 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat-Where Transformer: A Slot-Centric Visual Backbone for Concurrent Representation and Localization
May 12, 2026Many image understanding tasks involve identifying what is present and where it appears. However, tasks that address where, such as object discovery, detection, and segmentation, are often considerably more complex than image classification, which primarily focuses on what. One possible reason is that classification-oriented backbones tend to emphasize semantic information about what, while implicitly entangling or suppressing information about where. In this work, we focus on an inductive bias termed what-where separation, which encourages models to represent object appearance and spatial location in a decomposed manner. To incorporate this bias throughout an attentive backbone in the style of Vision Transformer (ViT), we propose the What-Where Transformer (WWT). Our method introduces two key novel designs: (1) it treats tokens as representations of what and attention maps as representations of where, and processes them in concurrent feed-forward modules via a multi-stream, slot-based architecture; (2) it reuses both the final-layer tokens and attention maps for downstream tasks, and directly exposes them to gradients derived from task losses, thereby facilitating more effective and explicit learning of localization. We demonstrate that even under standard single-label classification-based supervision on ImageNet, WWT exhibits emergent multiple object discovery directly from raw attention maps, rather than via additional postprocessing such as token clustering. Furthermore, WWT achieves superior performance compared to ViT-based methods on zero-shot object discovery and weakly supervised semantic segmentation, and it is transferable to various localization setups with minimal modifications. Code will be published after acceptance.
Teacher-Guided Routing for Sparse Vision Mixture-of-Experts
Apr 23, 2026Recent progress in deep learning has been driven by increasingly large-scale models, but the resulting computational cost has become a critical bottleneck. Sparse Mixture of Experts (MoE) offers an effective solution by activating only a small subset of experts for each input, achieving high scalability without sacrificing inference speed. Although effective, sparse MoE training exhibits characteristic optimization difficulties. Because the router receives informative gradients only through the experts selected in the forward pass, it suffers from gradient blocking and obtains little information from unselected routes. This limited, highly localized feedback makes it difficult for the router to learn appropriate expert-selection scores and often leads to unstable routing dynamics, such as fluctuating expert assignments during training. To address this issue, we propose TGR-MoE: Teacher-Guided Routing for Sparse Vision Mixture-of-Experts, a simple yet effective method that stabilizes router learning using supervision derived from a pretrained dense teacher model. TGR-MoE constructs a teacher router from the teacher's intermediate representations and uses its routing outputs as pseudo-supervision for the student router, suppressing frequent routing fluctuations during training and enabling knowledge-guided expert selection from the early stages of training. Extensive experiments on ImageNet-1K and CIFAR-100 demonstrate that TGR consistently improves both accuracy and routing consistency, while maintaining stable training even under highly sparse configurations.
Touch2Insert: Zero-Shot Peg Insertion by Touching Intersections of Peg and Hole
Mar 04, 2026Reliable insertion of industrial connectors remains a central challenge in robotics, requiring sub-millimeter precision under uncertainty and often without full visual access. Vision-based approaches struggle with occlusion and limited generalization, while learning-based policies frequently fail to transfer to unseen geometries. To address these limitations, we leverage tactile sensing, which captures local surface geometry at the point of contact and thus provides reliable information even under occlusion and across novel connector shapes. Building on this capability, we present \emph{Touch2Insert}, a tactile-based framework for arbitrary peg insertion. Our method reconstructs cross-sectional geometry from high-resolution tactile images and estimates the relative pose of the hole with respect to the peg in a zero-shot manner. By aligning reconstructed shapes through registration, the framework enables insertion from a single contact without task-specific training. To evaluate its performance, we conducted experiments with three diverse connectors in both simulation and real-robot settings. The results indicate that Touch2Insert achieved sub-millimeter pose estimation accuracy for all connectors in simulation, and attained an average success rate of 86.7\% on the real robot, thereby confirming the robustness and generalizability of tactile sensing for real-world robotic connector insertion.
