 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrespondence of high-dimensional emotion structures elicited by video clips between humans and Multimodal LLMs
May 19, 2025Recent studies have revealed that human emotions exhibit a high-dimensional, complex structure. A full capturing of this complexity requires new approaches, as conventional models that disregard high dimensionality risk overlooking key nuances of human emotions. Here, we examined the extent to which the latest generation of rapidly evolving Multimodal Large Language Models (MLLMs) capture these high-dimensional, intricate emotion structures, including capabilities and limitations. Specifically, we compared self-reported emotion ratings from participants watching videos with model-generated estimates (e.g., Gemini or GPT). We evaluated performance not only at the individual video level but also from emotion structures that account for inter-video relationships. At the level of simple correlation between emotion structures, our results demonstrated strong similarity between human and model-inferred emotion structures. To further explore whether the similarity between humans and models is at the signle item level or the coarse-categorical level, we applied Gromov Wasserstein Optimal Transport. We found that although performance was not necessarily high at the strict, single-item level, performance across video categories that elicit similar emotions was substantial, indicating that the model could infer human emotional experiences at the category level. Our results suggest that current state-of-the-art MLLMs broadly capture the complex high-dimensional emotion structures at the category level, as well as their apparent limitations in accurately capturing entire structures at the single-item level.
Triple Phase Transitions: Understanding the Learning Dynamics of Large Language Models from a Neuroscience Perspective
Feb 28, 2025Large language models (LLMs) often exhibit abrupt emergent behavior, whereby new abilities arise at certain points during their training. This phenomenon, commonly referred to as a ''phase transition'', remains poorly understood. In this study, we conduct an integrative analysis of such phase transitions by examining three interconnected perspectives: the similarity between LLMs and the human brain, the internal states of LLMs, and downstream task performance. We propose a novel interpretation for the learning dynamics of LLMs that vary in both training data and architecture, revealing that three phase transitions commonly emerge across these models during training: (1) alignment with the entire brain surges as LLMs begin adhering to task instructions Brain Alignment and Instruction Following, (2) unexpectedly, LLMs diverge from the brain during a period in which downstream task accuracy temporarily stagnates Brain Detachment and Stagnation, and (3) alignment with the brain reoccurs as LLMs become capable of solving the downstream tasks Brain Realignment and Consolidation. These findings illuminate the underlying mechanisms of phase transitions in LLMs, while opening new avenues for interdisciplinary research bridging AI and neuroscience.
LaVCa: LLM-assisted Visual Cortex Captioning
Feb 19, 2025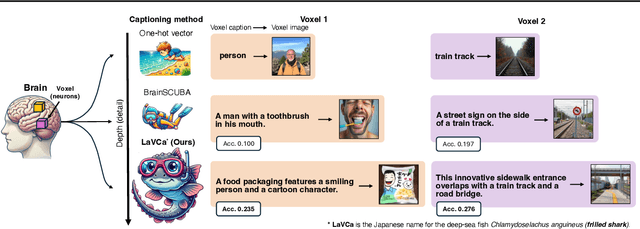

