 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training LLM without Learning Rate Decay Enhances Supervised Fine-Tuning
Mar 17, 2026We investigate the role of learning rate scheduling in the large-scale pre-training of large language models, focusing on its influence on downstream performance after supervised fine-tuning (SFT). Decay-based learning rate schedulers are widely used to minimize pre-training loss. However, despite their widespread use, how these schedulers affect performance after SFT remains underexplored. In this paper, we examine Warmup-Stable-Only (WSO), which maintains a constant learning rate after warmup without any decay. Through experiments with 1B and 8B parameter models, we show that WSO consistently outperforms decay-based schedulers in terms of performance after SFT, even though decay-based schedulers may exhibit better performance after pre-training. The result also holds across different regimes with mid-training and over-training. Loss landscape analysis further reveals that decay-based schedulers lead models into sharper minima, whereas WSO preserves flatter minima that support adaptability. These findings indicate that applying LR decay to improve pre-training metrics may compromise downstream adaptability. Our work also provides practical guidance for training and model release strategies, highlighting that pre-training models with WSO enhances their adaptability for downstream tasks.
Natural Fingerprints of Large Language Models
Apr 21, 2025
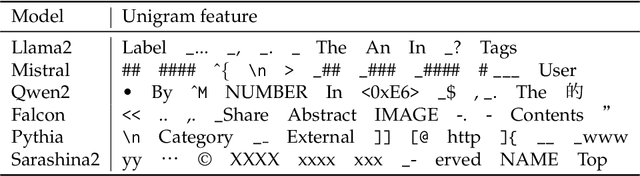
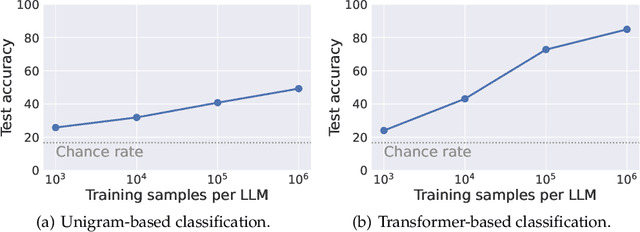

Large language models (LLMs) often exhibit biases -- systematic deviations from expected norms -- in their outputs. These range from overt issues, such as unfair responses, to subtler patterns that can reveal which model produced them. We investigate the factors that give rise to identifiable characteristics in LLMs. Since LLMs model training data distribution, it is reasonable that differences in training data naturally lead to the characteristics. However, our findings reveal that even when LLMs are trained on the exact same data, it is still possible to distinguish the source model based on its generated text. We refer to these unintended, distinctive characteristics as natural fingerprints. By systematically controlling training conditions, we show that the natural fingerprints can emerge from subtle differences in the training process, such as parameter sizes, optimization settings, and even random seeds. We believe that understanding natural fingerprints offers new insights into the origins of unintended bias and ways for improving control over LLM behavior.
Efficient Construction of Model Family through Progressive Training Using Model Expansion
Apr 01, 2025As Large Language Models (LLMs) gain widespread practical application, providing the model family of different parameter sizes has become standard practice to address diverse computational requirements. Conventionally, each model in a family is trained independently, resulting in computational costs that scale additively with the number of models. We propose an efficient method for constructing the model family through progressive training, where smaller models are incrementally expanded to larger sizes to create a complete model family. Through extensive experiments with a model family ranging from 1B to 8B parameters, we demonstrate that our method reduces computational costs by approximately 25% while maintaining comparable performance to independently trained models. Furthermore, by strategically adjusting maximum learning rates based on model size, our method outperforms the independent training across various metrics. Beyond performance gains, our approach offers an additional advantage: models in our family tend to yield more consistent behavior across different model sizes.
Scaling Laws for Upcycling Mixture-of-Experts Language Models
Feb 05, 2025



Pretraining large language models (LLMs) is resource-intensive, often requiring months of training time even with high-end GPU clusters. There are two approaches of mitigating such computational demands: reusing smaller models to train larger ones (upcycling), and training computationally efficient models like mixture-of-experts (MoE). In this paper, we study the upcycling of LLMs to MoE models, of which the scaling behavior remains underexplored. Through extensive experiments, we identify empirical scaling laws that describe how performance depends on dataset size and model configuration. Particularly, we show that, while scaling these factors improves performance, there is a novel interaction term between the dense and upcycled training dataset that limits the efficiency of upcycling at large computational budgets. Based on these findings, we provide guidance to scale upcycling, and establish conditions under which upcycling outperforms from-scratch trainings within budget constraints.
