 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Evaluating LLM-based Evaluation Functions for Research Question Extraction Task
Sep 10, 2024



The progress in text summarization techniques has been remarkable. However the task of accurately extracting and summarizing necessary information from highly specialized documents such as research papers has not been sufficiently investigated. We are focusing on the task of extracting research questions (RQ) from research papers and construct a new dataset consisting of machine learning papers, RQ extracted from these papers by GPT-4, and human evaluations of the extracted RQ from multiple perspectives. Using this dataset, we systematically compared recently proposed LLM-based evaluation functions for summarizations, and found that none of the functions showed sufficiently high correlations with human evaluations. We expect our dataset provides a foundation for further research on developing better evaluation functions tailored to the RQ extraction task, and contribute to enhance the performance of the task. The dataset is available at https://github.com/auto-res/PaperRQ-HumanAnno-Dataset.
Speculative Exploration on the Concept of Artificial Agents Conducting Autonomous Research
Dec 06, 2023This paper engages in a speculative exploration of the concept of an artificial agent capable of conducting research. Initially, it examines how the act of research can be conceptually characterized, aiming to provide a starting point for discussions about what it means to create such agents. The focus then shifts to the core components of research: question formulation, hypothesis generation, and hypothesis verification. This discussion includes a consideration of the potential and challenges associated with enabling machines to autonomously perform these tasks. Subsequently, this paper briefly considers the overlapping themes and interconnections that underlie them. Finally, the paper presents preliminary thoughts on prototyping as an initial step towards uncovering the challenges involved in developing these research-capable agents.
Towards Autonomous Hypothesis Verification via Language Models with Minimal Guidance
Nov 16, 2023Research automation efforts usually employ AI as a tool to automate specific tasks within the research process. To create an AI that truly conduct research themselves, it must independently generate hypotheses, design verification plans, and execute verification. Therefore, we investigated if an AI itself could autonomously generate and verify hypothesis for a toy machine learning research problem. We prompted GPT-4 to generate hypotheses and Python code for hypothesis verification with limited methodological guidance. Our findings suggest that, in some instances, GPT-4 can autonomously generate and validate hypotheses without detailed guidance. While this is a promising result, we also found that none of the verifications were flawless, and there remain significant challenges in achieving autonomous, human-level research using only generic instructions. These findings underscore the need for continued exploration to develop a general and autonomous AI researcher.
Empirical Study on Optimizer Selection for Out-of-Distribution Generalization
Nov 18, 2022



Modern deep learning systems are fragile and do not generalize well under distribution shifts. While much promising work has been accomplished to address these concerns, a systematic study of the role of optimizers and their out-of-distribution generalization performance has not been undertaken. In this study, we examine the performance of popular first-order optimizers for different classes of distributional shift under empirical risk minimization and invariant risk minimization. We address the problem settings for image and text classification using DomainBed, WILDS, and Backgrounds Challenge as out-of-distribution datasets for the exhaustive study. We search over a wide range of hyperparameters and examine the classification accuracy (in-distribution and out-of-distribution) for over 20,000 models. We arrive at the following findings: i) contrary to conventional wisdom, adaptive optimizers (e.g., Adam) perform worse than non-adaptive optimizers (e.g., SGD, momentum-based SGD), ii) in-distribution performance and out-of-distribution performance exhibit three types of behavior depending on the dataset - linear returns, increasing returns, and diminishing returns. We believe these findings can help practitioners choose the right optimizer and know what behavior to expect.
On the Effect of Pre-training for Transformer in Different Modality on Offline Reinforcement Learning
Nov 17, 2022We empirically investigate how pre-training on data of different modalities, such as language and vision, affects fine-tuning of Transformer-based models to Mujoco offline reinforcement learning tasks. Analysis of the internal representation reveals that the pre-trained Transformers acquire largely different representations before and after pre-training, but acquire less information of data in fine-tuning than the randomly initialized one. A closer look at the parameter changes of the pre-trained Transformers reveals that their parameters do not change that much and that the bad performance of the model pre-trained with image data could partially come from large gradients and gradient clipping. To study what information the Transformer pre-trained with language data utilizes, we fine-tune this model with no context provided, finding that the model learns efficiently even without context information. Subsequent follow-up analysis supports the hypothesis that pre-training with language data is likely to make the Transformer get context-like information and utilize it to solve the downstream task.
