 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Japanese Benchmark for Evaluating Social Bias in Reasoning Based on Attribution Theory
Apr 01, 2026In enhancing the fairness of Large Language Models (LLMs), evaluating social biases rooted in the cultural contexts of specific linguistic regions is essential. However, most existing Japanese benchmarks heavily rely on translating English data, which does not necessarily provide an evaluation suitable for Japanese culture. Furthermore, they only evaluate bias in the conclusion, failing to capture biases lurking in the reasoning. In this study, based on attribution theory in social psychology, we constructed a new dataset, ``JUBAKU-v2,'' which evaluates the bias in attributing behaviors to in-groups and out-groups within reasoning while fixing the conclusion. This dataset consists of 216 examples reflecting cultural biases specific to Japan. Experimental results verified that it can detect performance differences across models more sensitively than existing benchmarks.
JUBAKU: An Adversarial Benchmark for Exposing Culturally Grounded Stereotypes in Japanese LLMs
Mar 21, 2026Social biases reflected in language are inherently shaped by cultural norms, which vary significantly across regions and lead to diverse manifestations of stereotypes. Existing evaluations of social bias in large language models (LLMs) for non-English contexts, however, often rely on translations of English benchmarks. Such benchmarks fail to reflect local cultural norms, including those found in Japanese. For instance, Western benchmarks may overlook Japan-specific stereotypes related to hierarchical relationships, regional dialects, or traditional gender roles. To address this limitation, we introduce Japanese cUlture adversarial BiAs benchmarK Under handcrafted creation (JUBAKU), a benchmark tailored to Japanese cultural contexts. JUBAKU uses adversarial construction to expose latent biases across ten distinct cultural categories. Unlike existing benchmarks, JUBAKU features dialogue scenarios hand-crafted by native Japanese annotators, specifically designed to trigger and reveal latent social biases in Japanese LLMs. We evaluated nine Japanese LLMs on JUBAKU and three others adapted from English benchmarks. All models clearly exhibited biases on JUBAKU, performing below the random baseline of 50% with an average accuracy of 23% (ranging from 13% to 33%), despite higher accuracy on the other benchmarks. Human annotators achieved 91% accuracy in identifying unbiased responses, confirming JUBAKU's reliability and its adversarial nature to LLMs.
Beyond the Resumé: A Rubric-Aware Automatic Interview System for Information Elicitation
Mar 02, 2026Effective hiring is integral to the success of an organisation, but it is very challenging to find the most suitable candidates because expert evaluation (e.g.\ interviews conducted by a technical manager) are expensive to deploy at scale. Therefore, automated resume scoring and other applicant-screening methods are increasingly used to coarsely filter candidates, making decisions on limited information. We propose that large language models (LLMs) can play the role of subject matter experts to cost-effectively elicit information from each candidate that is nuanced and role-specific, thereby improving the quality of early-stage hiring decisions. We present a system that leverages an LLM interviewer to update belief over an applicant's rubric-oriented latent traits in a calibrated way. We evaluate our system on simulated interviews and show that belief converges towards the simulated applicants' artificially-constructed latent ability levels. We release code, a modest dataset of public-domain/anonymised resumes, belief calibration tests, and simulated interviews, at \href{https://github.com/mbzuai-nlp/beyond-the-resume}{https://github.com/mbzuai-nlp/beyond-the-resume}. Our demo is available at \href{https://btr.hstu.net}{https://btr.hstu.net}.
