge Triplets
Sep 19, 2025Machine Unlearning (MU) has recently attracted considerable attention as a solution to privacy and copyright issues in large language models (LLMs). Existing MU methods aim to remove specific target sentences from an LLM while minimizing damage to unrelated knowledge. However, these approaches require explicit target sentences and do not support removing broader concepts, such as persons or events. To address this limitation, we introduce Concept Unlearning (CU) as a new requirement for LLM unlearning. We leverage knowledge graphs to represent the LLM's internal knowledge and define CU as removing the forgetting target nodes and associated edges. This graph-based formulation enables a more intuitive unlearning and facilitates the design of more effective methods. We propose a novel method that prompts the LLM to generate knowledge triplets and explanatory sentences about the forgetting target and applies the unlearning process to these representations. Our approach enables more precise and comprehensive concept removal by aligning the unlearning process with the LLM's internal knowledge representations. Experiments on real-world and synthetic datasets demonstrate that our method effectively achieves concept-level unlearning while preserving unrelated knowledge.
Sparse-Autoencoder-Guided Internal Representation Unlearning for Large Language Models
Sep 19, 2025As large language models (LLMs) are increasingly deployed across various applications, privacy and copyright concerns have heightened the need for more effective LLM unlearning techniques. Many existing unlearning methods aim to suppress undesirable outputs through additional training (e.g., gradient ascent), which reduces the probability of generating such outputs. While such suppression-based approaches can control model outputs, they may not eliminate the underlying knowledge embedded in the model's internal activations; muting a response is not the same as forgetting it. Moreover, such suppression-based methods often suffer from model collapse. To address these issues, we propose a novel unlearning method that directly intervenes in the model's internal activations. In our formulation, forgetting is defined as a state in which the activation of a forgotten target is indistinguishable from that of ``unknown'' entities. Our method introduces an unlearning objective that modifies the activation of the target entity away from those of known entities and toward those of unknown entities in a sparse autoencoder latent space. By aligning the target's internal activation with those of unknown entities, we shift the model's recognition of the target entity from ``known'' to ``unknown'', achieving genuine forgetting while avoiding over-suppression and model collapse. Empirically, we show that our method effectively aligns the internal activations of the forgotten target, a result that the suppression-based approaches do not reliably achieve. Additionally, our method effectively reduces the model's recall of target knowledge in question-answering tasks without significant damage to the non-target knowledge.
Do Backdoors Assist Membership Inference Attacks?
Mar 22, 2023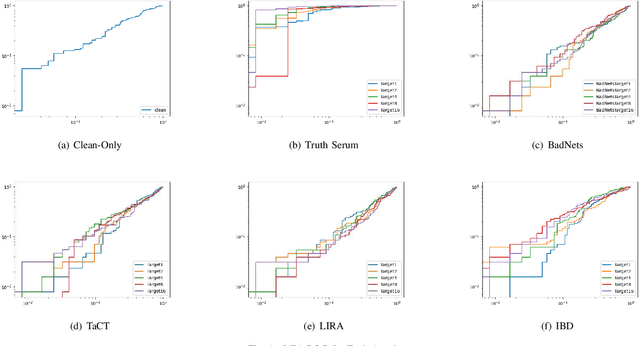
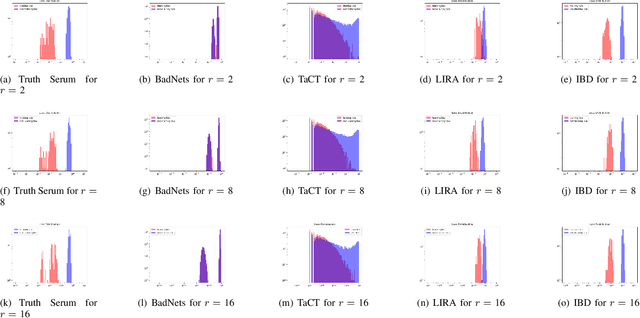
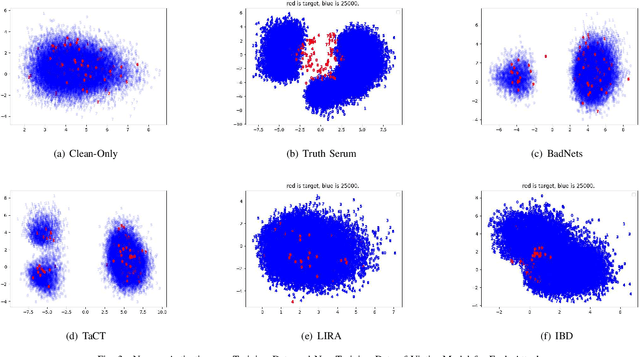

When an adversary provides poison samples to a machine learning model, privacy leakage, such as membership inference attacks that infer whether a sample was included in the training of the model, becomes effective by moving the sample to an outlier. However, the attacks can be detected because inference accuracy deteriorates due to poison samples. In this paper, we discuss a \textit{backdoor-assisted membership inference attack}, a novel membership inference attack based on backdoors that return the adversary's expected output for a triggered sample. We found three crucial insights through experiments with an academic benchmark dataset. We first demonstrate that the backdoor-assisted membership inference attack is unsuccessful. Second, when we analyzed loss distributions to understand the reason for the unsuccessful results, we found that backdoors cannot separate loss distributions of training and non-training samples. In other words, backdoors cannot affect the distribution of clean samples. Third, we also show that poison and triggered samples activate neurons of different distributions. Specifically, backdoors make any clean sample an inlier, contrary to poisoning samples. As a result, we confirm that backdoors cannot assist membership inference.
MEGEX: Data-Free Model Extraction Attack against Gradient-Based Explainable AI
Jul 19, 2021



The advance of explainable artificial intelligence, which provides reasons for its predictions, is expected to accelerate the use of deep neural networks in the real world like Machine Learning as a Service (MLaaS) that returns predictions on queried data with the trained model. Deep neural networks deployed in MLaaS face the threat of model extraction attacks. A model extraction attack is an attack to violate intellectual property and privacy in which an adversary steals trained models in a cloud using only their predictions. In particular, a data-free model extraction attack has been proposed recently and is more critical. In this attack, an adversary uses a generative model instead of preparing input data. The feasibility of this attack, however, needs to be studied since it requires more queries than that with surrogate datasets. In this paper, we propose MEGEX, a data-free model extraction attack against a gradient-based explainable AI. In this method, an adversary uses the explanations to train the generative model and reduces the number of queries to steal the model. Our experiments show that our proposed method reconstructs high-accuracy models -- 0.97$\times$ and 0.98$\times$ the victim model accuracy on SVHN and CIFAR-10 datasets given 2M and 20M queries, respectively. This implies that there is a trade-off between the interpretability of models and the difficulty of stealing them.