* 48 pages. Published in NeurIPS 2022
Convergence of neural networks to Gaussian mixture distribution
Apr 26, 2022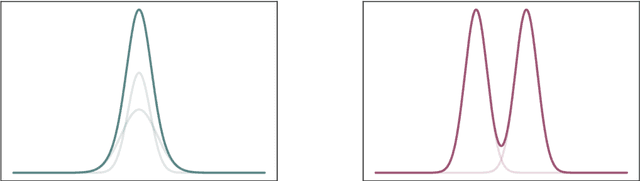
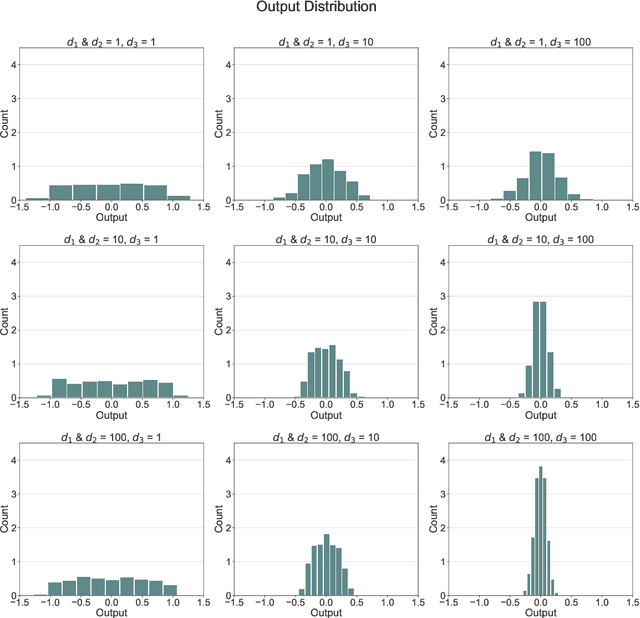
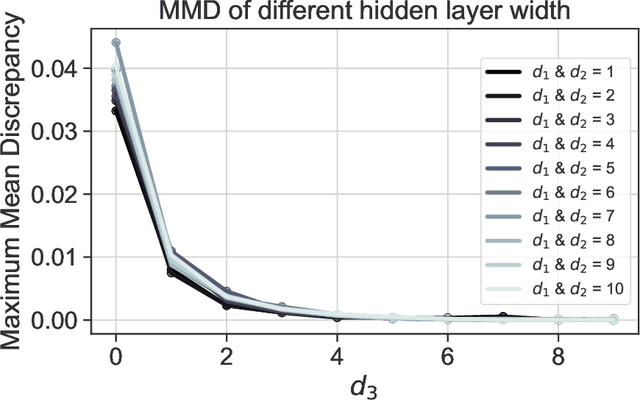
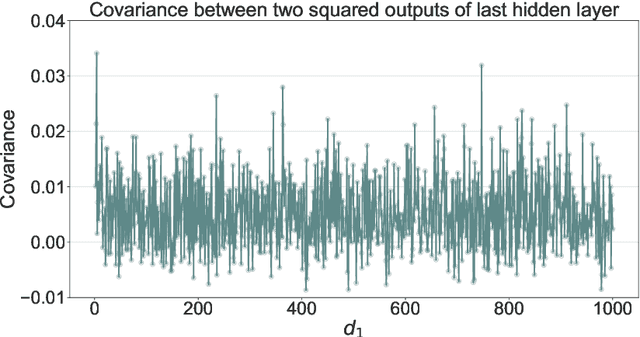
We give a proof that, under relatively mild conditions, fully-connected feed-forward deep random neural networks converge to a Gaussian mixture distribution as only the width of the last hidden layer goes to infinity. We conducted experiments for a simple model which supports our result. Moreover, it gives a detailed description of the convergence, namely, the growth of the last hidden layer gets the distribution closer to the Gaussian mixture, and the other layer successively get the Gaussian mixture closer to the normal distribution.