Geometry Meets Light: Leveraging Geometric Priors for Universal Photometric Stereo under Limited Multi-Illumination Cues
Nov 18, 2025
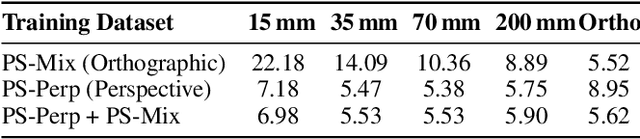
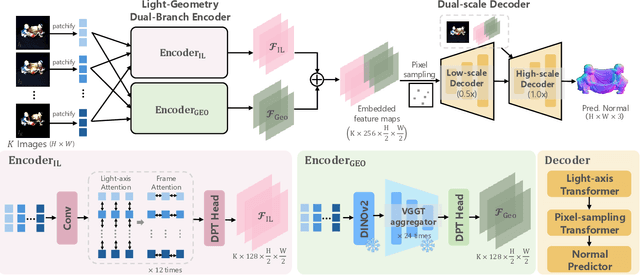
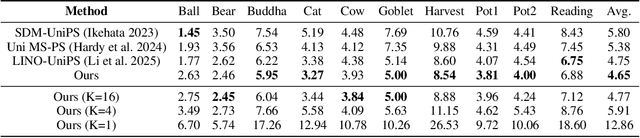
Universal Photometric Stereo is a promising approach for recovering surface normals without strict lighting assumptions. However, it struggles when multi-illumination cues are unreliable, such as under biased lighting or in shadows or self-occluded regions of complex in-the-wild scenes. We propose GeoUniPS, a universal photometric stereo network that integrates synthetic supervision with high-level geometric priors from large-scale 3D reconstruction models pretrained on massive in-the-wild data. Our key insight is that these 3D reconstruction models serve as visual-geometry foundation models, inherently encoding rich geometric knowledge of real scenes. To leverage this, we design a Light-Geometry Dual-Branch Encoder that extracts both multi-illumination cues and geometric priors from the frozen 3D reconstruction model. We also address the limitations of the conventional orthographic projection assumption by introducing the PS-Perp dataset with realistic perspective projection to enable learning of spatially varying view directions. Extensive experiments demonstrate that GeoUniPS delivers state-of-the-arts performance across multiple datasets, both quantitatively and qualitatively, especially in the complex in-the-wild scenes.
Anomaly Object Segmentation with Vision-Language Models for Steel Scrap Recycling
Jun 16, 2025Recycling steel scrap can reduce carbon dioxide (CO2) emissions from the steel industry. However, a significant challenge in steel scrap recycling is the inclusion of impurities other than steel. To address this issue, we propose vision-language-model-based anomaly detection where a model is finetuned in a supervised manner, enabling it to handle niche objects effectively. This model enables automated detection of anomalies at a fine-grained level within steel scrap. Specifically, we finetune the image encoder, equipped with multi-scale mechanism and text prompts aligned with both normal and anomaly images. The finetuning process trains these modules using a multiclass classification as the supervision.