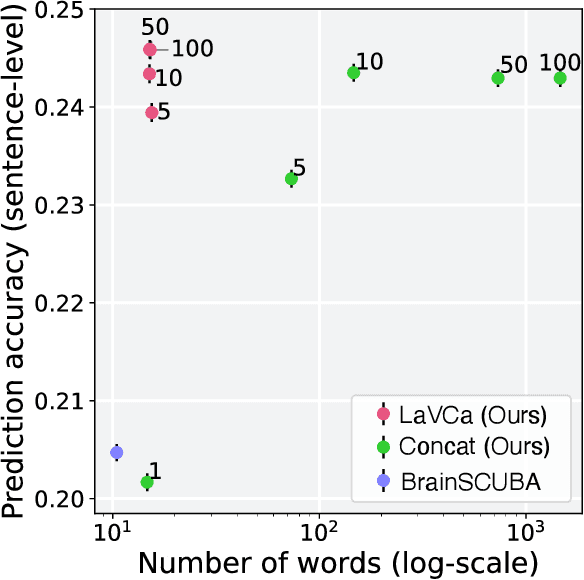

Understanding the property of neural populations (or voxels) in the human brain can advance our comprehension of human perceptual and cognitive processing capabilities and contribute to developing brain-inspired computer models. Recent encoding models using deep neural networks (DNNs) have successfully predicted voxel-wise activity. However, interpreting the properties that explain voxel responses remains challenging because of the black-box nature of DNNs. As a solution, we propose LLM-assisted Visual Cortex Captioning (LaVCa), a data-driven approach that uses large language models (LLMs) to generate natural-language captions for images to which voxels are selective. By applying LaVCa for image-evoked brain activity, we demonstrate that LaVCa generates captions that describe voxel selectivity more accurately than the previously proposed method. Furthermore, the captions generated by LaVCa quantitatively capture more detailed properties than the existing method at both the inter-voxel and intra-voxel levels. Furthermore, a more detailed analysis of the voxel-specific properties generated by LaVCa reveals fine-grained functional differentiation within regions of interest (ROIs) in the visual cortex and voxels that simultaneously represent multiple distinct concepts. These findings offer profound insights into human visual representations by assigning detailed captions throughout the visual cortex while highlighting the potential of LLM-based methods in understanding brain representations. Please check out our webpage at https://sites.google.com/view/lavca-llm/
Applicability of scaling laws to vision encoding models
Aug 01, 2023
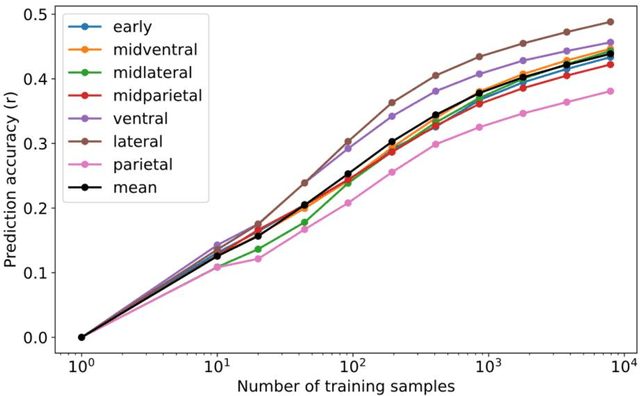


In this paper, we investigated how to build a high-performance vision encoding model to predict brain activity as part of our participation in the Algonauts Project 2023 Challenge. The challenge provided brain activity recorded by functional MRI (fMRI) while participants viewed images. Several vision models with parameter sizes ranging from 86M to 4.3B were used to build predictive models. To build highly accurate models, we focused our analysis on two main aspects: (1) How does the sample size of the fMRI training set change the prediction accuracy? (2) How does the prediction accuracy across the visual cortex vary with the parameter size of the vision models? The results show that as the sample size used during training increases, the prediction accuracy improves according to the scaling law. Similarly, we found that as the parameter size of the vision models increases, the prediction accuracy improves according to the scaling law. These results suggest that increasing the sample size of the fMRI training set and the parameter size of visual models may contribute to more accurate visual models of the brain and lead to a better understanding of visual neuroscience.
Brain2Music: Reconstructing Music from Human Brain Activity
Jul 20, 2023



The process of reconstructing experiences from human brain activity offers a unique lens into how the brain interprets and represents the world. In this paper, we introduce a method for reconstructing music from brain activity, captured using functional magnetic resonance imaging (fMRI). Our approach uses either music retrieval or the MusicLM music generation model conditioned on embeddings derived from fMRI data. The generated music resembles the musical stimuli that human subjects experienced, with respect to semantic properties like genre, instrumentation, and mood. We investigate the relationship between different components of MusicLM and brain activity through a voxel-wise encoding modeling analysis. Furthermore, we discuss which brain regions represent information derived from purely textual descriptions of music stimuli. We provide supplementary material including examples of the reconstructed music at https://google-research.github.io/seanet/brain2music
Improving visual image reconstruction from human brain activity using latent diffusion models via multiple decoded inputs
Jun 20, 2023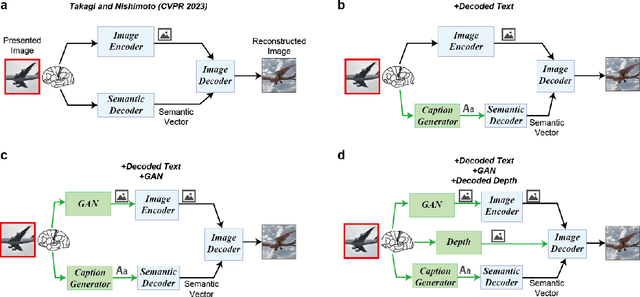