Image recognition via Vietoris-Rips complex
Sep 06, 2021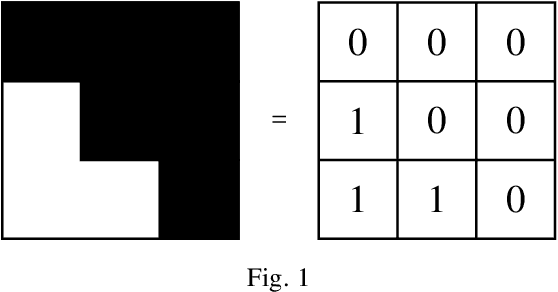
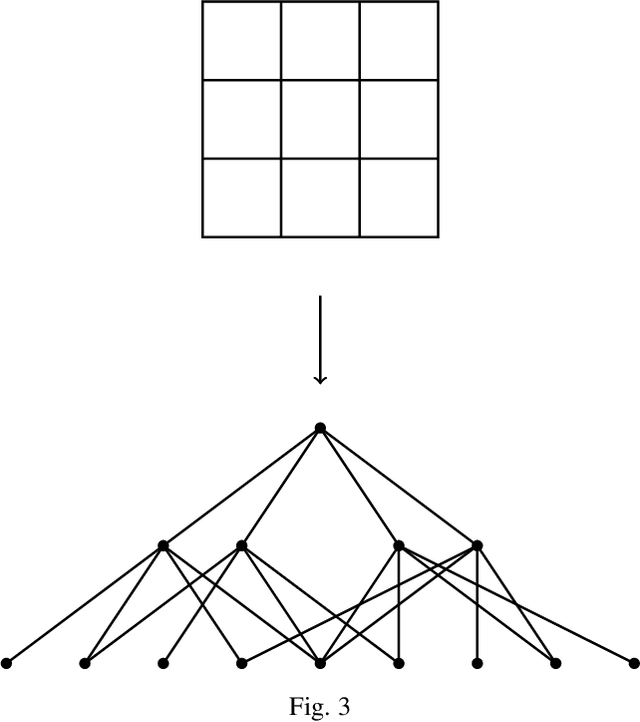
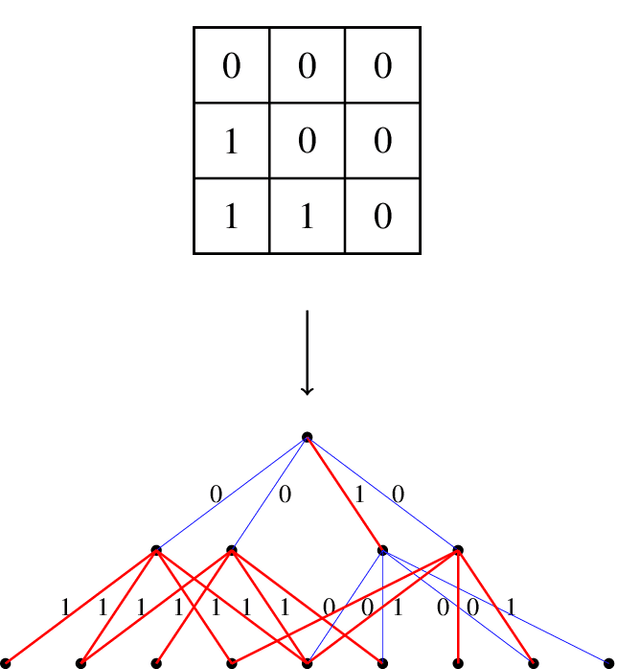
Extracting informative features from images has been of capital importance in computer vision. In this paper, we propose a way to extract such features from images by a method based on algebraic topology. To that end, we construct a weighted graph from an image, which extracts local information of an image. By considering this weighted graph as a pseudo-metric space, we construct a Vietoris-Rips complex with a parameter $\varepsilon$ by a well-known process of algebraic topology. We can extract information of complexity of the image and can detect a sub-image with a relatively high concentration of information from this Vietoris-Rips complex. The parameter $\varepsilon$ of the Vietoris-Rips complex produces robustness to noise. We empirically show that the extracted feature captures well images' characteristics.
