 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTakeuchi's Information Criteria as Generalization Measures for DNNs Close to NTK Regime
Feb 26, 2026Generalization measures have been studied extensively in the machine learning community to better characterize generalization gaps. However, establishing a reliable generalization measure for statistically singular models such as deep neural networks (DNNs) is difficult due to their complex nature. This study focuses on Takeuchi's information criterion (TIC) to investigate the conditions under which this classical measure can effectively explain the generalization gaps of DNNs. Importantly, the developed theory indicates the applicability of TIC near the neural tangent kernel (NTK) regime. In a series of experiments, we trained more than 5,000 DNN models with 12 architectures, including large models (e.g., VGG-16), on four datasets, and estimated the corresponding TIC values to examine the relationship between the generalization gap and the TIC estimates. We applied several TIC approximation methods with feasible computational costs and assessed the accuracy trade-off. Our experimental results indicate that the estimated TIC values correlate well with the generalization gap under conditions close to the NTK regime. However, we show both theoretically and empirically that outside the NTK regime such correlation disappears. Finally, we demonstrate that TIC provides better trial pruning ability than existing methods for hyperparameter optimization.
Rectified Lagrangian for Out-of-Distribution Detection in Modern Hopfield Networks
Feb 19, 2025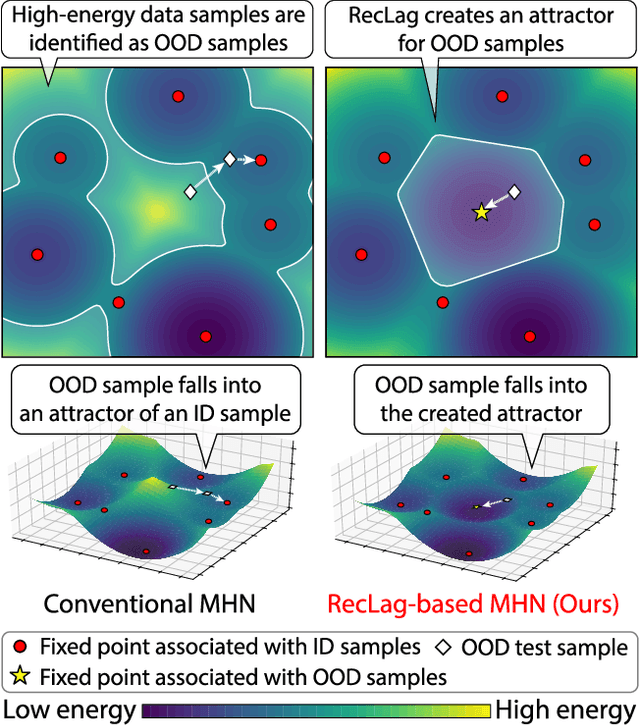
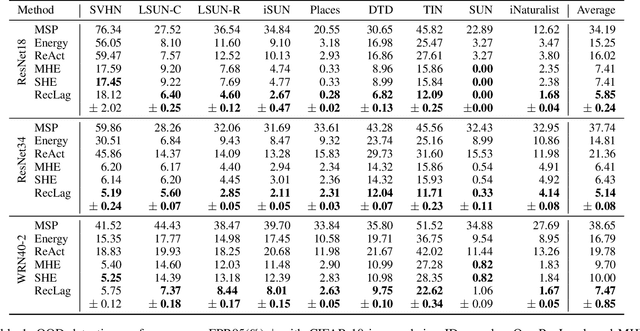
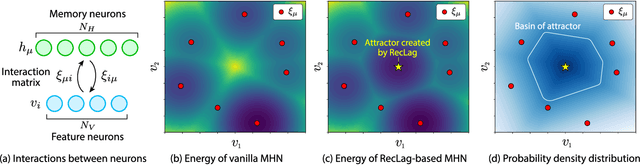
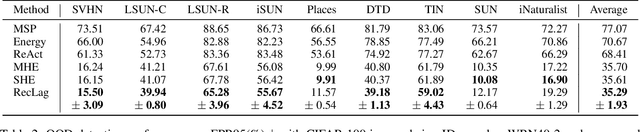
Modern Hopfield networks (MHNs) have recently gained significant attention in the field of artificial intelligence because they can store and retrieve a large set of patterns with an exponentially large memory capacity. A MHN is generally a dynamical system defined with Lagrangians of memory and feature neurons, where memories associated with in-distribution (ID) samples are represented by attractors in the feature space. One major problem in existing MHNs lies in managing out-of-distribution (OOD) samples because it was originally assumed that all samples are ID samples. To address this, we propose the rectified Lagrangian (RegLag), a new Lagrangian for memory neurons that explicitly incorporates an attractor for OOD samples in the dynamical system of MHNs. RecLag creates a trivial point attractor for any interaction matrix, enabling OOD detection by identifying samples that fall into this attractor as OOD. The interaction matrix is optimized so that the probability densities can be estimated to identify ID/OOD. We demonstrate the effectiveness of RecLag-based MHNs compared to energy-based OOD detection methods, including those using state-of-the-art Hopfield energies, across nine image datasets.