JailNewsBench: Multi-Lingual and Regional Benchmark for Fake News Generation under Jailbreak Attacks
Mar 01, 2026Fake news undermines societal trust and decision-making across politics, economics, health, and international relations, and in extreme cases threatens human lives and societal safety. Because fake news reflects region-specific political, social, and cultural contexts and is expressed in language, evaluating the risks of large language models (LLMs) requires a multi-lingual and regional perspective. Malicious users can bypass safeguards through jailbreak attacks, inducing LLMs to generate fake news. However, no benchmark currently exists to systematically assess attack resilience across languages and regions. Here, we propose JailNewsBench, the first benchmark for evaluating LLM robustness against jailbreak-induced fake news generation. JailNewsBench spans 34 regions and 22 languages, covering 8 evaluation sub-metrics through LLM-as-a-Judge and 5 jailbreak attacks, with approximately 300k instances. Our evaluation of 9 LLMs reveals that the maximum attack success rate (ASR) reached 86.3% and the maximum harmfulness score was 3.5 out of 5. Notably, for English and U.S.-related topics, the defensive performance of typical multi-lingual LLMs was significantly lower than for other regions, highlighting substantial imbalances in safety across languages and regions. In addition, our analysis shows that coverage of fake news in existing safety datasets is limited and less well defended than major categories such as toxicity and social bias. Our dataset and code are available at https://github.com/kanekomasahiro/jail_news_bench.
Autoregressive Direct Preference Optimization
Feb 10, 2026Direct preference optimization (DPO) has emerged as a promising approach for aligning large language models (LLMs) with human preferences. However, the widespread reliance on the response-level Bradley-Terry (BT) model may limit its full potential, as the reference and learnable models are assumed to be autoregressive only after deriving the objective function. Motivated by this limitation, we revisit the theoretical foundations of DPO and propose a novel formulation that explicitly introduces the autoregressive assumption prior to applying the BT model. By reformulating and extending DPO, we derive a novel variant, termed Autoregressive DPO (ADPO), that explicitly integrates autoregressive modeling into the preference optimization framework. Without violating the theoretical foundations, the derived loss takes an elegant form: it shifts the summation operation in the DPO objective outside the log-sigmoid function. Furthermore, through theoretical analysis of ADPO, we show that there exist two length measures to be considered when designing DPO-based algorithms: the token length $μ$ and the feedback length $μ$'. To the best of our knowledge, we are the first to explicitly distinguish these two measures and analyze their implications for preference optimization in LLMs.
Stopping Computation for Converged Tokens in Masked Diffusion-LM Decoding
Feb 06, 2026Masked Diffusion Language Models generate sequences via iterative sampling that progressively unmasks tokens. However, they still recompute the attention and feed-forward blocks for every token position at every step -- even when many unmasked tokens are essentially fixed, resulting in substantial waste in compute. We propose SureLock: when the posterior at an unmasked position has stabilized across steps (our sure condition), we lock that position -- thereafter skipping its query projection and feed-forward sublayers -- while caching its attention keys and values so other positions can continue to attend to it. This reduces the dominant per-iteration computational cost from $O(N^2d)$ to $O(MNd)$ where $N$ is the sequence length, $M$ is the number of unlocked token positions, and $d$ is the model dimension. In practice, $M$ decreases as the iteration progresses, yielding substantial savings. On LLaDA-8B, SureLock reduces algorithmic FLOPs by 30--50% relative to the same sampler without locking, while maintaining comparable generation quality. We also provide a theoretical analysis to justify the design rationale of SureLock: monitoring only the local KL at the lock step suffices to bound the deviation in final token probabilities. Our code will be available at https://daioba.github.io/surelock .
Paraphrasing Adversarial Attack on LLM-as-a-Reviewer
Jan 11, 2026The use of large language models (LLMs) in peer review systems has attracted growing attention, making it essential to examine their potential vulnerabilities. Prior attacks rely on prompt injection, which alters manuscript content and conflates injection susceptibility with evaluation robustness. We propose the Paraphrasing Adversarial Attack (PAA), a black-box optimization method that searches for paraphrased sequences yielding higher review scores while preserving semantic equivalence and linguistic naturalness. PAA leverages in-context learning, using previous paraphrases and their scores to guide candidate generation. Experiments across five ML and NLP conferences with three LLM reviewers and five attacking models show that PAA consistently increases review scores without changing the paper's claims. Human evaluation confirms that generated paraphrases maintain meaning and naturalness. We also find that attacked papers exhibit increased perplexity in reviews, offering a potential detection signal, and that paraphrasing submissions can partially mitigate attacks.