Zero-Shot Peg Insertion: Identifying Mating Holes and Estimating SE(2) Poses with Vision-Language Models
Mar 08, 2025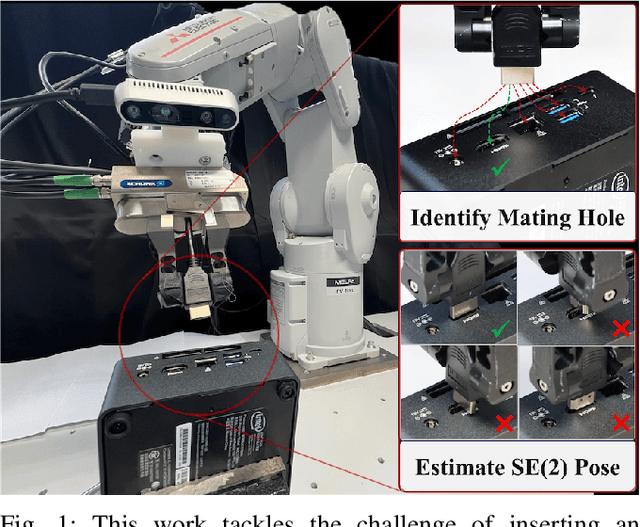
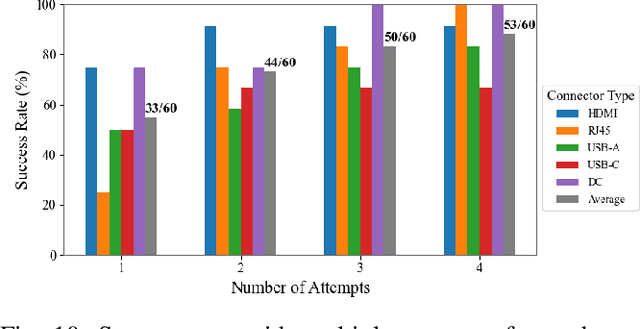
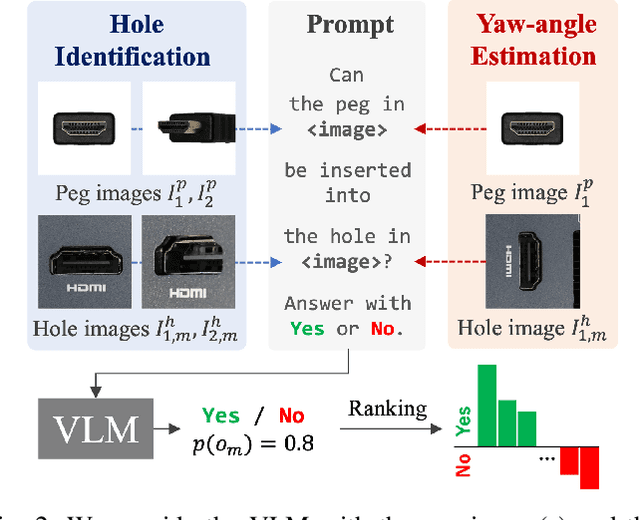
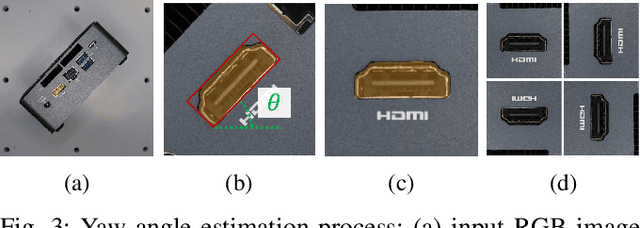
Achieving zero-shot peg insertion, where inserting an arbitrary peg into an unseen hole without task-specific training, remains a fundamental challenge in robotics. This task demands a highly generalizable perception system capable of detecting potential holes, selecting the correct mating hole from multiple candidates, estimating its precise pose, and executing insertion despite uncertainties. While learning-based methods have been applied to peg insertion, they often fail to generalize beyond the specific peg-hole pairs encountered during training. Recent advancements in Vision-Language Models (VLMs) offer a promising alternative, leveraging large-scale datasets to enable robust generalization across diverse tasks. Inspired by their success, we introduce a novel zero-shot peg insertion framework that utilizes a VLM to identify mating holes and estimate their poses without prior knowledge of their geometry. Extensive experiments demonstrate that our method achieves 90.2% accuracy, significantly outperforming baselines in identifying the correct mating hole across a wide range of previously unseen peg-hole pairs, including 3D-printed objects, toy puzzles, and industrial connectors. Furthermore, we validate the effectiveness of our approach in a real-world connector insertion task on a backpanel of a PC, where our system successfully detects holes, identifies the correct mating hole, estimates its pose, and completes the insertion with a success rate of 88.3%. These results highlight the potential of VLM-driven zero-shot reasoning for enabling robust and generalizable robotic assembly.
