 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISCODE: Distribution-Aware Score Decoder for Robust Automatic Evaluation of Image Captioning
Dec 16, 2025Large vision-language models (LVLMs) have shown impressive performance across a broad range of multimodal tasks. However, robust image caption evaluation using LVLMs remains challenging, particularly under domain-shift scenarios. To address this issue, we introduce the Distribution-Aware Score Decoder (DISCODE), a novel finetuning-free method that generates robust evaluation scores better aligned with human judgments across diverse domains. The core idea behind DISCODE lies in its test-time adaptive evaluation approach, which introduces the Adaptive Test-Time (ATT) loss, leveraging a Gaussian prior distribution to improve robustness in evaluation score estimation. This loss is efficiently minimized at test time using an analytical solution that we derive. Furthermore, we introduce the Multi-domain Caption Evaluation (MCEval) benchmark, a new image captioning evaluation benchmark covering six distinct domains, designed to assess the robustness of evaluation metrics. In our experiments, we demonstrate that DISCODE achieves state-of-the-art performance as a reference-free evaluation metric across MCEval and four representative existing benchmarks.
Multi-Point Positional Insertion Tuning for Small Object Detection
Dec 24, 2024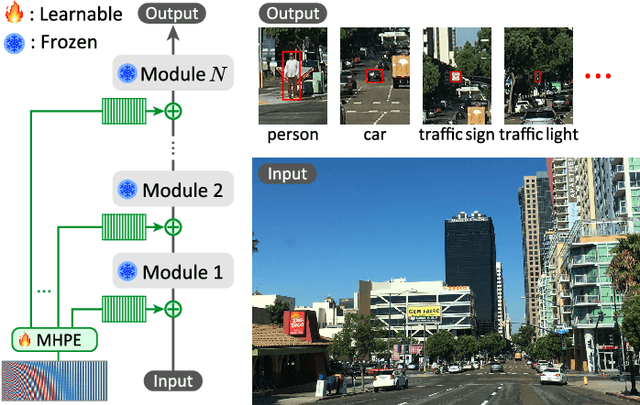
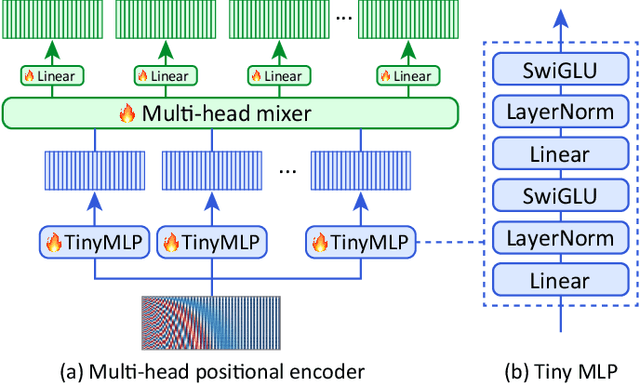
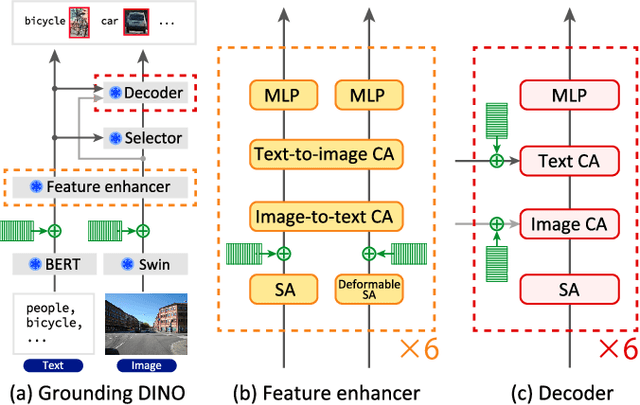

Small object detection aims to localize and classify small objects within images. With recent advances in large-scale vision-language pretraining, finetuning pretrained object detection models has emerged as a promising approach. However, finetuning large models is computationally and memory expensive. To address this issue, this paper introduces multi-point positional insertion (MPI) tuning, a parameter-efficient finetuning (PEFT) method for small object detection. Specifically, MPI incorporates multiple positional embeddings into a frozen pretrained model, enabling the efficient detection of small objects by providing precise positional information to latent features. Through experiments, we demonstrated the effectiveness of the proposed method on the SODA-D dataset. MPI performed comparably to conventional PEFT methods, including CoOp and VPT, while significantly reducing the number of parameters that need to be tuned.
