 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Shuffling Beyond Pure Local Differential Privacy
Jan 27, 2026Shuffling is a powerful way to amplify privacy of a local randomizer in private distributed data analysis, but existing analyses mostly treat the local differential privacy (DP) parameter $\varepsilon_0$ as the only knob and give generic upper bounds that can be loose and do not even characterize how shuffling amplifies privacy for basic mechanisms such as the Gaussian mechanism. We revisit the privacy blanket bound of Balle et al. (the blanket divergence) and develop an asymptotic analysis that applies to a broad class of local randomizers under mild regularity assumptions, without requiring pure local DP. Our key finding is that the leading term of the blanket divergence depends on the local mechanism only through a single scalar parameter $χ$, which we call the shuffle index. By applying this asymptotic analysis to both upper and lower bounds, we obtain a tight band for $δ_n$ in the shuffled mechanism's $(\varepsilon_n,δ_n)$-DP guarantee. Moreover, we derive a simple structural necessary and sufficient condition on the local randomizer under which the blanket-divergence-based upper and lower bounds coincide asymptotically. $k$-RR families with $k\ge3$ satisfy this condition, while for generalized Gaussian mechanisms the condition may not hold but the resulting band remains tight. Finally, we complement the asymptotic theory with an FFT-based algorithm for computing the blanket divergence at finite $n$, which offers rigorously controlled relative error and near-linear running time in $n$, providing a practical numerical analysis for shuffle DP.
Towards Principled Design of Mixture-of-Experts Language Models under Memory and Inference Constraints
Jan 13, 2026Modern Mixture-of-Experts (MoE) language models are designed based on total parameters (memory footprint) and active parameters (inference cost). However, we find these two factors alone are insufficient to describe an optimal architecture. Through a systematic study, we demonstrate that MoE performance is primarily determined by total parameters ($N_{total}$) and expert sparsity ($s:=n_{exp}/n_{topk}$). Moreover, $n_{exp}$ and $n_{topk}$ do not "cancel out" within the sparsity ratio; instead, a larger total number of experts slightly penalizes performance by forcing a reduction in core model dimensions (depth and width) to meet memory constraints. This motivates a simple principle for MoE design which maximizes $N_{total}$ while minimizing $s$ (maximizing $n_{topk}$) and $n_{exp}$ under the given constraints. Our findings provide a robust framework for resolving architectural ambiguity and guiding MoE design.
Optimal Variance and Covariance Estimation under Differential Privacy in the Add-Remove Model and Beyond
Sep 05, 2025In this paper, we study the problem of estimating the variance and covariance of datasets under differential privacy in the add-remove model. While estimation in the swap model has been extensively studied in the literature, the add-remove model remains less explored and more challenging, as the dataset size must also be kept private. To address this issue, we develop efficient mechanisms for variance and covariance estimation based on the \emph{B\'{e}zier mechanism}, a novel moment-release framework that leverages Bernstein bases. We prove that our proposed mechanisms are minimax optimal in the high-privacy regime by establishing new minimax lower bounds. Moreover, beyond worst-case scenarios, we analyze instance-wise utility and show that the B\'{e}zier-based estimator consistently achieves better utility compared to alternative mechanisms. Finally, we demonstrate the effectiveness of the B\'{e}zier mechanism beyond variance and covariance estimation, showcasing its applicability to other statistical tasks.
FedDuA: Doubly Adaptive Federated Learning
May 16, 2025Federated learning is a distributed learning framework where clients collaboratively train a global model without sharing their raw data. FedAvg is a popular algorithm for federated learning, but it often suffers from slow convergence due to the heterogeneity of local datasets and anisotropy in the parameter space. In this work, we formalize the central server optimization procedure through the lens of mirror descent and propose a novel framework, called FedDuA, which adaptively selects the global learning rate based on both inter-client and coordinate-wise heterogeneity in the local updates. We prove that our proposed doubly adaptive step-size rule is minimax optimal and provide a convergence analysis for convex objectives. Although the proposed method does not require additional communication or computational cost on clients, extensive numerical experiments show that our proposed framework outperforms baselines in various settings and is robust to the choice of hyperparameters.
Accelerating Differentially Private Federated Learning via Adaptive Extrapolation
Apr 14, 2025



The federated learning (FL) framework enables multiple clients to collaboratively train machine learning models without sharing their raw data, but it remains vulnerable to privacy attacks. One promising approach is to incorporate differential privacy (DP)-a formal notion of privacy-into the FL framework. DP-FedAvg is one of the most popular algorithms for DP-FL, but it is known to suffer from the slow convergence in the presence of heterogeneity among clients' data. Most of the existing methods to accelerate DP-FL require 1) additional hyperparameters or 2) additional computational cost for clients, which is not desirable since 1) hyperparameter tuning is computationally expensive and data-dependent choice of hyperparameters raises the risk of privacy leakage, and 2) clients are often resource-constrained. To address this issue, we propose DP-FedEXP, which adaptively selects the global step size based on the diversity of the local updates without requiring any additional hyperparameters or client computational cost. We show that DP-FedEXP provably accelerates the convergence of DP-FedAvg and it empirically outperforms existing methods tailored for DP-FL.
Scaling Laws for Upcycling Mixture-of-Experts Language Models
Feb 05, 2025