Rectified Lagrangian for Out-of-Distribution Detection in Modern Hopfield Networks
Feb 19, 2025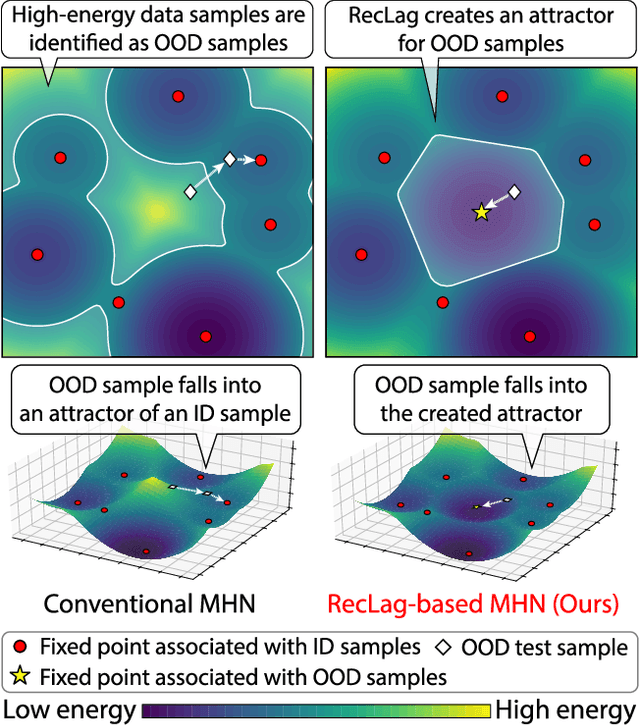
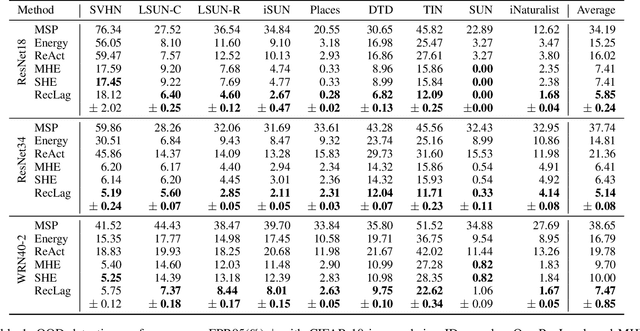
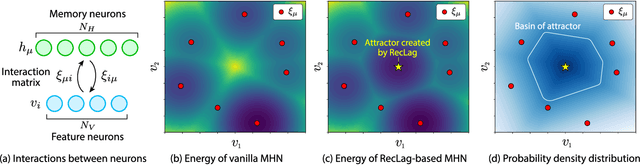
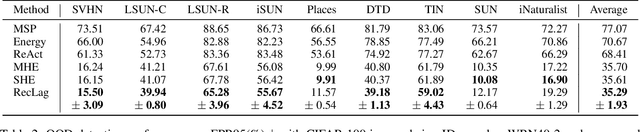
Modern Hopfield networks (MHNs) have recently gained significant attention in the field of artificial intelligence because they can store and retrieve a large set of patterns with an exponentially large memory capacity. A MHN is generally a dynamical system defined with Lagrangians of memory and feature neurons, where memories associated with in-distribution (ID) samples are represented by attractors in the feature space. One major problem in existing MHNs lies in managing out-of-distribution (OOD) samples because it was originally assumed that all samples are ID samples. To address this, we propose the rectified Lagrangian (RegLag), a new Lagrangian for memory neurons that explicitly incorporates an attractor for OOD samples in the dynamical system of MHNs. RecLag creates a trivial point attractor for any interaction matrix, enabling OOD detection by identifying samples that fall into this attractor as OOD. The interaction matrix is optimized so that the probability densities can be estimated to identify ID/OOD. We demonstrate the effectiveness of RecLag-based MHNs compared to energy-based OOD detection methods, including those using state-of-the-art Hopfield energies, across nine image datasets.
