 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTakeuchi's Information Criteria as Generalization Measures for DNNs Close to NTK Regime
Feb 26, 2026Generalization measures have been studied extensively in the machine learning community to better characterize generalization gaps. However, establishing a reliable generalization measure for statistically singular models such as deep neural networks (DNNs) is difficult due to their complex nature. This study focuses on Takeuchi's information criterion (TIC) to investigate the conditions under which this classical measure can effectively explain the generalization gaps of DNNs. Importantly, the developed theory indicates the applicability of TIC near the neural tangent kernel (NTK) regime. In a series of experiments, we trained more than 5,000 DNN models with 12 architectures, including large models (e.g., VGG-16), on four datasets, and estimated the corresponding TIC values to examine the relationship between the generalization gap and the TIC estimates. We applied several TIC approximation methods with feasible computational costs and assessed the accuracy trade-off. Our experimental results indicate that the estimated TIC values correlate well with the generalization gap under conditions close to the NTK regime. However, we show both theoretically and empirically that outside the NTK regime such correlation disappears. Finally, we demonstrate that TIC provides better trial pruning ability than existing methods for hyperparameter optimization.
Empirical Study on Optimizer Selection for Out-of-Distribution Generalization
Nov 18, 2022



Modern deep learning systems are fragile and do not generalize well under distribution shifts. While much promising work has been accomplished to address these concerns, a systematic study of the role of optimizers and their out-of-distribution generalization performance has not been undertaken. In this study, we examine the performance of popular first-order optimizers for different classes of distributional shift under empirical risk minimization and invariant risk minimization. We address the problem settings for image and text classification using DomainBed, WILDS, and Backgrounds Challenge as out-of-distribution datasets for the exhaustive study. We search over a wide range of hyperparameters and examine the classification accuracy (in-distribution and out-of-distribution) for over 20,000 models. We arrive at the following findings: i) contrary to conventional wisdom, adaptive optimizers (e.g., Adam) perform worse than non-adaptive optimizers (e.g., SGD, momentum-based SGD), ii) in-distribution performance and out-of-distribution performance exhibit three types of behavior depending on the dataset - linear returns, increasing returns, and diminishing returns. We believe these findings can help practitioners choose the right optimizer and know what behavior to expect.
Informative Sample-Aware Proxy for Deep Metric Learning
Nov 18, 2022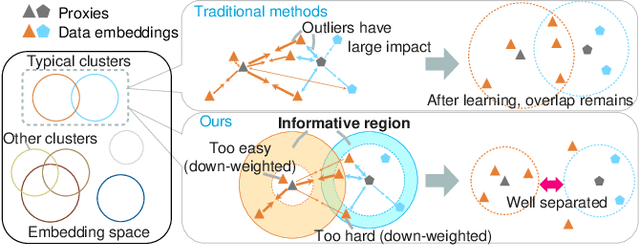
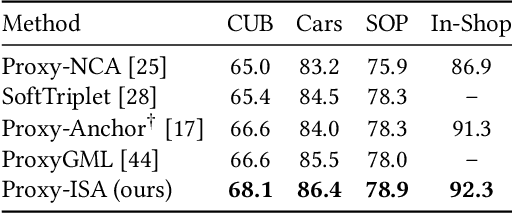

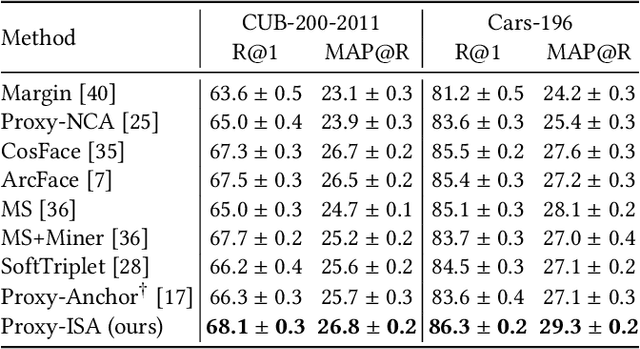
Among various supervised deep metric learning methods proxy-based approaches have achieved high retrieval accuracies. Proxies, which are class-representative points in an embedding space, receive updates based on proxy-sample similarities in a similar manner to sample representations. In existing methods, a relatively small number of samples can produce large gradient magnitudes (ie, hard samples), and a relatively large number of samples can produce small gradient magnitudes (ie, easy samples); these can play a major part in updates. Assuming that acquiring too much sensitivity to such extreme sets of samples would deteriorate the generalizability of a method, we propose a novel proxy-based method called Informative Sample-Aware Proxy (Proxy-ISA), which directly modifies a gradient weighting factor for each sample using a scheduled threshold function, so that the model is more sensitive to the informative samples. Extensive experiments on the CUB-200-2011, Cars-196, Stanford Online Products and In-shop Clothes Retrieval datasets demonstrate the superiority of Proxy-ISA compared with the state-of-the-art methods.
