 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDGE-Shield: Efficient Denoising-staGE Shield for Violative Content Filtering via Scalable Reference-Based Matching
Apr 04, 2026The advent of Text-to-Image generative models poses significant risks of copyright violation and deepfake generation. Since the rapid proliferation of new copyrighted works and private individuals constantly emerges, reference-based training-free content filters are essential for providing up-to-date protection without the constraints of a fixed knowledge cutoff. However, existing reference-based approaches often lack scalability when handling numerous references and require waiting for finishing image generation. To solve these problems, we propose EDGE-Shield, a scalable content filter during the denoising process that maintains practical latency while effectively blocking violative content. We leverage embedding-based matching for efficient reference comparison. Additionally, we introduce an \textit{$x$}-pred transformation that converts the model's noisy intermediate latent into the pseudo-estimated clean latent at the later stage, enhancing classification accuracy of violative content at earlier denoising stages. We conduct experiments of violative content filtering against two generative models including Z-Image-Turbo and Qwen-Image. EDGE-Shield significantly outperforms traditional reference-based methods in terms of latency; it achieves an approximate $79\%$ reduction in processing time for Z-Image-Turbo and approximate $50\%$ reduction for Qwen-Image, maintaining the filtering accuracy across different model architectures.
Natural Fingerprints of Large Language Models
Apr 21, 2025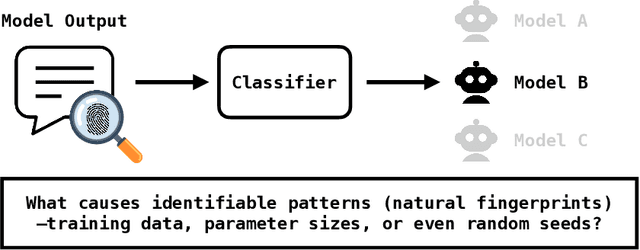
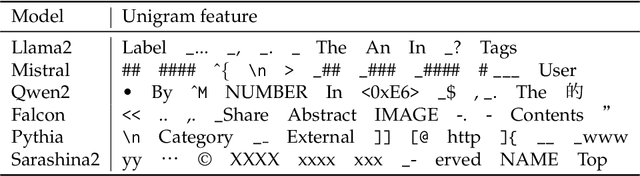
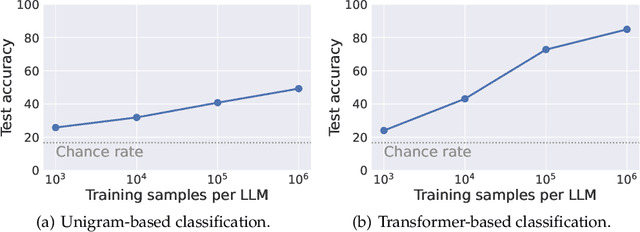

Large language models (LLMs) often exhibit biases -- systematic deviations from expected norms -- in their outputs. These range from overt issues, such as unfair responses, to subtler patterns that can reveal which model produced them. We investigate the factors that give rise to identifiable characteristics in LLMs. Since LLMs model training data distribution, it is reasonable that differences in training data naturally lead to the characteristics. However, our findings reveal that even when LLMs are trained on the exact same data, it is still possible to distinguish the source model based on its generated text. We refer to these unintended, distinctive characteristics as natural fingerprints. By systematically controlling training conditions, we show that the natural fingerprints can emerge from subtle differences in the training process, such as parameter sizes, optimization settings, and even random seeds. We believe that understanding natural fingerprints offers new insights into the origins of unintended bias and ways for improving control over LLM behavior.
Resampling Benchmark for Efficient Comprehensive Evaluation of Large Vision-Language Models
Apr 14, 2025We propose an efficient evaluation protocol for large vision-language models (VLMs). Given their broad knowledge and reasoning capabilities, multiple benchmarks are needed for comprehensive assessment, making evaluation computationally expensive. To improve efficiency, we construct a subset that yields results comparable to full benchmark evaluations. Our benchmark classification experiments reveal that no single benchmark fully covers all challenges. We then introduce a subset construction method using farthest point sampling (FPS). Our experiments show that FPS-based benchmarks maintain a strong correlation (> 0.96) with full evaluations while using only ~1\% of the data. Additionally, applying FPS to an existing benchmark improves correlation with overall evaluation results, suggesting its potential to reduce unintended dataset biases.