GUMBEL-NERF: Representing Unseen Objects as Part-Compositional Neural Radiance Fields
Oct 27, 2024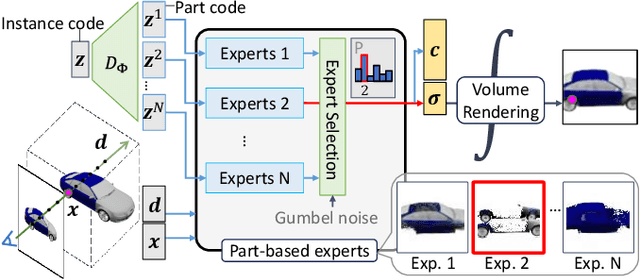
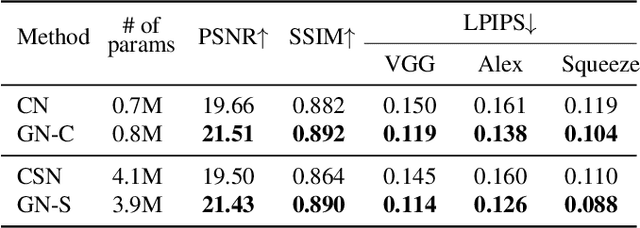
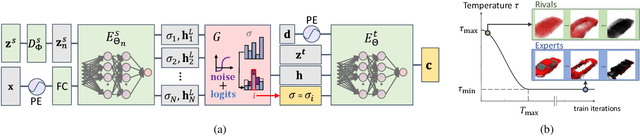
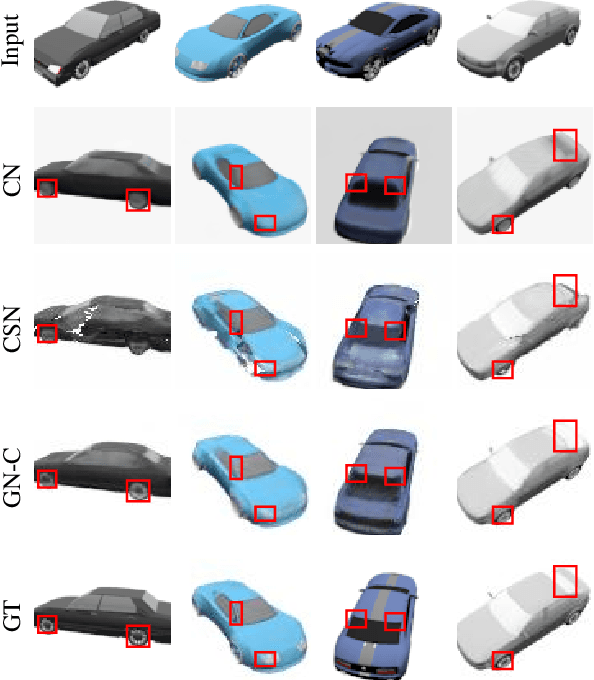
We propose Gumbel-NeRF, a mixture-of-expert (MoE) neural radiance fields (NeRF) model with a hindsight expert selection mechanism for synthesizing novel views of unseen objects. Previous studies have shown that the MoE structure provides high-quality representations of a given large-scale scene consisting of many objects. However, we observe that such a MoE NeRF model often produces low-quality representations in the vicinity of experts' boundaries when applied to the task of novel view synthesis of an unseen object from one/few-shot input. We find that this deterioration is primarily caused by the foresight expert selection mechanism, which may leave an unnatural discontinuity in the object shape near the experts' boundaries. Gumbel-NeRF adopts a hindsight expert selection mechanism, which guarantees continuity in the density field even near the experts' boundaries. Experiments using the SRN cars dataset demonstrate the superiority of Gumbel-NeRF over the baselines in terms of various image quality metrics.