Pretraining large language models (LLMs) is resource-intensive, often requiring months of training time even with high-end GPU clusters. There are two approaches of mitigating such computational demands: reusing smaller models to train larger ones (upcycling), and training computationally efficient models like mixture-of-experts (MoE). In this paper, we study the upcycling of LLMs to MoE models, of which the scaling behavior remains underexplored. Through extensive experiments, we identify empirical scaling laws that describe how performance depends on dataset size and model configuration. Particularly, we show that, while scaling these factors improves performance, there is a novel interaction term between the dense and upcycled training dataset that limits the efficiency of upcycling at large computational budgets. Based on these findings, we provide guidance to scale upcycling, and establish conditions under which upcycling outperforms from-scratch trainings within budget constraints.
Scaling Private Deep Learning with Low-Rank and Sparse Gradients
Jul 06, 2022

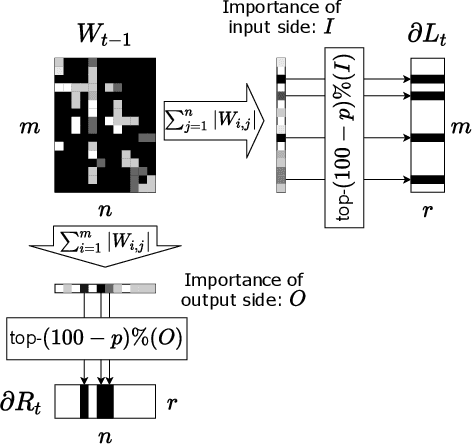
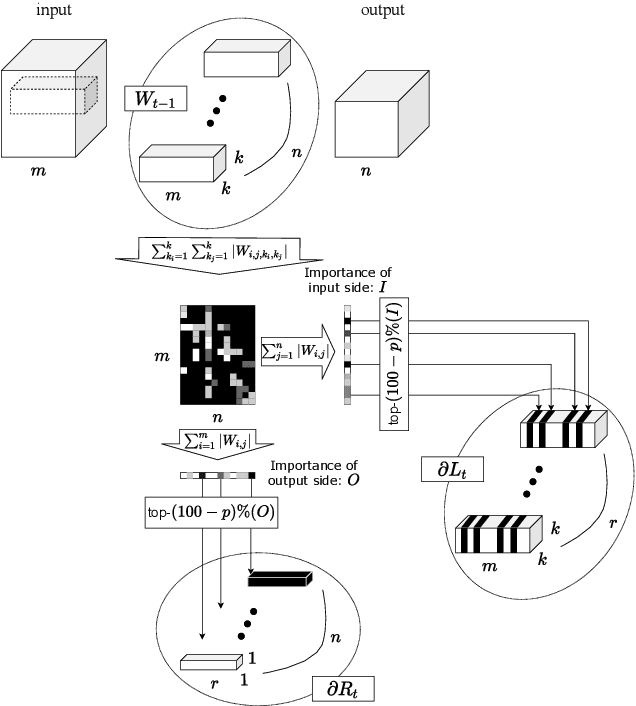
Applying Differentially Private Stochastic Gradient Descent (DPSGD) to training modern, large-scale neural networks such as transformer-based models is a challenging task, as the magnitude of noise added to the gradients at each iteration scales with model dimension, hindering the learning capability significantly. We propose a unified framework, $\textsf{LSG}$, that fully exploits the low-rank and sparse structure of neural networks to reduce the dimension of gradient updates, and hence alleviate the negative impacts of DPSGD. The gradient updates are first approximated with a pair of low-rank matrices. Then, a novel strategy is utilized to sparsify the gradients, resulting in low-dimensional, less noisy updates that are yet capable of retaining the performance of neural networks. Empirical evaluation on natural language processing and computer vision tasks shows that our method outperforms other state-of-the-art baselines.
Shuffle Gaussian Mechanism for Differential Privacy
Jul 04, 2022
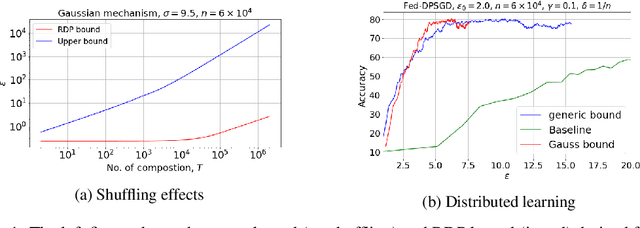
We study Gaussian mechanism in the shuffle model of differential privacy (DP). Particularly, we characterize the mechanism's R\'enyi differential privacy (RDP), showing that it is of the form: $$ \epsilon(\lambda) \leq \frac{1}{\lambda-1}\log\left(\frac{e^{-\lambda/2\sigma^2}}{n^\lambda}\sum_{\substack{k_1+\dotsc+k_n=\lambda;\\k_1,\dotsc,k_n\geq 0}}\binom{\lambda}{k_1,\dotsc,k_n}e^{\sum_{i=1}^nk_i^2/2\sigma^2}\right) $$ We further prove that the RDP is strictly upper-bounded by the Gaussian RDP without shuffling. The shuffle Gaussian RDP is advantageous in composing multiple DP mechanisms, where we demonstrate its improvement over the state-of-the-art approximate DP composition theorems in privacy guarantees of the shuffle model. Moreover, we extend our study to the subsampled shuffle mechanism and the recently proposed shuffled check-in mechanism, which are protocols geared towards distributed/federated learning. Finally, an empirical study of these mechanisms is given to demonstrate the efficacy of employing shuffle Gaussian mechanism under the distributed learning framework to guarantee rigorous user privacy.
Shuffled Check-in: Privacy Amplification towards Practical Distributed Learning
Jun 07, 2022
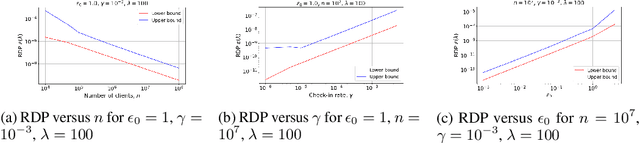