Feature Space Particle Inference for Neural Network Ensembles
Jun 02, 2022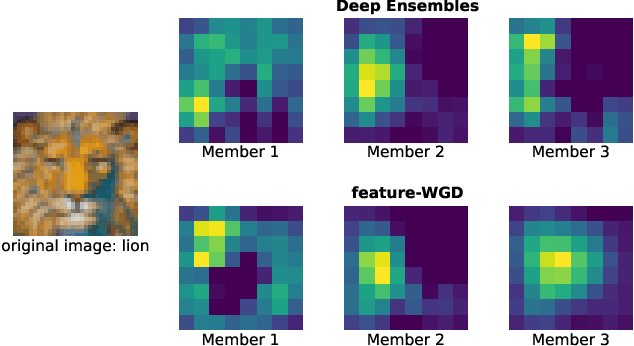


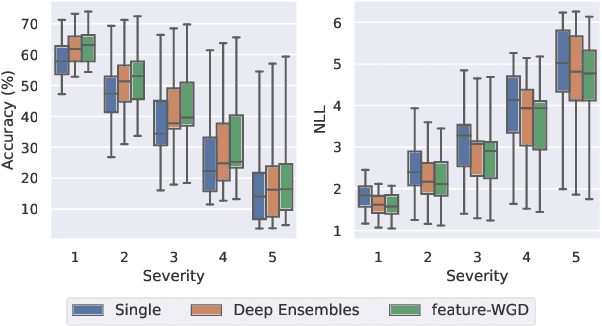
Ensembles of deep neural networks demonstrate improved performance over single models. For enhancing the diversity of ensemble members while keeping their performance, particle-based inference methods offer a promising approach from a Bayesian perspective. However, the best way to apply these methods to neural networks is still unclear: seeking samples from the weight-space posterior suffers from inefficiency due to the over-parameterization issues, while seeking samples directly from the function-space posterior often results in serious underfitting. In this study, we propose optimizing particles in the feature space where the activation of a specific intermediate layer lies to address the above-mentioned difficulties. Our method encourages each member to capture distinct features, which is expected to improve ensemble prediction robustness. Extensive evaluation on real-world datasets shows that our model significantly outperforms the gold-standard Deep Ensembles on various metrics, including accuracy, calibration, and robustness. Code is available at https://github.com/DensoITLab/featurePI .
Breaking Inter-Layer Co-Adaptation by Classifier Anonymization
Jun 04, 2019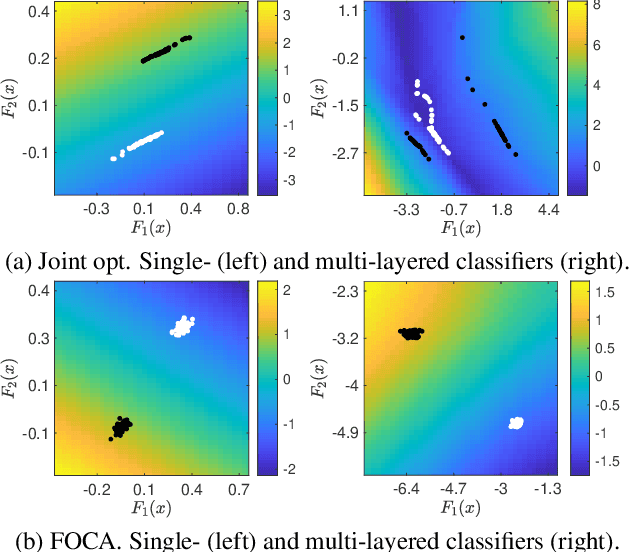
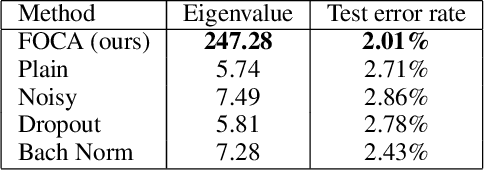
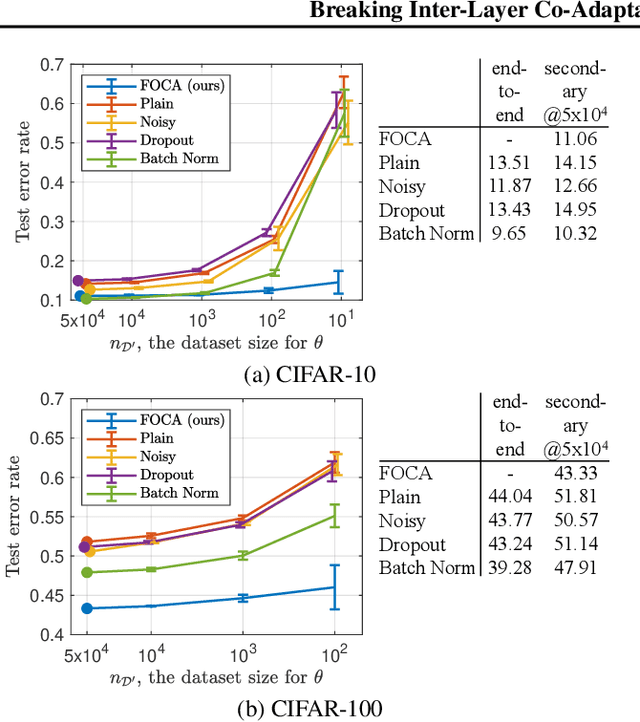
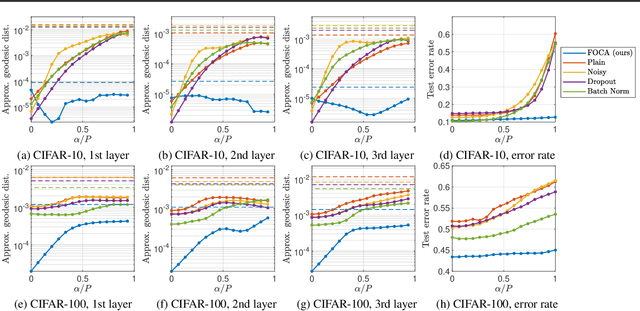
This study addresses an issue of co-adaptation between a feature extractor and a classifier in a neural network. A naive joint optimization of a feature extractor and a classifier often brings situations in which an excessively complex feature distribution adapted to a very specific classifier degrades the test performance. We introduce a method called