 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJUBAKU: An Adversarial Benchmark for Exposing Culturally Grounded Stereotypes in Japanese LLMs
Mar 21, 2026Social biases reflected in language are inherently shaped by cultural norms, which vary significantly across regions and lead to diverse manifestations of stereotypes. Existing evaluations of social bias in large language models (LLMs) for non-English contexts, however, often rely on translations of English benchmarks. Such benchmarks fail to reflect local cultural norms, including those found in Japanese. For instance, Western benchmarks may overlook Japan-specific stereotypes related to hierarchical relationships, regional dialects, or traditional gender roles. To address this limitation, we introduce Japanese cUlture adversarial BiAs benchmarK Under handcrafted creation (JUBAKU), a benchmark tailored to Japanese cultural contexts. JUBAKU uses adversarial construction to expose latent biases across ten distinct cultural categories. Unlike existing benchmarks, JUBAKU features dialogue scenarios hand-crafted by native Japanese annotators, specifically designed to trigger and reveal latent social biases in Japanese LLMs. We evaluated nine Japanese LLMs on JUBAKU and three others adapted from English benchmarks. All models clearly exhibited biases on JUBAKU, performing below the random baseline of 50% with an average accuracy of 23% (ranging from 13% to 33%), despite higher accuracy on the other benchmarks. Human annotators achieved 91% accuracy in identifying unbiased responses, confirming JUBAKU's reliability and its adversarial nature to LLMs.
Rewriting Pre-Training Data Boosts LLM Performance in Math and Code
May 05, 2025The performance of large language models (LLMs) in program synthesis and mathematical reasoning is fundamentally limited by the quality of their pre-training corpora. We introduce two openly licensed datasets, released under the Llama 3.3 Community License, that significantly enhance LLM performance by systematically rewriting public data. SwallowCode (approximately 16.1 billion tokens) refines Python snippets from The-Stack-v2 through a novel four-stage pipeline: syntax validation, pylint-based style filtering, and a two-stage LLM rewriting process that enforces style conformity and transforms snippets into self-contained, algorithmically efficient examples. Unlike prior methods that rely on exclusionary filtering or limited transformations, our transform-and-retain approach upgrades low-quality code, maximizing data utility. SwallowMath (approximately 2.3 billion tokens) enhances Finemath-4+ by removing boilerplate, restoring context, and reformatting solutions into concise, step-by-step explanations. Within a fixed 50 billion token training budget, continual pre-training of Llama-3.1-8B with SwallowCode boosts pass@1 by +17.0 on HumanEval and +17.7 on HumanEval+ compared to Stack-Edu, surpassing the baseline model's code generation capabilities. Similarly, substituting SwallowMath yields +12.4 accuracy on GSM8K and +7.6 on MATH. Ablation studies confirm that each pipeline stage contributes incrementally, with rewriting delivering the largest gains. All datasets, prompts, and checkpoints are publicly available, enabling reproducible research and advancing LLM pre-training for specialized domains.
Building Instruction-Tuning Datasets from Human-Written Instructions with Open-Weight Large Language Models
Mar 31, 2025Instruction tuning is crucial for enabling Large Language Models (LLMs) to solve real-world tasks. Prior work has shown the effectiveness of instruction-tuning data synthesized solely from LLMs, raising a fundamental question: Do we still need human-originated signals for instruction tuning? This work answers the question affirmatively: we build state-of-the-art instruction-tuning datasets sourced from human-written instructions, by simply pairing them with LLM-generated responses. LLMs fine-tuned on our datasets consistently outperform those fine-tuned on existing ones. Our data construction approach can be easily adapted to other languages; we build datasets for Japanese and confirm that LLMs tuned with our data reach state-of-the-art performance. Analyses suggest that instruction-tuning in a new language allows LLMs to follow instructions, while the tuned models exhibit a notable lack of culture-specific knowledge in that language. The datasets and fine-tuned models will be publicly available. Our datasets, synthesized with open-weight LLMs, are openly distributed under permissive licenses, allowing for diverse use cases.