Fixed-Weight Difference Target Propagation
Dec 19, 2022



Target Propagation (TP) is a biologically more plausible algorithm than the error backpropagation (BP) to train deep networks, and improving practicality of TP is an open issue. TP methods require the feedforward and feedback networks to form layer-wise autoencoders for propagating the target values generated at the output layer. However, this causes certain drawbacks; e.g., careful hyperparameter tuning is required to synchronize the feedforward and feedback training, and frequent updates of the feedback path are usually required than that of the feedforward path. Learning of the feedforward and feedback networks is sufficient to make TP methods capable of training, but is having these layer-wise autoencoders a necessary condition for TP to work? We answer this question by presenting Fixed-Weight Difference Target Propagation (FW-DTP) that keeps the feedback weights constant during training. We confirmed that this simple method, which naturally resolves the abovementioned problems of TP, can still deliver informative target values to hidden layers for a given task; indeed, FW-DTP consistently achieves higher test performance than a baseline, the Difference Target Propagation (DTP), on four classification datasets. We also present a novel propagation architecture that explains the exact form of the feedback function of DTP to analyze FW-DTP.
Informative Sample-Aware Proxy for Deep Metric Learning
Nov 18, 2022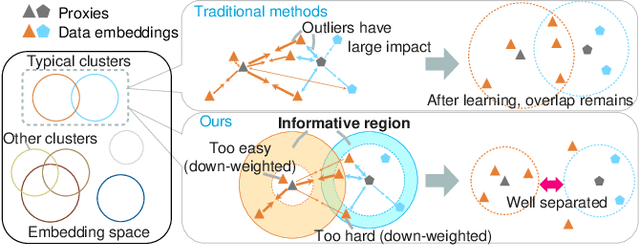
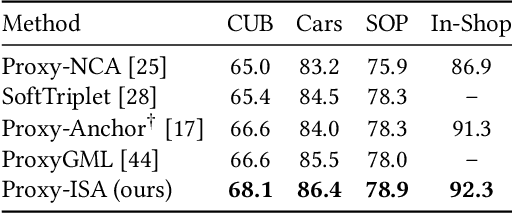

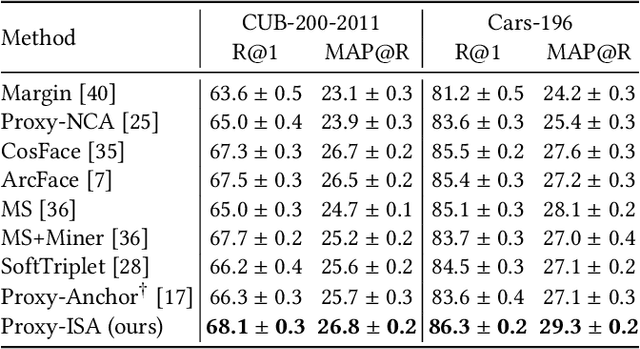
Among various supervised deep metric learning methods proxy-based approaches have achieved high retrieval accuracies. Proxies, which are class-representative points in an embedding space, receive updates based on proxy-sample similarities in a similar manner to sample representations. In existing methods, a relatively small number of samples can produce large gradient magnitudes (ie, hard samples), and a relatively large number of samples can produce small gradient magnitudes (ie, easy samples); these can play a major part in updates. Assuming that acquiring too much sensitivity to such extreme sets of samples would deteriorate the generalizability of a method, we propose a novel proxy-based method called Informative Sample-Aware Proxy (Proxy-ISA), which directly modifies a gradient weighting factor for each sample using a scheduled threshold function, so that the model is more sensitive to the informative samples. Extensive experiments on the CUB-200-2011, Cars-196, Stanford Online Products and In-shop Clothes Retrieval datasets demonstrate the superiority of Proxy-ISA compared with the state-of-the-art methods.