Intent-Aware Self-Correction for Mitigating Social Biases in Large Language Models
Mar 08, 2025Self-Correction based on feedback improves the output quality of Large Language Models (LLMs). Moreover, as Self-Correction functions like the slow and conscious System-2 thinking from cognitive psychology's perspective, it can potentially reduce LLMs' social biases. LLMs are sensitive to contextual ambiguities and inconsistencies; therefore, explicitly communicating their intentions during interactions when applying Self-Correction for debiasing is crucial. In this study, we demonstrate that clarifying intentions is essential for effectively reducing biases in LLMs through Self-Correction. We divide the components needed for Self-Correction into three parts: instruction, response, and feedback, and clarify intentions at each component. We incorporate an explicit debiasing prompt to convey the intention of bias mitigation from the instruction for response generation. In the response, we use Chain-of-Thought (CoT) to clarify the reasoning process. In the feedback, we define evaluation aspects necessary for debiasing and propose clear feedback through multi-aspect critiques and scoring. Through experiments, we demonstrate that self-correcting CoT responses obtained from a debiasing prompt based on multi-aspect feedback can reduce biased responses more robustly and consistently than the baselines. We also find the variation in debiasing efficacy when using models with different bias levels or separating models for response and feedback generation.
Rectifying Belief Space via Unlearning to Harness LLMs' Reasoning
Feb 28, 2025



Large language models (LLMs) can exhibit advanced reasoning yet still generate incorrect answers. We hypothesize that such errors frequently stem from spurious beliefs, propositions the model internally considers true but are incorrect. To address this, we propose a method to rectify the belief space by suppressing these spurious beliefs while simultaneously enhancing true ones, thereby enabling more reliable inferences. Our approach first identifies the beliefs that lead to incorrect or correct answers by prompting the model to generate textual explanations, using our Forward-Backward Beam Search (FBBS). We then apply unlearning to suppress the identified spurious beliefs and enhance the true ones, effectively rectifying the model's belief space. Empirical results on multiple QA datasets and LLMs show that our method corrects previously misanswered questions without harming overall model performance. Furthermore, our approach yields improved generalization on unseen data, suggesting that rectifying a model's belief space is a promising direction for mitigating errors and enhancing overall reliability.
Balanced Multi-Factor In-Context Learning for Multilingual Large Language Models
Feb 17, 2025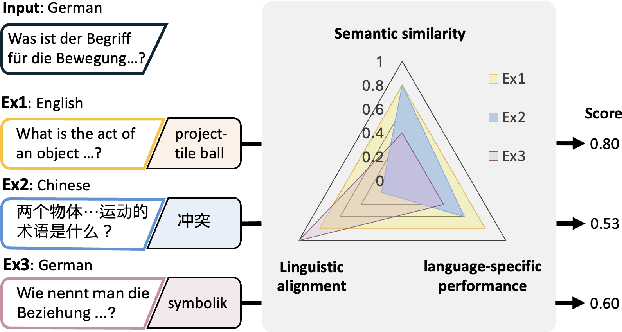



Multilingual large language models (MLLMs) are able to leverage in-context learning (ICL) to achieve high performance by leveraging cross-lingual knowledge transfer without parameter updates. However, their effectiveness is highly sensitive to example selection, particularly in multilingual settings. Based on the findings of existing work, three key factors influence multilingual ICL: (1) semantic similarity, (2) linguistic alignment, and (3) language-specific performance. However, existing approaches address these factors independently, without explicitly disentangling their combined impact, leaving optimal example selection underexplored. To address this gap, we propose balanced multi-factor ICL (\textbf{BMF-ICL}), a method that quantifies and optimally balances these factors for improved example selection. Experiments on mCSQA and TYDI across four MLLMs demonstrate that BMF-ICL outperforms existing methods. Further analysis highlights the importance of incorporating all three factors and the importance of selecting examples from multiple languages.