 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Evaluating LLM-based Evaluation Functions for Research Question Extraction Task
Sep 10, 2024



The progress in text summarization techniques has been remarkable. However the task of accurately extracting and summarizing necessary information from highly specialized documents such as research papers has not been sufficiently investigated. We are focusing on the task of extracting research questions (RQ) from research papers and construct a new dataset consisting of machine learning papers, RQ extracted from these papers by GPT-4, and human evaluations of the extracted RQ from multiple perspectives. Using this dataset, we systematically compared recently proposed LLM-based evaluation functions for summarizations, and found that none of the functions showed sufficiently high correlations with human evaluations. We expect our dataset provides a foundation for further research on developing better evaluation functions tailored to the RQ extraction task, and contribute to enhance the performance of the task. The dataset is available at https://github.com/auto-res/PaperRQ-HumanAnno-Dataset.
Corner case data description and detection
Jan 07, 2021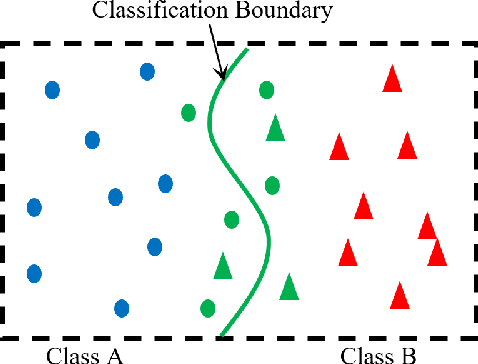
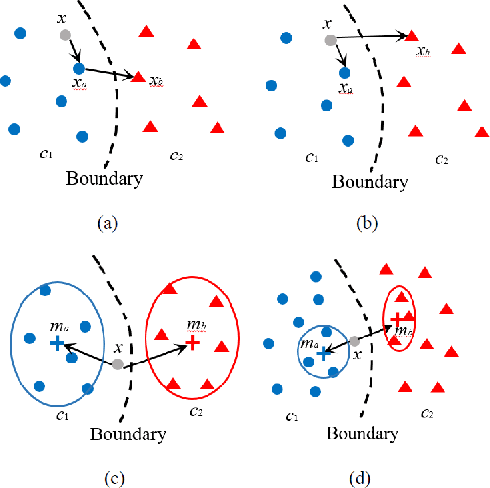
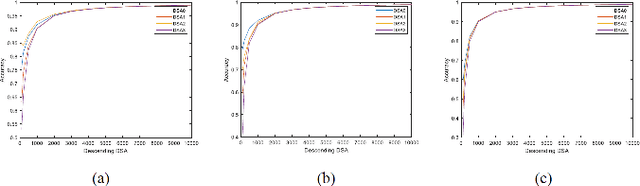

As the major factors affecting the safety of deep learning models, corner cases and related detection are crucial in AI quality assurance for constructing safety- and security-critical systems. The generic corner case researches involve two interesting topics. One is to enhance DL models robustness to corner case data via the adjustment on parameters/structure. The other is to generate new corner cases for model retraining and improvement. However, the complex architecture and the huge amount of parameters make the robust adjustment of DL models not easy, meanwhile it is not possible to generate all real-world corner cases for DL training. Therefore, this paper proposes to a simple and novel study aiming at corner case data detection via a specific metric. This metric is developed on surprise adequacy (SA) which has advantages on capture data behaviors. Furthermore, targeting at characteristics of corner case data, three modifications on distanced-based SA are developed for classification applications in this paper. Consequently, through the experiment analysis on MNIST data and industrial data, the feasibility and usefulness of the proposed method on corner case data detection are verified.
