 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPSQL+: A Differentially Private SQL Library with a Minimum Frequency Rule
Feb 26, 2026SQL is the de facto interface for exploratory data analysis; however, releasing exact query results can expose sensitive information through membership or attribute inference attacks. Differential privacy (DP) provides rigorous privacy guarantees, but in practice, DP alone may not satisfy governance requirements such as the \emph{minimum frequency rule}, which requires each released group (cell) to include contributions from at least $k$ distinct individuals. In this paper, we present \textbf{DPSQL+}, a privacy-preserving SQL library that simultaneously enforces user-level $(\varepsilon,δ)$-DP and the minimum frequency rule. DPSQL+ adopts a modular architecture consisting of: (i) a \emph{Validator} that statically restricts queries to a DP-safe subset of SQL; (ii) an \emph{Accountant} that consistently tracks cumulative privacy loss across multiple queries; and (iii) a \emph{Backend} that interfaces with various database engines, ensuring portability and extensibility. Experiments on the TPC-H benchmark demonstrate that DPSQL+ achieves practical accuracy across a wide range of analytical workloads -- from basic aggregates to quadratic statistics and join operations -- and allows substantially more queries under a fixed global privacy budget than prior libraries in our evaluation.
Securing Private Federated Learning in a Malicious Setting: A Scalable TEE-Based Approach with Client Auditing
Sep 10, 2025In cross-device private federated learning, differentially private follow-the-regularized-leader (DP-FTRL) has emerged as a promising privacy-preserving method. However, existing approaches assume a semi-honest server and have not addressed the challenge of securely removing this assumption. This is due to its statefulness, which becomes particularly problematic in practical settings where clients can drop out or be corrupted. While trusted execution environments (TEEs) might seem like an obvious solution, a straightforward implementation can introduce forking attacks or availability issues due to state management. To address this problem, our paper introduces a novel server extension that acts as a trusted computing base (TCB) to realize maliciously secure DP-FTRL. The TCB is implemented with an ephemeral TEE module on the server side to produce verifiable proofs of server actions. Some clients, upon being selected, participate in auditing these proofs with small additional communication and computational demands. This extension solution reduces the size of the TCB while maintaining the system's scalability and liveness. We provide formal proofs based on interactive differential privacy, demonstrating privacy guarantee in malicious settings. Finally, we experimentally show that our framework adds small constant overhead to clients in several realistic settings.
Optimal Variance and Covariance Estimation under Differential Privacy in the Add-Remove Model and Beyond
Sep 05, 2025In this paper, we study the problem of estimating the variance and covariance of datasets under differential privacy in the add-remove model. While estimation in the swap model has been extensively studied in the literature, the add-remove model remains less explored and more challenging, as the dataset size must also be kept private. To address this issue, we develop efficient mechanisms for variance and covariance estimation based on the \emph{B\'{e}zier mechanism}, a novel moment-release framework that leverages Bernstein bases. We prove that our proposed mechanisms are minimax optimal in the high-privacy regime by establishing new minimax lower bounds. Moreover, beyond worst-case scenarios, we analyze instance-wise utility and show that the B\'{e}zier-based estimator consistently achieves better utility compared to alternative mechanisms. Finally, we demonstrate the effectiveness of the B\'{e}zier mechanism beyond variance and covariance estimation, showcasing its applicability to other statistical tasks.
FedDuA: Doubly Adaptive Federated Learning
May 16, 2025Federated learning is a distributed learning framework where clients collaboratively train a global model without sharing their raw data. FedAvg is a popular algorithm for federated learning, but it often suffers from slow convergence due to the heterogeneity of local datasets and anisotropy in the parameter space. In this work, we formalize the central server optimization procedure through the lens of mirror descent and propose a novel framework, called FedDuA, which adaptively selects the global learning rate based on both inter-client and coordinate-wise heterogeneity in the local updates. We prove that our proposed doubly adaptive step-size rule is minimax optimal and provide a convergence analysis for convex objectives. Although the proposed method does not require additional communication or computational cost on clients, extensive numerical experiments show that our proposed framework outperforms baselines in various settings and is robust to the choice of hyperparameters.
Accelerating Differentially Private Federated Learning via Adaptive Extrapolation
Apr 14, 2025