Fed3DGS: Scalable 3D Gaussian Splatting with Federated Learning
Mar 18, 2024In this work, we present Fed3DGS, a scalable 3D reconstruction framework based on 3D Gaussian splatting (3DGS) with federated learning. Existing city-scale reconstruction methods typically adopt a centralized approach, which gathers all data in a central server and reconstructs scenes. The approach hampers scalability because it places a heavy load on the server and demands extensive data storage when reconstructing scenes on a scale beyond city-scale. In pursuit of a more scalable 3D reconstruction, we propose a federated learning framework with 3DGS, which is a decentralized framework and can potentially use distributed computational resources across millions of clients. We tailor a distillation-based model update scheme for 3DGS and introduce appearance modeling for handling non-IID data in the scenario of 3D reconstruction with federated learning. We simulate our method on several large-scale benchmarks, and our method demonstrates rendered image quality comparable to centralized approaches. In addition, we also simulate our method with data collected in different seasons, demonstrating that our framework can reflect changes in the scenes and our appearance modeling captures changes due to seasonal variations.
Federated Learning for Large-Scale Scene Modeling with Neural Radiance Fields
Sep 12, 2023We envision a system to continuously build and maintain a map based on earth-scale neural radiance fields (NeRF) using data collected from vehicles and drones in a lifelong learning manner. However, existing large-scale modeling by NeRF has problems in terms of scalability and maintainability when modeling earth-scale environments. Therefore, to address these problems, we propose a federated learning pipeline for large-scale modeling with NeRF. We tailor the model aggregation pipeline in federated learning for NeRF, thereby allowing local updates of NeRF. In the aggregation step, the accuracy of the clients' global pose is critical. Thus, we also propose global pose alignment to align the noisy global pose of clients before the aggregation step. In experiments, we show the effectiveness of the proposed pose alignment and the federated learning pipeline on the large-scale scene dataset, Mill19.
Feature Space Particle Inference for Neural Network Ensembles
Jun 02, 2022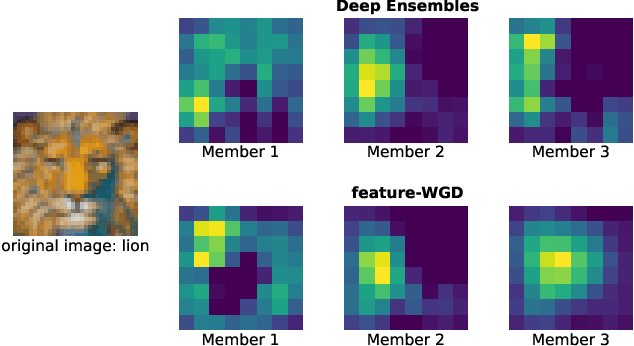


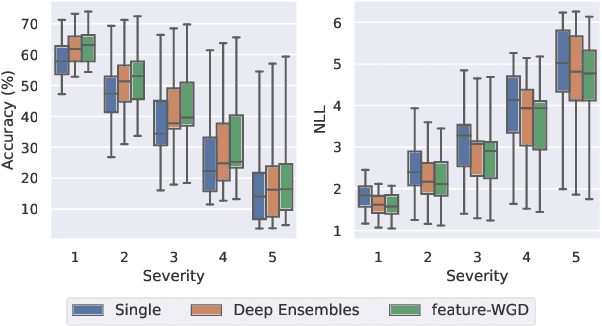
Ensembles of deep neural networks demonstrate improved performance over single models. For enhancing the diversity of ensemble members while keeping their performance, particle-based inference methods offer a promising approach from a Bayesian perspective. However, the best way to apply these methods to neural networks is still unclear: seeking samples from the weight-space posterior suffers from inefficiency due to the over-parameterization issues, while seeking samples directly from the function-space posterior often results in serious underfitting. In this study, we propose optimizing particles in the feature space where the activation of a specific intermediate layer lies to address the above-mentioned difficulties. Our method encourages each member to capture distinct features, which is expected to improve ensemble prediction robustness. Extensive evaluation on real-world datasets shows that our model significantly outperforms the gold-standard Deep Ensembles on various metrics, including accuracy, calibration, and robustness. Code is available at https://github.com/DensoITLab/featurePI .