Empirical Study on Optimizer Selection for Out-of-Distribution Generalization
Nov 18, 2022



Modern deep learning systems are fragile and do not generalize well under distribution shifts. While much promising work has been accomplished to address these concerns, a systematic study of the role of optimizers and their out-of-distribution generalization performance has not been undertaken. In this study, we examine the performance of popular first-order optimizers for different classes of distributional shift under empirical risk minimization and invariant risk minimization. We address the problem settings for image and text classification using DomainBed, WILDS, and Backgrounds Challenge as out-of-distribution datasets for the exhaustive study. We search over a wide range of hyperparameters and examine the classification accuracy (in-distribution and out-of-distribution) for over 20,000 models. We arrive at the following findings: i) contrary to conventional wisdom, adaptive optimizers (e.g., Adam) perform worse than non-adaptive optimizers (e.g., SGD, momentum-based SGD), ii) in-distribution performance and out-of-distribution performance exhibit three types of behavior depending on the dataset - linear returns, increasing returns, and diminishing returns. We believe these findings can help practitioners choose the right optimizer and know what behavior to expect.
PoF: Post-Training of Feature Extractor for Improving Generalization
Jul 05, 2022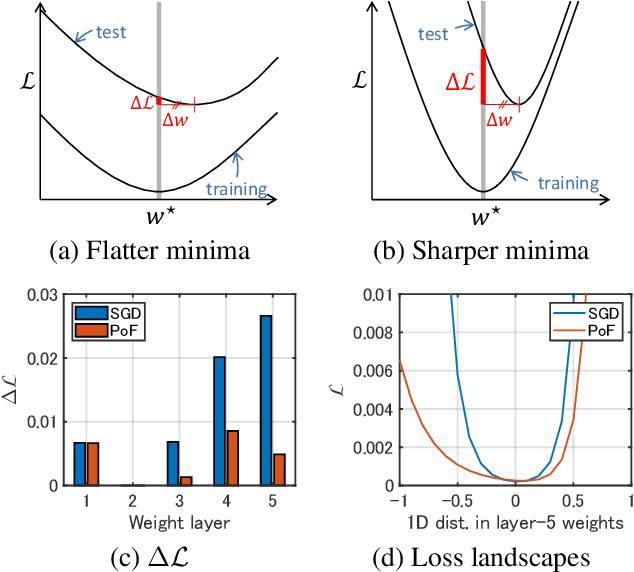
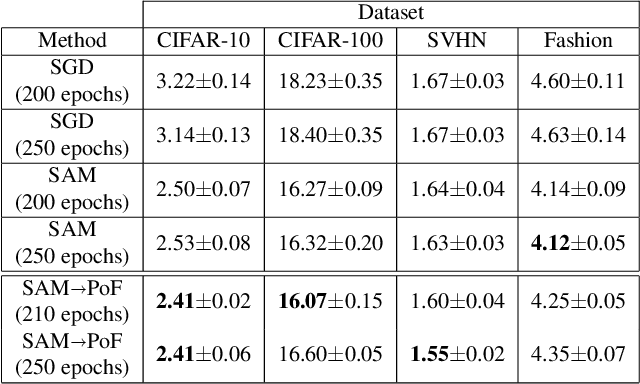
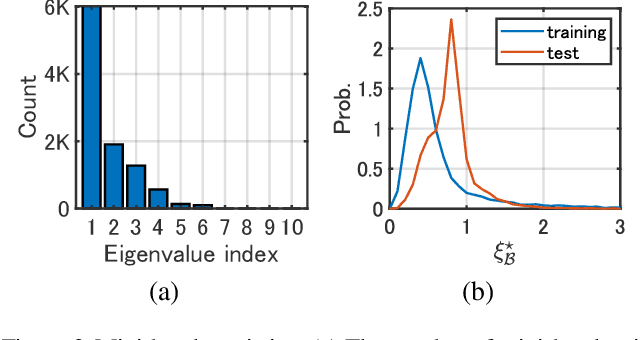
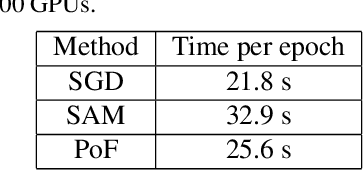
It has been intensively investigated that the local shape, especially flatness, of the loss landscape near a minimum plays an important role for generalization of deep models. We developed a training algorithm called PoF: Post-Training of Feature Extractor that updates the feature extractor part of an already-trained deep model to search a flatter minimum. The characteristics are