Self-paced Data Augmentation for Training Neural Networks
Oct 29, 2020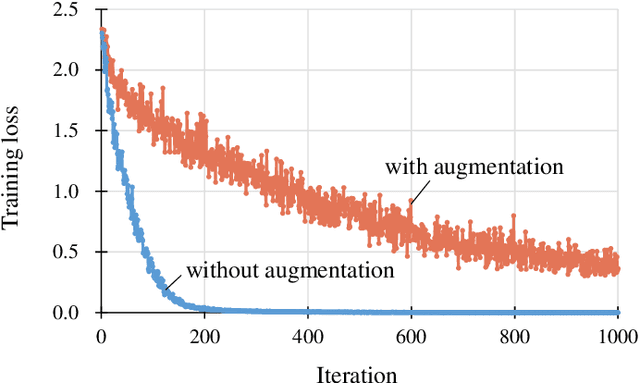
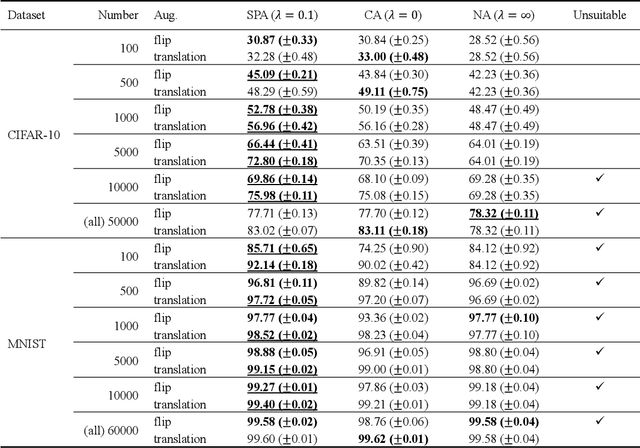
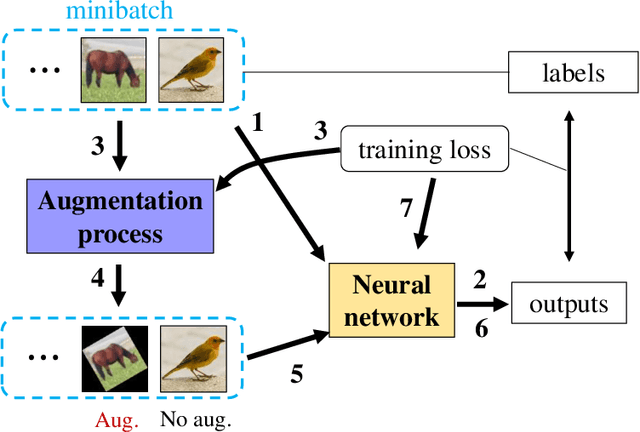
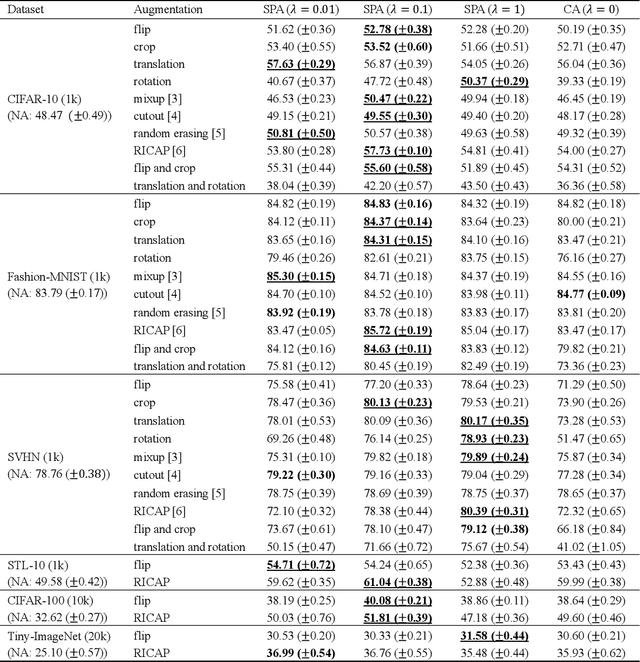
Data augmentation is widely used for machine learning; however, an effective method to apply data augmentation has not been established even though it includes several factors that should be tuned carefully. One such factor is sample suitability, which involves selecting samples that are suitable for data augmentation. A typical method that applies data augmentation to all training samples disregards sample suitability, which may reduce classifier performance. To address this problem, we propose the self-paced augmentation (SPA) to automatically and dynamically select suitable samples for data augmentation when training a neural network. The proposed method mitigates the deterioration of generalization performance caused by ineffective data augmentation. We discuss two reasons the proposed SPA works relative to curriculum learning and desirable changes to loss function instability. Experimental results demonstrate that the proposed SPA can improve the generalization performance, particularly when the number of training samples is small. In addition, the proposed SPA outperforms the state-of-the-art RandAugment method.