Clustering as Attention: Unified Image Segmentation with Hierarchical Clustering
May 20, 2022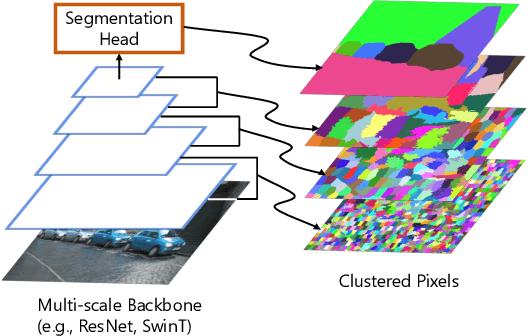
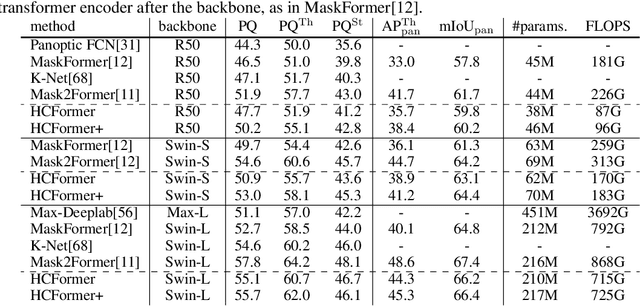
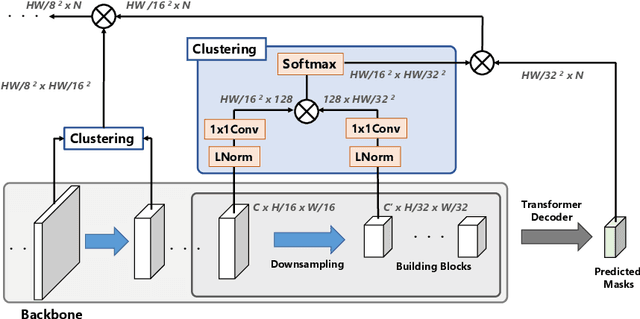
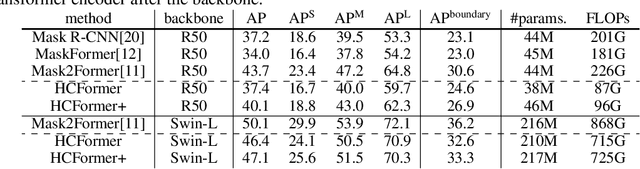
We propose a hierarchical clustering-based image segmentation scheme for deep neural networks, called HCFormer. We interpret image segmentation, including semantic, instance, and panoptic segmentation, as a pixel clustering problem, and accomplish it by bottom-up, hierarchical clustering with deep neural networks. Our hierarchical clustering removes the pixel decoder from conventional segmentation models and simplifies the segmentation pipeline, resulting in improved segmentation accuracies and interpretability. HCFormer can address semantic, instance, and panoptic segmentation with the same architecture because the pixel clustering is a common approach for various image segmentation. In experiments, HCFormer achieves comparable or superior segmentation accuracies compared to baseline methods on semantic segmentation (55.5 mIoU on ADE20K), instance segmentation (47.1 AP on COCO), and panoptic segmentation (55.7 PQ on COCO).