two-fold: 1) Feature extractor is trained under parameter perturbations in the higher-layer parameter space, based on observations that suggest flattening higher-layer parameter space, and 2) the perturbation range is determined in a data-driven manner aiming to reduce a part of test loss caused by the positive loss curvature. We provide a theoretical analysis that shows the proposed algorithm implicitly reduces the target Hessian components as well as the loss. Experimental results show that PoF improved model performance against baseline methods on both CIFAR-10 and CIFAR-100 datasets for only 10-epoch post-training, and on SVHN dataset for 50-epoch post-training. Source code is available at: \url{https://github.com/DensoITLab/PoF-v1
Feature Space Particle Inference for Neural Network Ensembles
Jun 02, 2022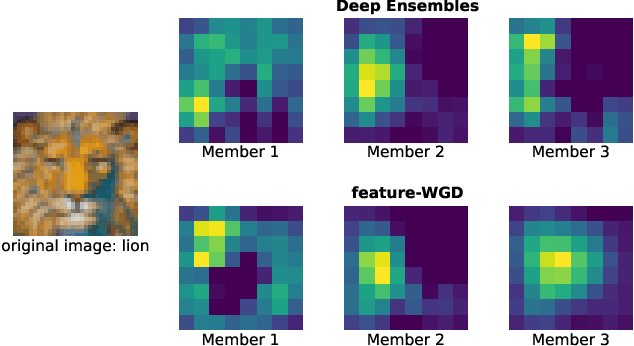


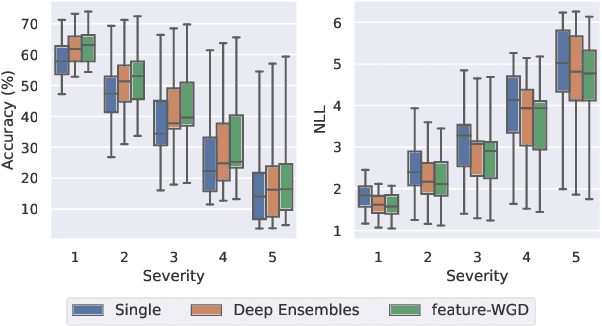
Ensembles of deep neural networks demonstrate improved performance over single models. For enhancing the diversity of ensemble members while keeping their performance, particle-based inference methods offer a promising approach from a Bayesian perspective. However, the best way to apply these methods to neural networks is still unclear: seeking samples from the weight-space posterior suffers from inefficiency due to the over-parameterization issues, while seeking samples directly from the function-space posterior often results in serious underfitting. In this study, we propose optimizing particles in the feature space where the activation of a specific intermediate layer lies to address the above-mentioned difficulties. Our method encourages each member to capture distinct features, which is expected to improve ensemble prediction robustness. Extensive evaluation on real-world datasets shows that our model significantly outperforms the gold-standard Deep Ensembles on various metrics, including accuracy, calibration, and robustness. Code is available at https://github.com/DensoITLab/featurePI .