HALL-E: Hierarchical Neural Codec Language Model for Minute-Long Zero-Shot Text-to-Speech Synthesis
Oct 06, 2024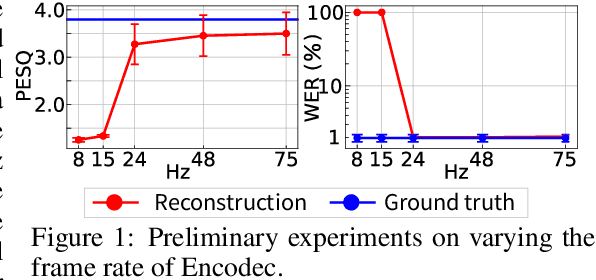

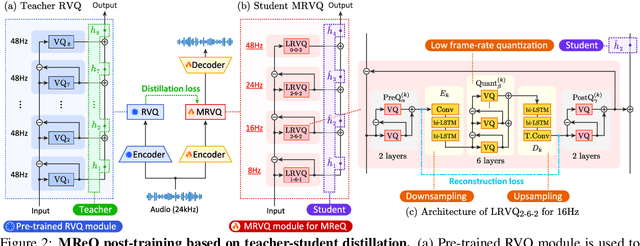
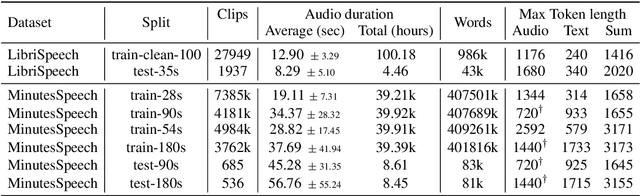
Recently, Text-to-speech (TTS) models based on large language models (LLMs) that translate natural language text into sequences of discrete audio tokens have gained great research attention, with advances in neural audio codec (NAC) models using residual vector quantization (RVQ). However, long-form speech synthesis remains a significant challenge due to the high frame rate, which increases the length of audio tokens and makes it difficult for autoregressive language models to generate audio tokens for even a minute of speech. To address this challenge, this paper introduces two novel post-training approaches: 1) Multi-Resolution Requantization (MReQ) and 2) HALL-E. MReQ is a framework to reduce the frame rate of pre-trained NAC models. Specifically, it incorporates multi-resolution residual vector quantization (MRVQ) module that hierarchically reorganizes discrete audio tokens through teacher-student distillation. HALL-E is an LLM-based TTS model designed to predict hierarchical tokens of MReQ. Specifically, it incorporates the technique of using MRVQ sub-modules and continues training from a pre-trained LLM-based TTS model. Furthermore, to promote TTS research, we create MinutesSpeech, a new benchmark dataset consisting of 40k hours of filtered speech data for training and evaluating speech synthesis ranging from 3s up to 180s. In experiments, we demonstrated the effectiveness of our approaches by applying our post-training framework to VALL-E. We achieved the frame rate down to as low as 8 Hz, enabling the stable minitue-long speech synthesis in a single inference step. Audio samples, dataset, codes and pre-trained models are available at https://yutonishimura-v2.github.io/HALL-E_DEMO/.
ELP-Adapters: Parameter Efficient Adapter Tuning for Various Speech Processing Tasks
Jul 28, 2024Self-supervised learning has emerged as a key approach for learning generic representations from speech data. Despite promising results in downstream tasks such as speech recognition, speaker verification, and emotion recognition, a significant number of parameters is required, which makes fine-tuning for each task memory-inefficient. To address this limitation, we introduce ELP-adapter tuning, a novel method for parameter-efficient fine-tuning using three types of adapter, namely encoder adapters (E-adapters), layer adapters (L-adapters), and a prompt adapter (P-adapter). The E-adapters are integrated into transformer-based encoder layers and help to learn fine-grained speech representations that are effective for speech recognition. The L-adapters create paths from each encoder layer to the downstream head and help to extract non-linguistic features from lower encoder layers that are effective for speaker verification and emotion recognition. The P-adapter appends pseudo features to CNN features to further improve effectiveness and efficiency. With these adapters, models can be quickly adapted to various speech processing tasks. Our evaluation across four downstream tasks using five backbone models demonstrated the effectiveness of the proposed method. With the WavLM backbone, its performance was comparable to or better than that of full fine-tuning on all tasks while requiring 90% fewer learnable parameters.