TeachAugment: Data Augmentation Optimization Using Teacher Knowledge
Mar 28, 2022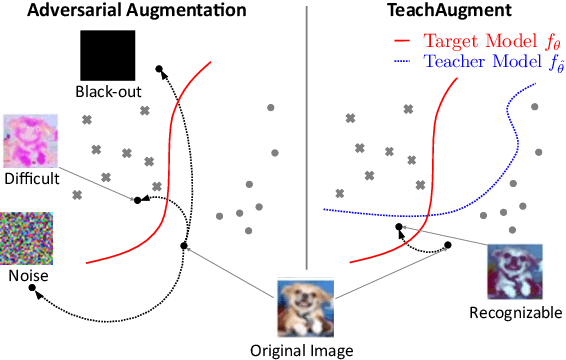

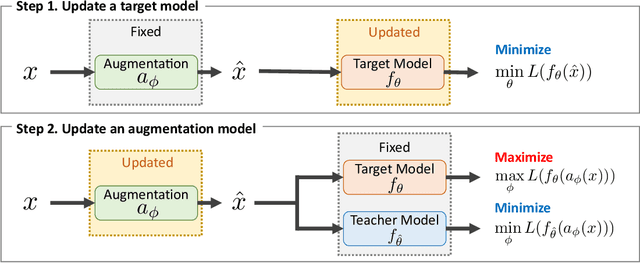
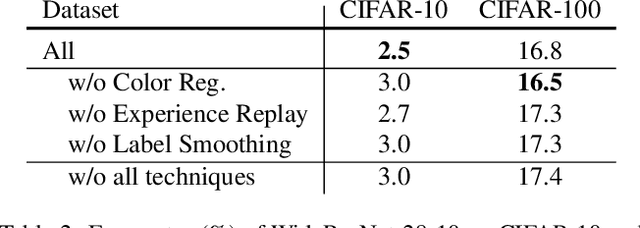
Optimization of image transformation functions for the purpose of data augmentation has been intensively studied. In particular, adversarial data augmentation strategies, which search augmentation maximizing task loss, show significant improvement in the model generalization for many tasks. However, the existing methods require careful parameter tuning to avoid excessively strong deformations that take away image features critical for acquiring generalization. In this paper, we propose a data augmentation optimization method based on the adversarial strategy called TeachAugment, which can produce informative transformed images to the model without requiring careful tuning by leveraging a teacher model. Specifically, the augmentation is searched so that augmented images are adversarial for the target model and recognizable for the teacher model. We also propose data augmentation using neural networks, which simplifies the search space design and allows for updating of the data augmentation using the gradient method. We show that TeachAugment outperforms existing methods in experiments of image classification, semantic segmentation, and unsupervised representation learning tasks.
Implicit Integration of Superpixel Segmentation into Fully Convolutional Networks
Mar 05, 2021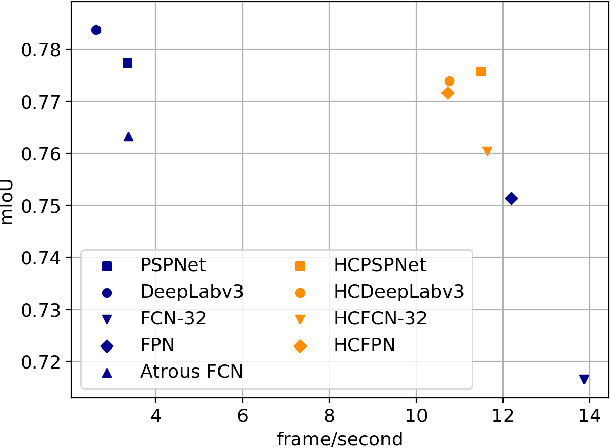
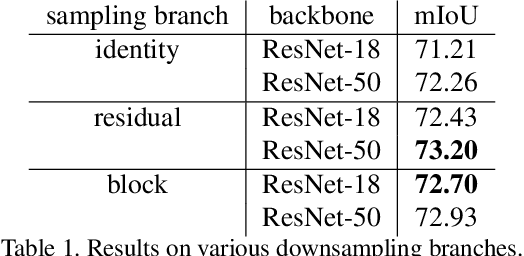

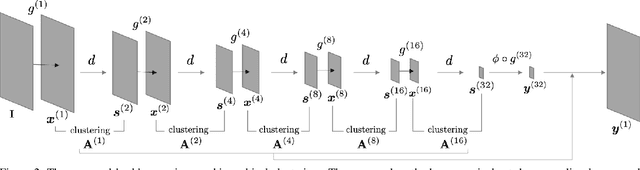
Superpixels are a useful representation to reduce the complexity of image data. However, to combine superpixels with convolutional neural networks (CNNs) in an end-to-end fashion, one requires extra models to generate superpixels and special operations such as graph convolution. In this paper, we propose a way to implicitly integrate a superpixel scheme into CNNs, which makes it easy to use superpixels with CNNs in an end-to-end fashion. Our proposed method hierarchically groups pixels at downsampling layers and generates superpixels. Our method can be plugged into many existing architectures without a change in their feed-forward path because our method does not use superpixels in the feed-forward path but use them to recover the lost resolution instead of bilinear upsampling. As a result, our method preserves detailed information such as object boundaries in the form of superpixels even when the model contains downsampling layers. We evaluate our method on several tasks such as semantic segmentation, superpixel segmentation, and monocular depth estimation, and confirm that it speeds up modern architectures and/or improves their prediction accuracy in these tasks.