Multi-Point Positional Insertion Tuning for Small Object Detection
Dec 24, 2024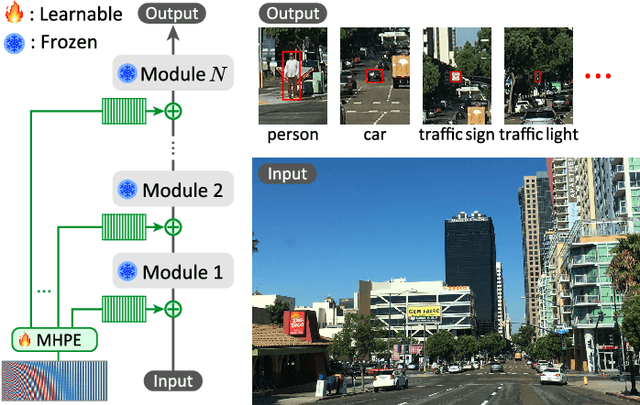
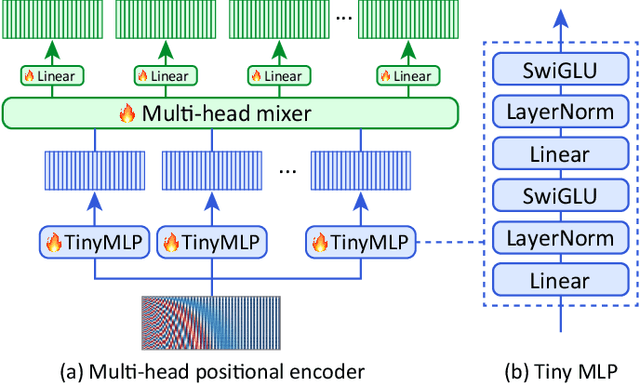

Small object detection aims to localize and classify small objects within images. With recent advances in large-scale vision-language pretraining, finetuning pretrained object detection models has emerged as a promising approach. However, finetuning large models is computationally and memory expensive. To address this issue, this paper introduces multi-point positional insertion (MPI) tuning, a parameter-efficient finetuning (PEFT) method for small object detection. Specifically, MPI incorporates multiple positional embeddings into a frozen pretrained model, enabling the efficient detection of small objects by providing precise positional information to latent features. Through experiments, we demonstrated the effectiveness of the proposed method on the SODA-D dataset. MPI performed comparably to conventional PEFT methods, including CoOp and VPT, while significantly reducing the number of parameters that need to be tuned.