Why We Build Local Large Language Models: An Observational Analysis from 35 Japanese and Multilingual LLMs
Dec 19, 2024



Why do we build local large language models (LLMs)? What should a local LLM learn from the target language? Which abilities can be transferred from other languages? Do language-specific scaling laws exist? To explore these research questions, we evaluated 35 Japanese, English, and multilingual LLMs on 19 evaluation benchmarks for Japanese and English, taking Japanese as a local language. Adopting an observational approach, we analyzed correlations of benchmark scores, and conducted principal component analysis (PCA) on the scores to derive \textit{ability factors} of local LLMs. We found that training on English text can improve the scores of academic subjects in Japanese (JMMLU). In addition, it is unnecessary to specifically train on Japanese text to enhance abilities for solving Japanese code generation, arithmetic reasoning, commonsense, and reading comprehension tasks. In contrast, training on Japanese text could improve question-answering tasks about Japanese knowledge and English-Japanese translation, which indicates that abilities for solving these two tasks can be regarded as \textit{Japanese abilities} for LLMs. Furthermore, we confirmed that the Japanese abilities scale with the computational budget for Japanese text.
HarmonicEval: Multi-modal, Multi-task, Multi-criteria Automatic Evaluation Using a Vision Language Model
Dec 19, 2024



Vision-language models (VLMs) have shown impressive abilities in text and image understanding. However, existing metrics for evaluating the text generated by VLMs focus exclusively on overall quality, leading to two limitations: 1) it is challenging to identify which aspects of the text need improvement from the overall score; 2) metrics may overlook specific evaluation criteria when predicting an overall score. To address these limitations, we propose HarmonicEval, a reference-free evaluation metric that aggregates criterion-wise scores to produce the overall score in a bottom-up manner. Furthermore, we construct the Multi-task Multi-criteria Human Evaluation (MMHE) dataset, which comprises 18,000 expert human judgments across four vision-language tasks. Our experiments demonstrate that HarmonicEval achieves higher correlations with human judgments than conventional metrics while providing numerical scores for each criterion.
HALL-E: Hierarchical Neural Codec Language Model for Minute-Long Zero-Shot Text-to-Speech Synthesis
Oct 06, 2024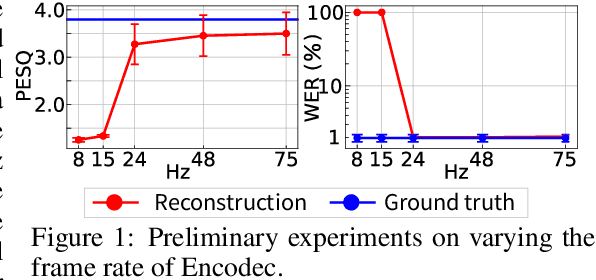

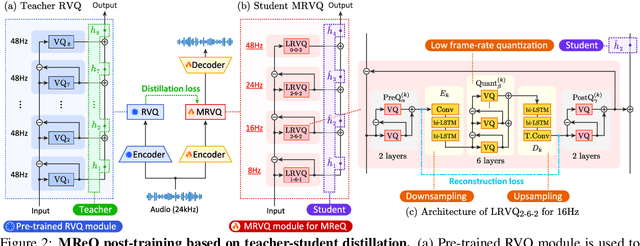
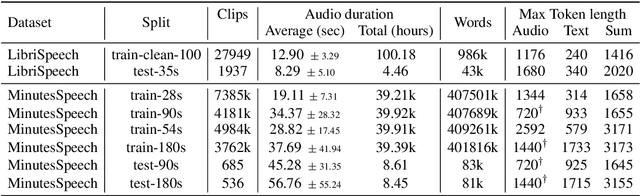
Recently, Text-to-speech (TTS) models based on large language models (LLMs) that translate natural language text into sequences of discrete audio tokens have gained great research attention, with advances in neural audio codec (NAC) models using residual vector quantization (RVQ). However, long-form speech synthesis remains a significant challenge due to the high frame rate, which increases the length of audio tokens and makes it difficult for autoregressive language models to generate audio tokens for even a minute of speech. To address this challenge, this paper introduces two novel post-training approaches: 1) Multi-Resolution Requantization (MReQ) and 2) HALL-E. MReQ is a framework to reduce the frame rate of pre-trained NAC models. Specifically, it incorporates multi-resolution residual vector quantization (MRVQ) module that hierarchically reorganizes discrete audio