Recent studies of distributed computation with formal privacy guarantees, such as differentially private (DP) federated learning, leverage random sampling of clients in each round (privacy amplification by subsampling) to achieve satisfactory levels of privacy. Achieving this however requires strong assumptions which may not hold in practice, including precise and uniform subsampling of clients, and a highly trusted aggregator to process clients' data. In this paper, we explore a more practical protocol, shuffled check-in, to resolve the aforementioned issues. The protocol relies on client making independent and random decision to participate in the computation, freeing the requirement of server-initiated subsampling, and enabling robust modelling of client dropouts. Moreover, a weaker trust model known as the shuffle model is employed instead of using a trusted aggregator. To this end, we introduce new tools to characterize the R\'enyi differential privacy (RDP) of shuffled check-in. We show that our new techniques improve at least three times in privacy guarantee over those using approximate DP's strong composition at various parameter regimes. Furthermore, we provide a numerical approach to track the privacy of generic shuffled check-in mechanism including distributed stochastic gradient descent (SGD) with Gaussian mechanism. To the best of our knowledge, this is also the first evaluation of Gaussian mechanism within the local/shuffle model under the distributed setting in the literature, which can be of independent interest.
Network Shuffling: Privacy Amplification via Random Walks
Apr 08, 2022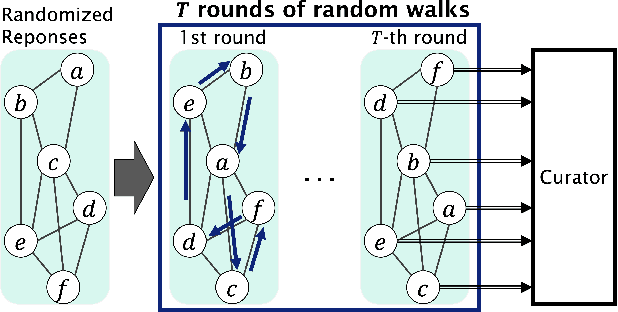

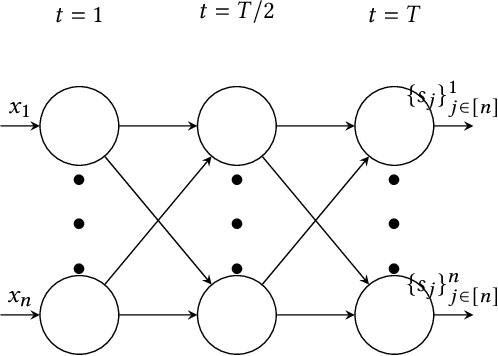
Recently, it is shown that shuffling can amplify the central differential privacy guarantees of data randomized with local differential privacy. Within this setup, a centralized, trusted shuffler is responsible for shuffling by keeping the identities of data anonymous, which subsequently leads to stronger privacy guarantees for systems. However, introducing a centralized entity to the originally local privacy model loses some appeals of not having any centralized entity as in local differential privacy. Moreover, implementing a shuffler in a reliable way is not trivial due to known security issues and/or requirements of advanced hardware or secure computation technology. Motivated by these practical considerations, we rethink the shuffle model to relax the assumption of requiring a centralized, trusted shuffler. We introduce network shuffling, a decentralized mechanism where users exchange data in a random-walk fashion on a network/graph, as an alternative of achieving privacy amplification via anonymity. We analyze the threat model under such a setting, and propose distributed protocols of network shuffling that is straightforward to implement in practice. Furthermore, we show that the privacy amplification rate is similar to other privacy amplification techniques such as uniform shuffling. To our best knowledge, among the recently studied intermediate trust models that leverage privacy amplification techniques, our work is the first that is not relying on any centralized entity to achieve privacy amplification.