Feature-extractor Optimization through Classifier Anonymization (FOCA), which is designed to avoid an explicit co-adaptation between a feature extractor and a particular classifier by using many randomly-generated, weak classifiers during optimization. We put forth a mathematical proposition that states the FOCA features form a point-like distribution within the same class in a class-separable fashion under special conditions. Real-data experiments under more general conditions provide supportive evidences.
Pairwise Rotation Hashing for High-dimensional Features
Jan 29, 2015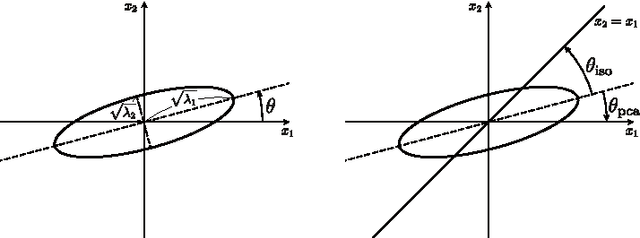
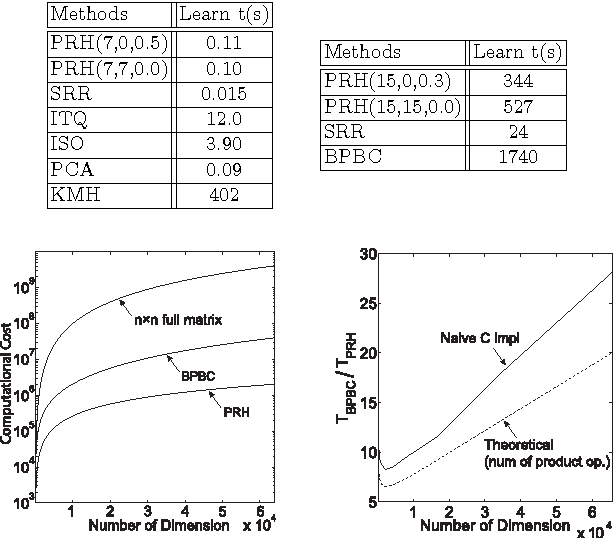
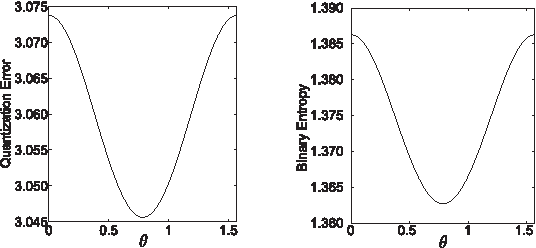
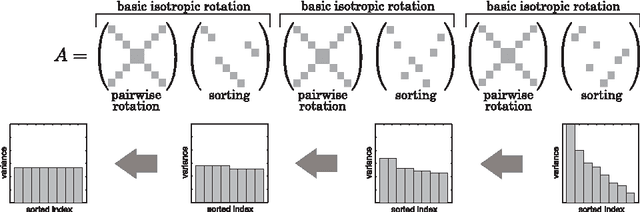
Binary Hashing is widely used for effective approximate nearest neighbors search. Even though various binary hashing methods have been proposed, very few methods are feasible for extremely high-dimensional features often used in visual tasks today. We propose a novel highly sparse linear hashing method based on pairwise rotations. The encoding cost of the proposed algorithm is $\mathrm{O}(n \log n)$ for n-dimensional features, whereas that of the existing state-of-the-art method is typically $\mathrm{O}(n^2)$. The proposed method is also remarkably faster in the learning phase. Along with the efficiency, the retrieval accuracy is comparable to or slightly outperforming the state-of-the-art. Pairwise rotations used in our method are formulated from an analytical study of the trade-off relationship between quantization error and entropy of binary codes. Although these hashing criteria are widely used in previous researches, its analytical behavior is rarely studied. All building blocks of our algorithm are based on the analytical solution, and it thus provides a fairly simple and efficient procedure.