Irregularly Tabulated MLP for Fast Point Feature Embedding
Nov 13, 2020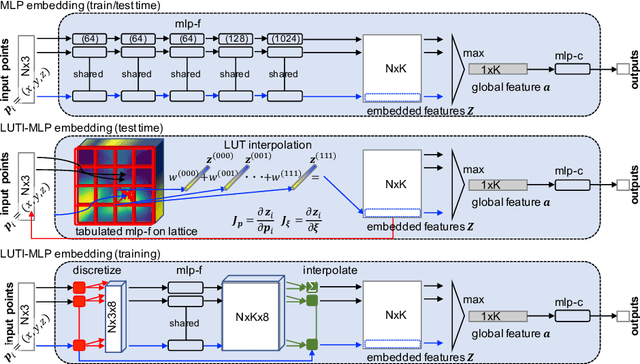
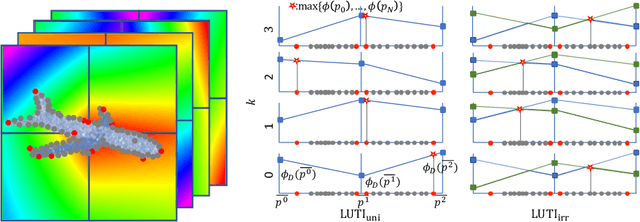
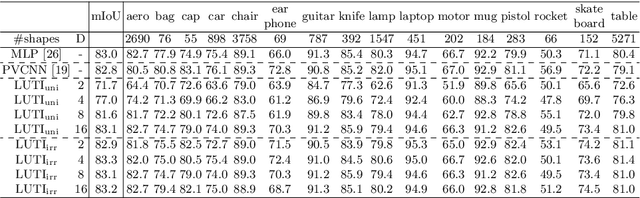
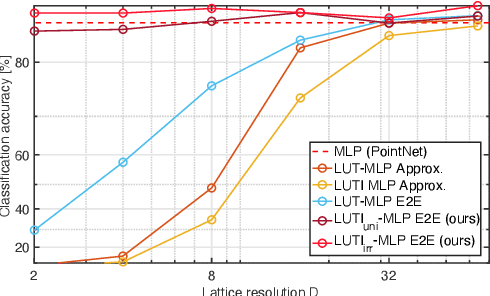
Aiming at drastic speedup for point-feature embeddings at test time, we propose a new framework that uses a pair of multi-layer perceptrons (MLP) and a lookup table (LUT) to transform point-coordinate inputs into high-dimensional features. When compared with PointNet's feature embedding part realized by MLP that requires millions of dot products, the proposed framework at test time requires no such layers of matrix-vector products but requires only looking up the nearest entities from the tabulated MLP followed by interpolation, defined over discrete inputs on a 3D lattice that is substantially arranged irregularly. We call this framework LUTI-MLP: LUT Interpolation ML that provides a way to train end-to-end irregularly tabulated MLP coupled to a LUT in a specific manner without the need for any approximation at test time. LUTI-MLP also provides significant speedup for Jacobian computation of the embedding function wrt global pose coordinate on Lie algebra $\mathfrak{se}(3)$ at test time, which could be used for point-set registration problems. After extensive evaluation using the ModelNet40, we confirmed that the LUTI-MLP even with a small (e.g., $4^3$) lattice yields performance comparable to that of the MLP while achieving significant speedup: $100\times$ for the embedding, $12\times$ for the approximate Jacobian, and $860\times$ for the canonical Jacobian.