Self-Translate-Train: A Simple but Strong Baseline for Cross-lingual Transfer of Large Language Models
Jun 29, 2024Cross-lingual transfer is a promising technique for utilizing data in a source language to improve performance in a target language. However, current techniques often require an external translation system or suffer from suboptimal performance due to over-reliance on cross-lingual generalization of multi-lingual pretrained language models. In this study, we propose a simple yet effective method called Self-Translate-Train. It leverages the translation capability of a large language model to generate synthetic training data in the target language and fine-tunes the model with its own generated data. We evaluate the proposed method on a wide range of tasks and show substantial performance gains across several non-English languages.
Large Vocabulary Size Improves Large Language Models
Jun 24, 2024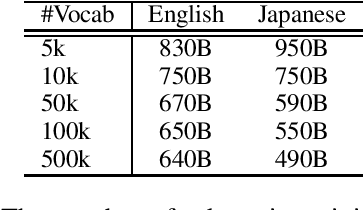
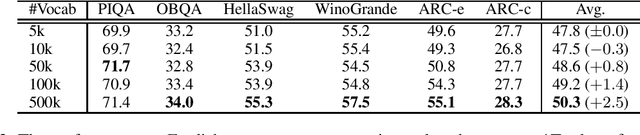
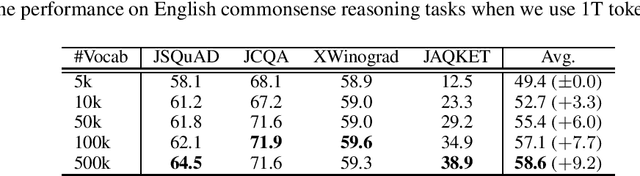

This paper empirically investigates the relationship between subword vocabulary size and the performance of large language models (LLMs) to provide insights on how to define the vocabulary size. Experimental results show that larger vocabulary sizes lead to better performance in LLMs. Moreover, we consider a continual training scenario where a pre-trained language model is trained on a different target language. We introduce a simple method to use a new vocabulary instead of the pre-defined one. We show that using the new vocabulary outperforms the model with the vocabulary used in pre-training.
Spike No More: Stabilizing the Pre-training of Large Language Models
Dec 28, 2023



The loss spike often occurs during pre-training of a large language model. The spikes degrade the performance of a large language model, and sometimes ruin the pre-training. Since the pre-training needs a vast computational budget, we should avoid such spikes. To investigate a cause of loss spikes, we focus on gradients of internal layers in this study. Through theoretical analyses, we introduce two causes of the exploding gradients, and provide requirements to prevent the explosion. In addition, we introduce the combination of the initialization method and a simple modification to embeddings as a method to satisfy the requirements. We conduct various experiments to verify our theoretical analyses empirically. Experimental results indicate that the combination is effective in preventing spikes during pre-training.