Implicit Neural Representations for Variable Length Human Motion Generation
Mar 25, 2022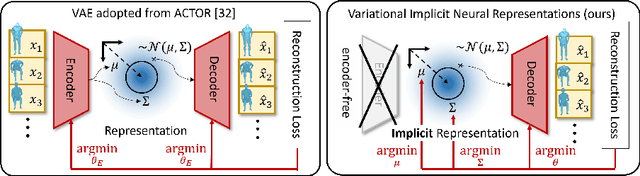
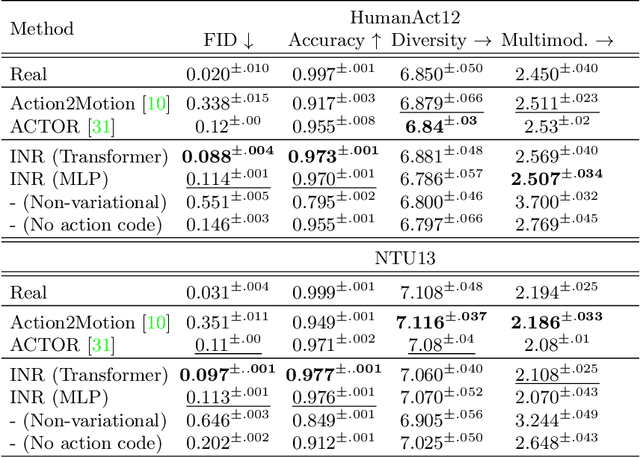
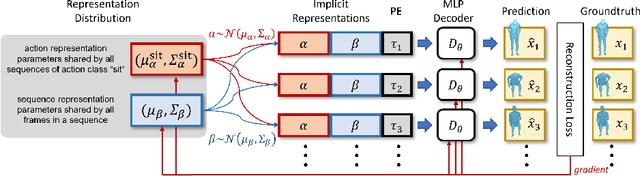

We propose an action-conditional human motion generation method using variational implicit neural representations (INR). The variational formalism enables action-conditional distributions of INRs, from which one can easily sample representations to generate novel human motion sequences. Our method offers variable-length sequence generation by construction because a part of INR is optimized for a whole sequence of arbitrary length with temporal embeddings. In contrast, previous works reported difficulties with modeling variable-length sequences. We confirm that our method with a Transformer decoder outperforms all relevant methods on HumanAct12, NTU-RGBD, and UESTC datasets in terms of realism and diversity of generated motions. Surprisingly, even our method with an MLP decoder consistently outperforms the state-of-the-art Transformer-based auto-encoder. In particular, we show that variable-length motions generated by our method are better than fixed-length motions generated by the state-of-the-art method in terms of realism and diversity.
Adversarial Transformations for Semi-Supervised Learning
Nov 18, 2019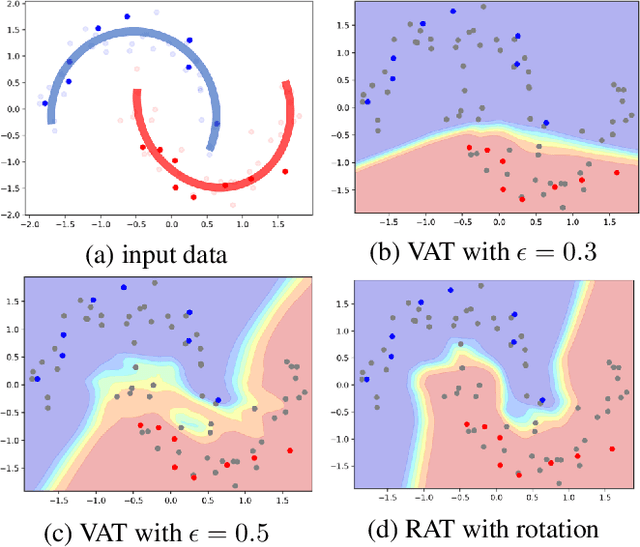


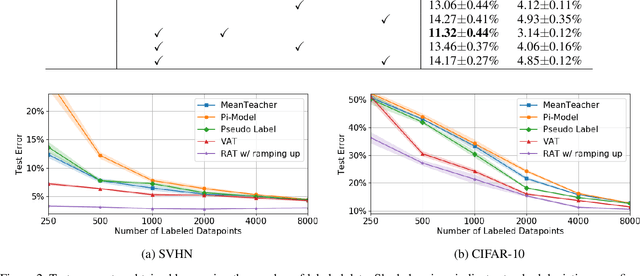
We propose a Regularization framework based on Adversarial Transformations (RAT) for semi-supervised learning. RAT is designed to enhance robustness of the output distribution of class prediction for a given data against input perturbation. RAT is an extension of Virtual Adversarial Training (VAT) in such a way that RAT adversarialy transforms data along the underlying data distribution by a rich set of data transformation functions that leave class label invariant, whereas VAT simply produces adversarial additive noises. In addition, we verified that a technique of gradually increasing of perturbation region further improve the robustness. In experiments, we show that RAT significantly improves classification performance on CIFAR-10 and SVHN compared to existing regularization methods under standard semi-supervised image classification settings.