Statistical Mechanical Analysis of Catastrophic Forgetting in Continual Learning with Teacher and Student Networks
May 16, 2021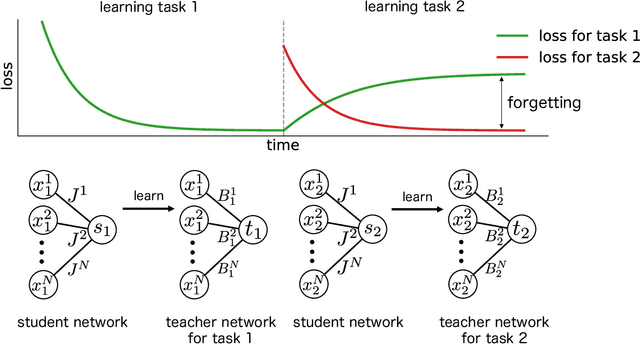
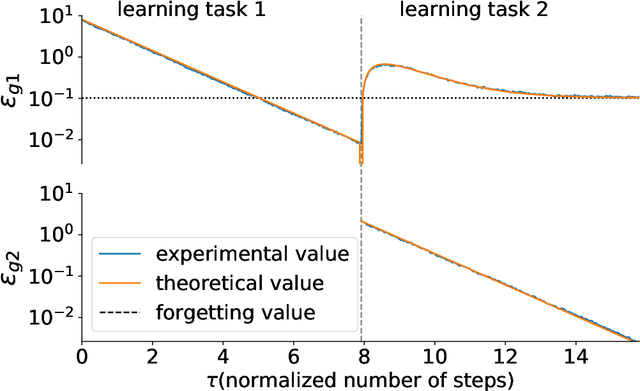
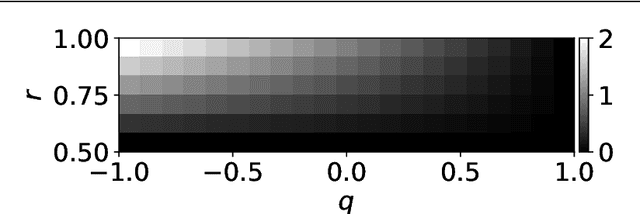
When a computational system continuously learns from an ever-changing environment, it rapidly forgets its past experiences. This phenomenon is called catastrophic forgetting. While a line of studies has been proposed with respect to avoiding catastrophic forgetting, most of the methods are based on intuitive insights into the phenomenon, and their performances have been evaluated by numerical experiments using benchmark datasets. Therefore, in this study, we provide the theoretical framework for analyzing catastrophic forgetting by using teacher-student learning. Teacher-student learning is a framework in which we introduce two neural networks: one neural network is a target function in supervised learning, and the other is a learning neural network. To analyze continual learning in the teacher-student framework, we introduce the similarity of the input distribution and the input-output relationship of the target functions as the similarity of tasks. In this theoretical framework, we also provide a qualitative understanding of how a single-layer linear learning neural network forgets tasks. Based on the analysis, we find that the network can avoid catastrophic forgetting when the similarity among input distributions is small and that of the input-output relationship of the target functions is large. The analysis also suggests that a system often exhibits a characteristic phenomenon called overshoot, which means that even if the learning network has once undergone catastrophic forgetting, it is possible that the network may perform reasonably well after further learning of the current task.