Exploring Effectiveness of GPT-3 in Grammatical Error Correction: A Study on Performance and Controllability in Prompt-Based Methods
May 29, 2023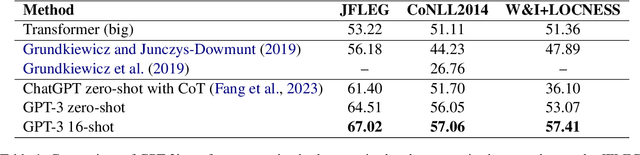
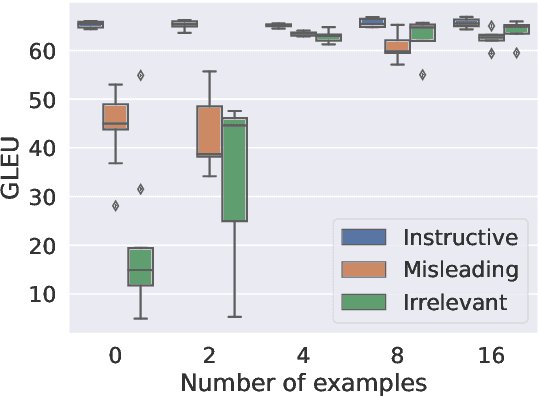
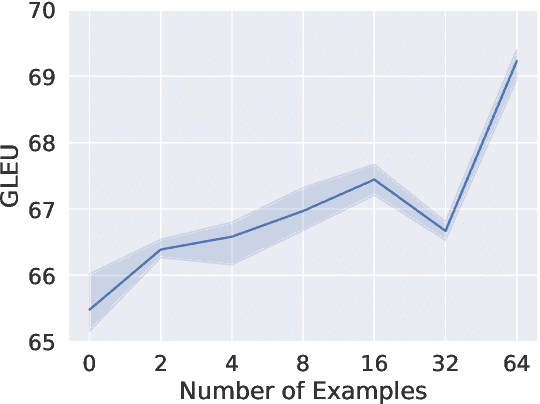
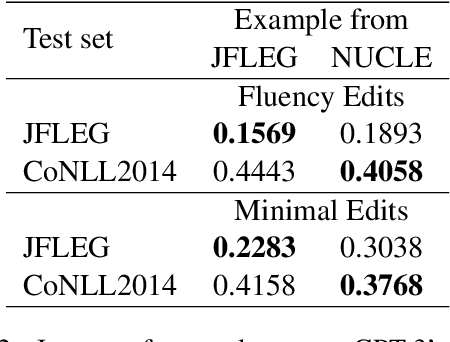
Large-scale pre-trained language models such as GPT-3 have shown remarkable performance across various natural language processing tasks. However, applying prompt-based methods with GPT-3 for Grammatical Error Correction (GEC) tasks and their controllability remains underexplored. Controllability in GEC is crucial for real-world applications, particularly in educational settings, where the ability to tailor feedback according to learner levels and specific error types can significantly enhance the learning process. This paper investigates the performance and controllability of prompt-based methods with GPT-3 for GEC tasks using zero-shot and few-shot setting. We explore the impact of task instructions and examples on GPT-3's output, focusing on controlling aspects such as minimal edits, fluency edits, and learner levels. Our findings demonstrate that GPT-3 could effectively perform GEC tasks, outperforming existing supervised and unsupervised approaches. We also showed that GPT-3 could achieve controllability when appropriate task instructions and examples are given.
Nearest Neighbor Non-autoregressive Text Generation
Aug 26, 2022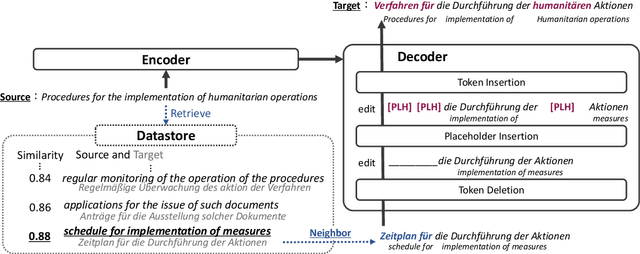
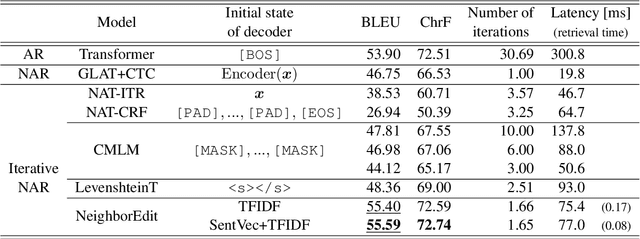

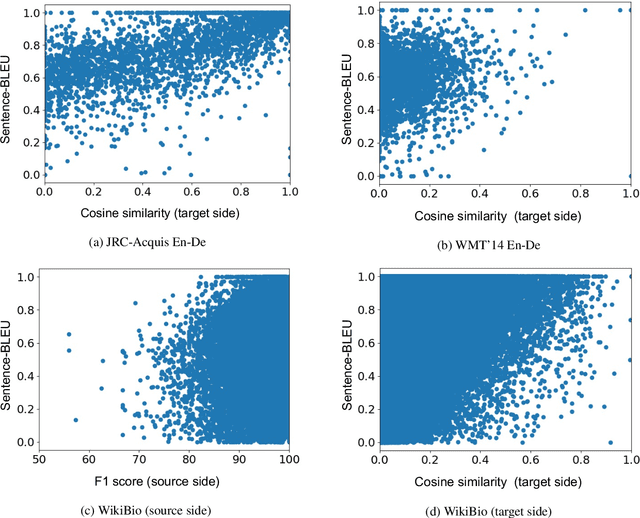
Non-autoregressive (NAR) models can generate sentences with less computation than autoregressive models but sacrifice generation quality. Previous studies addressed this issue through iterative decoding. This study proposes using nearest neighbors as the initial state of an NAR decoder and editing them iteratively. We present a novel training strategy to learn the edit operations on neighbors to improve NAR text generation. Experimental results show that the proposed method (NeighborEdit) achieves higher translation quality (1.69 points higher than the vanilla Transformer) with fewer decoding iterations (one-eighteenth fewer iterations) on the JRC-Acquis En-De dataset, the common benchmark dataset for machine translation using nearest neighbors. We also confirm the effectiveness of the proposed method on a data-to-text task (WikiBio). In addition, the proposed method outperforms an NAR baseline on the WMT'14 En-De dataset. We also report analysis on neighbor examples used in the proposed method.