tokens through teacher-student distillation. HALL-E is an LLM-based TTS model designed to predict hierarchical tokens of MReQ. Specifically, it incorporates the technique of using MRVQ sub-modules and continues training from a pre-trained LLM-based TTS model. Furthermore, to promote TTS research, we create MinutesSpeech, a new benchmark dataset consisting of 40k hours of filtered speech data for training and evaluating speech synthesis ranging from 3s up to 180s. In experiments, we demonstrated the effectiveness of our approaches by applying our post-training framework to VALL-E. We achieved the frame rate down to as low as 8 Hz, enabling the stable minitue-long speech synthesis in a single inference step. Audio samples, dataset, codes and pre-trained models are available at https://yutonishimura-v2.github.io/HALL-E_DEMO/.
ELP-Adapters: Parameter Efficient Adapter Tuning for Various Speech Processing Tasks
Jul 28, 2024Self-supervised learning has emerged as a key approach for learning generic representations from speech data. Despite promising results in downstream tasks such as speech recognition, speaker verification, and emotion recognition, a significant number of parameters is required, which makes fine-tuning for each task memory-inefficient. To address this limitation, we introduce ELP-adapter tuning, a novel method for parameter-efficient fine-tuning using three types of adapter, namely encoder adapters (E-adapters), layer adapters (L-adapters), and a prompt adapter (P-adapter). The E-adapters are integrated into transformer-based encoder layers and help to learn fine-grained speech representations that are effective for speech recognition. The L-adapters create paths from each encoder layer to the downstream head and help to extract non-linguistic features from lower encoder layers that are effective for speaker verification and emotion recognition. The P-adapter appends pseudo features to CNN features to further improve effectiveness and efficiency. With these adapters, models can be quickly adapted to various speech processing tasks. Our evaluation across four downstream tasks using five backbone models demonstrated the effectiveness of the proposed method. With the WavLM backbone, its performance was comparable to or better than that of full fine-tuning on all tasks while requiring 90% fewer learnable parameters.
Building a Large Japanese Web Corpus for Large Language Models
Apr 27, 2024


Open Japanese large language models (LLMs) have been trained on the Japanese portions of corpora such as CC-100, mC4, and OSCAR. However, these corpora were not created for the quality of Japanese texts. This study builds a large Japanese web corpus by extracting and refining text from the Common Crawl archive (21 snapshots of approximately 63.4 billion pages crawled between 2020 and 2023). This corpus consists of approximately 312.1 billion characters (approximately 173 million pages), which is the largest of all available training corpora for Japanese LLMs, surpassing CC-100 (approximately 25.8 billion characters), mC4 (approximately 239.7 billion characters) and OSCAR 23.10 (approximately 74 billion characters). To confirm the quality of the corpus, we performed continual pre-training on Llama 2 7B, 13B, 70B, Mistral 7B v0.1, and Mixtral 8x7B Instruct as base LLMs and gained consistent (6.6-8.1 points) improvements on Japanese benchmark datasets. We also demonstrate that the improvement on Llama 2 13B brought from the presented corpus was the largest among those from other existing corpora.
Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities
Apr 27, 2024



Cross-lingual continual pre-training of large language models (LLMs) initially trained on English corpus allows us to leverage the vast amount of English language resources and reduce the pre-training cost. In this study, we constructed Swallow, an LLM with enhanced Japanese capability, by extending the vocabulary of Llama 2 to include Japanese characters and conducting continual pre-training on a large Japanese web corpus. Experimental results confirmed that the performance on Japanese tasks drastically improved through continual pre-training, and the performance monotonically increased with the amount of training data up to 100B tokens. Consequently, Swallow achieved superior performance compared to other LLMs that were trained from scratch in English and Japanese. An analysis of the effects of continual pre-training revealed that it was particularly effective for Japanese question answering tasks. Furthermore, to elucidate effective methodologies for cross-lingual continual pre-training from English to Japanese, we investigated the impact of vocabulary expansion and the effectiveness of incorporating parallel corpora. The results showed that the efficiency gained through vocabulary expansion had no negative impact on performance, except for the summarization task, and that the combined use of parallel corpora enhanced translation ability.
Likelihood-based Mitigation of Evaluation Bias in Large Language Models
Mar 01, 2024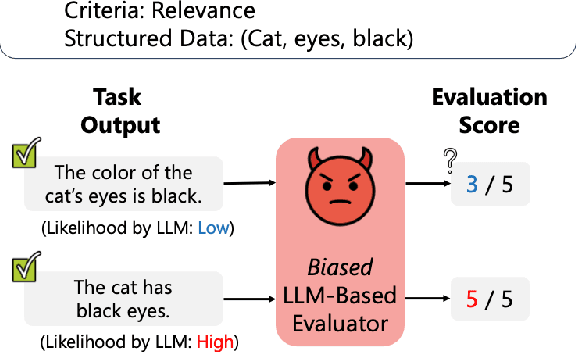
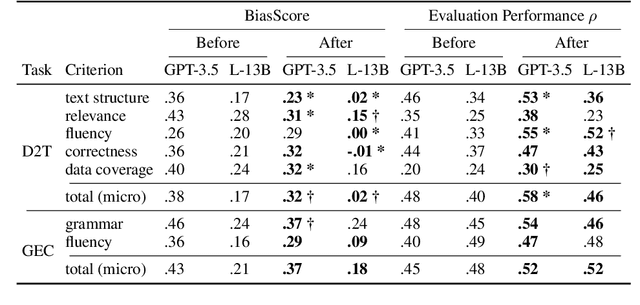
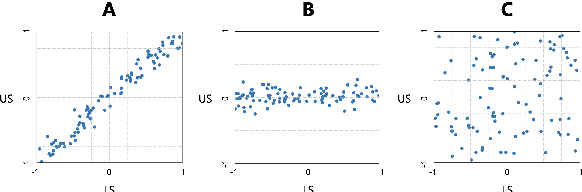
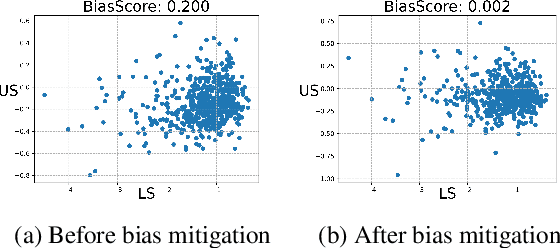
Large Language Models (LLMs) are widely used to evaluate natural language generation tasks as automated metrics. However, the likelihood, a measure of LLM's plausibility for a sentence, can vary due to superficial differences in sentences, such as word order and sentence structure. It is therefore possible that there might be a likelihood bias if LLMs are used for evaluation: they might overrate sentences with higher likelihoods while underrating those with lower likelihoods. In this paper, we investigate the presence and impact of likelihood bias in LLM-based evaluators. We also propose a method to mitigate the likelihood bias. Our method utilizes highly biased instances as few-shot examples for in-context learning. Our experiments in evaluating the data-to-text and grammatical error correction tasks reveal that several LLMs we test display a likelihood bias. Furthermore, our proposed method successfully mitigates this bias, also improving evaluation performance (in terms of correlation of models with human scores) significantly.