GUMBEL-NERF: Representing Unseen Objects as Part-Compositional Neural Radiance Fields
Oct 27, 2024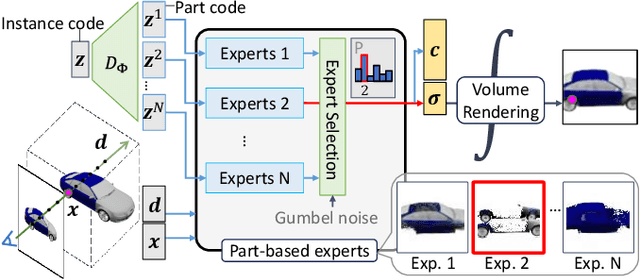
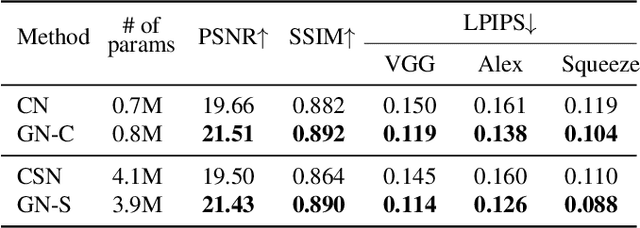
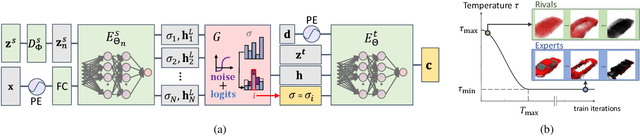
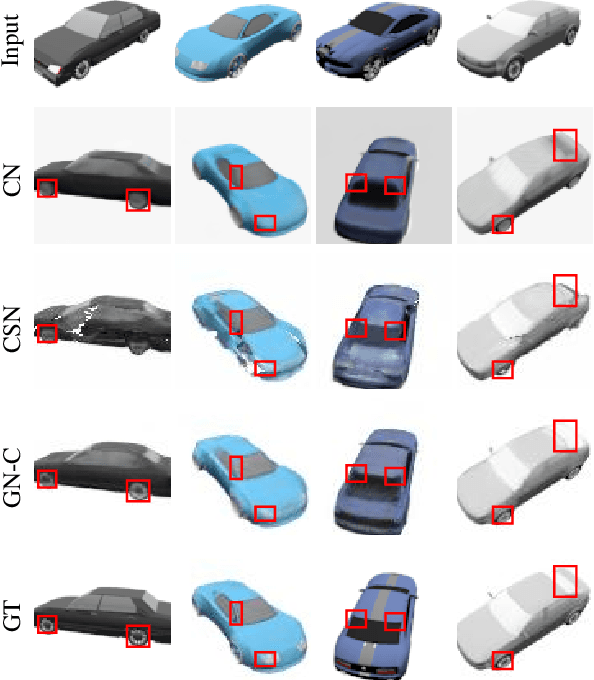
We propose Gumbel-NeRF, a mixture-of-expert (MoE) neural radiance fields (NeRF) model with a hindsight expert selection mechanism for synthesizing novel views of unseen objects. Previous studies have shown that the MoE structure provides high-quality representations of a given large-scale scene consisting of many objects. However, we observe that such a MoE NeRF model often produces low-quality representations in the vicinity of experts' boundaries when applied to the task of novel view synthesis of an unseen object from one/few-shot input. We find that this deterioration is primarily caused by the foresight expert selection mechanism, which may leave an unnatural discontinuity in the object shape near the experts' boundaries. Gumbel-NeRF adopts a hindsight expert selection mechanism, which guarantees continuity in the density field even near the experts' boundaries. Experiments using the SRN cars dataset demonstrate the superiority of Gumbel-NeRF over the baselines in terms of various image quality metrics.
ELP-Adapters: Parameter Efficient Adapter Tuning for Various Speech Processing Tasks
Jul 28, 2024Self-supervised learning has emerged as a key approach for learning generic representations from speech data. Despite promising results in downstream tasks such as speech recognition, speaker verification, and emotion recognition, a significant number of parameters is required, which makes fine-tuning for each task memory-inefficient. To address this limitation, we introduce ELP-adapter tuning, a novel method for parameter-efficient fine-tuning using three types of adapter, namely encoder adapters (E-adapters), layer adapters (L-adapters), and a prompt adapter (P-adapter). The E-adapters are integrated into transformer-based encoder layers and help to learn fine-grained speech representations that are effective for speech recognition. The L-adapters create paths from each encoder layer to the downstream head and help to extract non-linguistic features from lower encoder layers that are effective for speaker verification and emotion recognition. The P-adapter appends pseudo features to CNN features to further improve effectiveness and efficiency. With these adapters, models can be quickly adapted to various speech processing tasks. Our evaluation across four downstream tasks using five backbone models demonstrated the effectiveness of the proposed method. With the WavLM backbone, its performance was comparable to or better than that of full fine-tuning on all tasks while requiring 90% fewer learnable parameters.