Are Neighbors Enough? Multi-Head Neural n-gram can be Alternative to Self-attention
Jul 27, 2022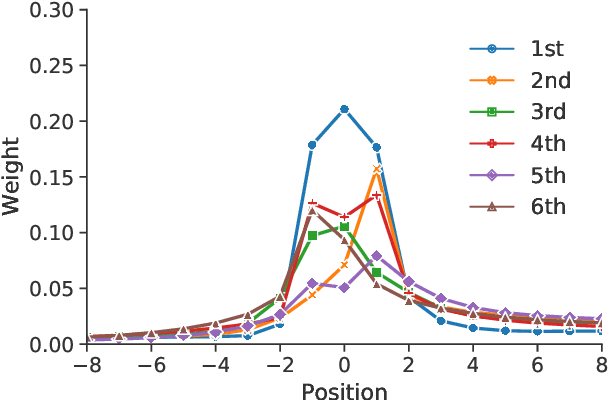
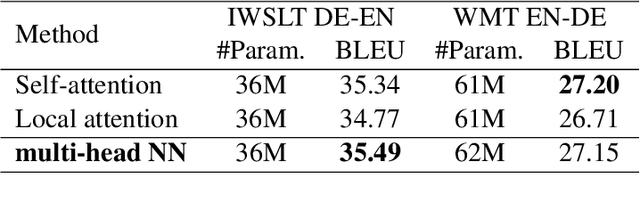
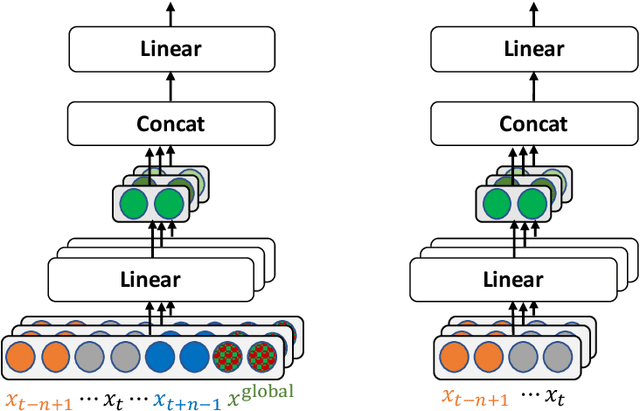
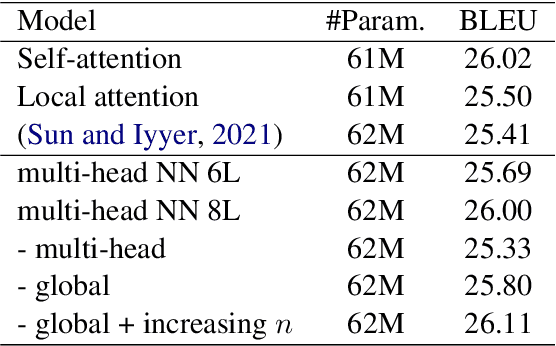
Impressive performance of Transformer has been attributed to self-attention, where dependencies between entire input in a sequence are considered at every position. In this work, we reform the neural $n$-gram model, which focuses on only several surrounding representations of each position, with the multi-head mechanism as in Vaswani et al.(2017). Through experiments on sequence-to-sequence tasks, we show that replacing self-attention in Transformer with multi-head neural $n$-gram can achieve comparable or better performance than Transformer. From various analyses on our proposed method, we find that multi-head neural $n$-gram is complementary to self-attention, and their combinations can further improve performance of vanilla Transformer.