Describing Semantic Representations of Brain Activity Evoked by Visual Stimuli
Jan 19, 2018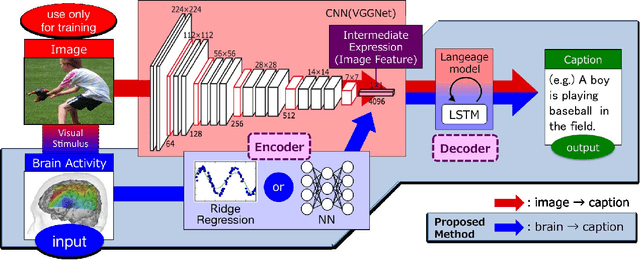
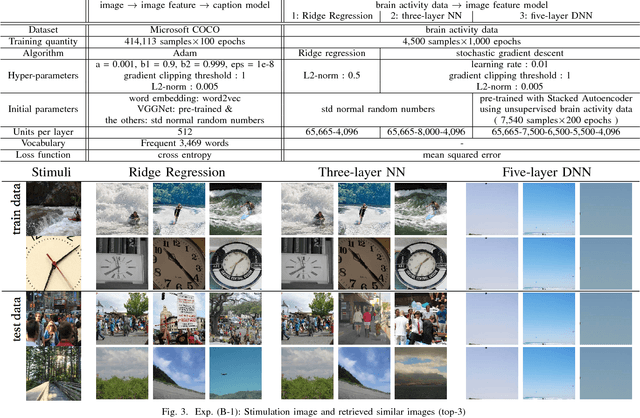


Quantitative modeling of human brain activity based on language representations has been actively studied in systems neuroscience. However, previous studies examined word-level representation, and little is known about whether we could recover structured sentences from brain activity. This study attempts to generate natural language descriptions of semantic contents from human brain activity evoked by visual stimuli. To effectively use a small amount of available brain activity data, our proposed method employs a pre-trained image-captioning network model using a deep learning framework. To apply brain activity to the image-captioning network, we train regression models that learn the relationship between brain activity and deep-layer image features. The results demonstrate that the proposed model can decode brain activity and generate descriptions using natural language sentences. We also conducted several experiments with data from different subsets of brain regions known to process visual stimuli. The results suggest that semantic information for sentence generations is widespread across the entire cortex.
Symbol Emergence in Robotics: A Survey
Sep 29, 2015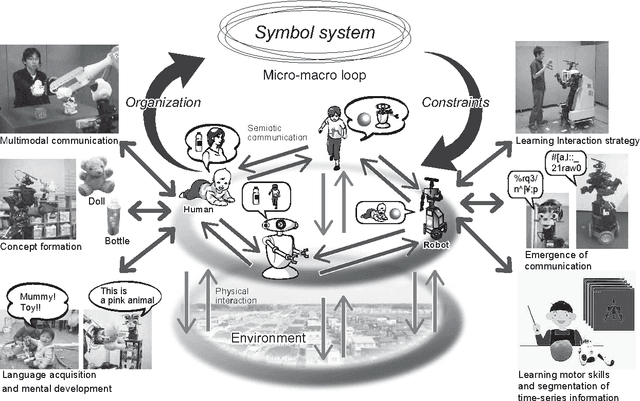
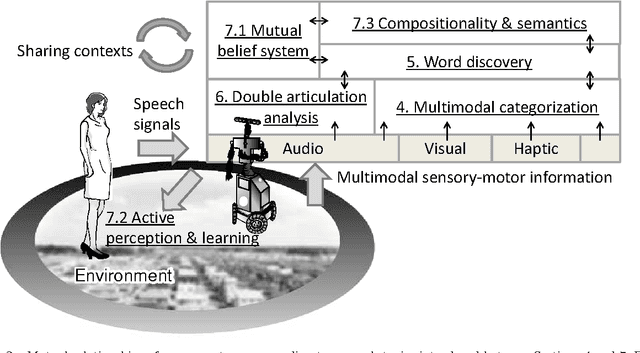

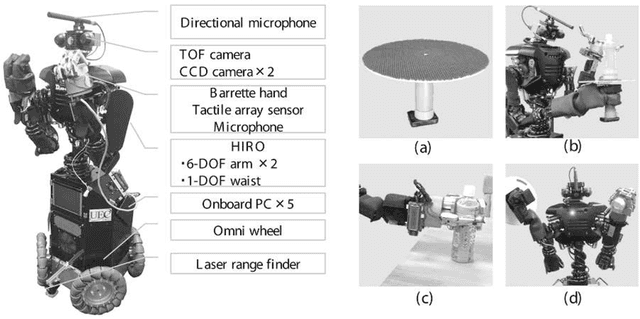
Humans can learn the use of language through physical interaction with their environment and semiotic communication with other people. It is very important to obtain a computational understanding of how humans can form a symbol system and obtain semiotic skills through their autonomous mental development. Recently, many studies have been conducted on the construction of robotic systems and machine-learning methods that can learn the use of language through embodied multimodal interaction with their environment and other systems. Understanding human social interactions and developing a robot that can smoothly communicate with human users in the long term, requires an understanding of the dynamics of symbol systems and is crucially important. The embodied cognition and social interaction of participants gradually change a symbol system in a constructive manner. In this paper, we introduce a field of research called symbol emergence in robotics (SER). SER is a constructive approach towards an emergent symbol system. The emergent symbol system is socially self-organized through both semiotic communications and physical interactions with autonomous cognitive developmental agents, i.e., humans and developmental robots. Specifically, we describe some state-of-art research topics concerning SER, e.g., multimodal categorization, word discovery, and a double articulation analysis, that enable a robot to obtain words and their embodied meanings from raw sensory--motor information, including visual information, haptic information, auditory information, and acoustic speech signals, in a totally unsupervised manner. Finally, we suggest future directions of research in SER.