The federated learning (FL) framework enables multiple clients to collaboratively train machine learning models without sharing their raw data, but it remains vulnerable to privacy attacks. One promising approach is to incorporate differential privacy (DP)-a formal notion of privacy-into the FL framework. DP-FedAvg is one of the most popular algorithms for DP-FL, but it is known to suffer from the slow convergence in the presence of heterogeneity among clients' data. Most of the existing methods to accelerate DP-FL require 1) additional hyperparameters or 2) additional computational cost for clients, which is not desirable since 1) hyperparameter tuning is computationally expensive and data-dependent choice of hyperparameters raises the risk of privacy leakage, and 2) clients are often resource-constrained. To address this issue, we propose DP-FedEXP, which adaptively selects the global step size based on the diversity of the local updates without requiring any additional hyperparameters or client computational cost. We show that DP-FedEXP provably accelerates the convergence of DP-FedAvg and it empirically outperforms existing methods tailored for DP-FL.
Shuffled Check-in: Privacy Amplification towards Practical Distributed Learning
Jun 07, 2022
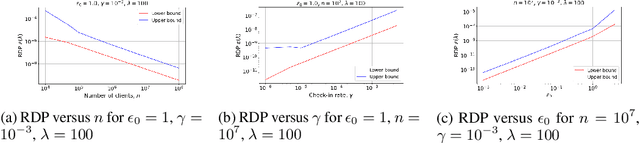

Recent studies of distributed computation with formal privacy guarantees, such as differentially private (DP) federated learning, leverage random sampling of clients in each round (privacy amplification by subsampling) to achieve satisfactory levels of privacy. Achieving this however requires strong assumptions which may not hold in practice, including precise and uniform subsampling of clients, and a highly trusted aggregator to process clients' data. In this paper, we explore a more practical protocol, shuffled check-in, to resolve the aforementioned issues. The protocol relies on client making independent and random decision to participate in the computation, freeing the requirement of server-initiated subsampling, and enabling robust modelling of client dropouts. Moreover, a weaker trust model known as the shuffle model is employed instead of using a trusted aggregator. To this end, we introduce new tools to characterize the R\'enyi differential privacy (RDP) of shuffled check-in. We show that our new techniques improve at least three times in privacy guarantee over those using approximate DP's strong composition at various parameter regimes. Furthermore, we provide a numerical approach to track the privacy of generic shuffled check-in mechanism including distributed stochastic gradient descent (SGD) with Gaussian mechanism. To the best of our knowledge, this is also the first evaluation of Gaussian mechanism within the local/shuffle model under the distributed setting in the literature, which can be of independent interest.
MEGEX: Data-Free Model Extraction Attack against Gradient-Based Explainable AI
Jul 19, 2021



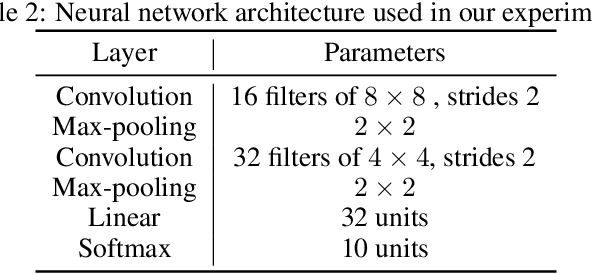
The advance of explainable artificial intelligence, which provides reasons for its predictions, is expected to accelerate the use of deep neural networks in the real world like Machine Learning as a Service (MLaaS) that returns predictions on queried data with the trained model. Deep neural networks deployed in MLaaS face the threat of model extraction attacks. A model extraction attack is an attack to violate intellectual property and privacy in which an adversary steals trained models in a cloud using only their predictions. In particular, a data-free model extraction attack has been proposed recently and is more critical. In this attack, an adversary uses a generative model instead of preparing input data. The feasibility of this attack, however, needs to be studied since it requires more queries than that with surrogate datasets. In this paper, we propose MEGEX, a data-free model extraction attack against a gradient-based explainable AI. In this method, an adversary uses the explanations to train the generative model and reduces the number of queries to steal the model. Our experiments show that our proposed method reconstructs high-accuracy models -- 0.97$\times$ and 0.98$\times$ the victim model accuracy on SVHN and CIFAR-10 datasets given 2M and 20M queries, respectively. This implies that there is a trade-off between the interpretability of models and the difficulty of stealing them.