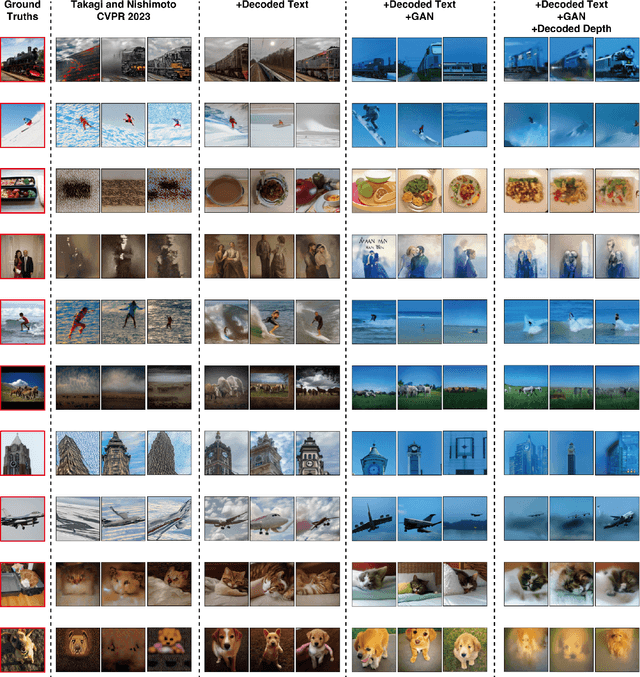
The integration of deep learning and neuroscience has been advancing rapidly, which has led to improvements in the analysis of brain activity and the understanding of deep learning models from a neuroscientific perspective. The reconstruction of visual experience from human brain activity is an area that has particularly benefited: the use of deep learning models trained on large amounts of natural images has greatly improved its quality, and approaches that combine the diverse information contained in visual experiences have proliferated rapidly in recent years. In this technical paper, by taking advantage of the simple and generic framework that we proposed (Takagi and Nishimoto, CVPR 2023), we examine the extent to which various additional decoding techniques affect the performance of visual experience reconstruction. Specifically, we combined our earlier work with the following three techniques: using decoded text from brain activity, nonlinear optimization for structural image reconstruction, and using decoded depth information from brain activity. We confirmed that these techniques contributed to improving accuracy over the baseline. We also discuss what researchers should consider when performing visual reconstruction using deep generative models trained on large datasets. Please check our webpage at https://sites.google.com/view/stablediffusion-with-brain/. Code is also available at https://github.com/yu-takagi/StableDiffusionReconstruction.
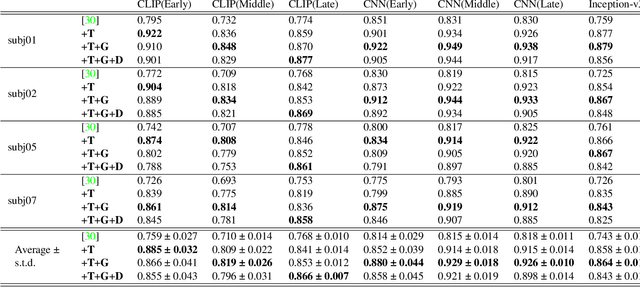
Brain-mediated Transfer Learning of Convolutional Neural Networks
May 24, 2019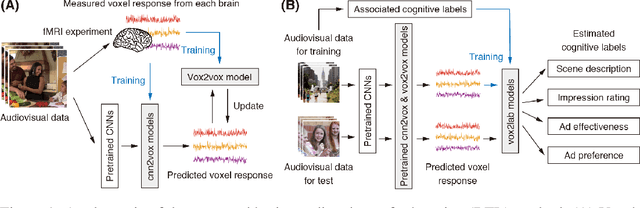

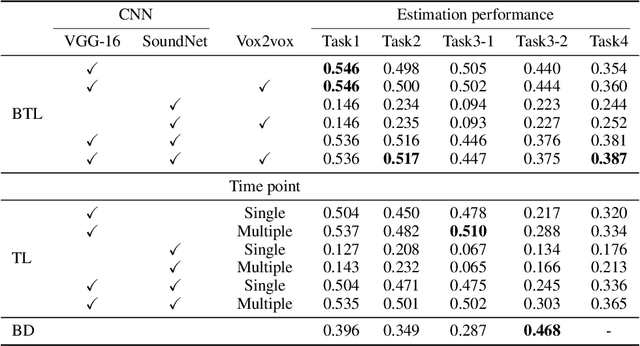
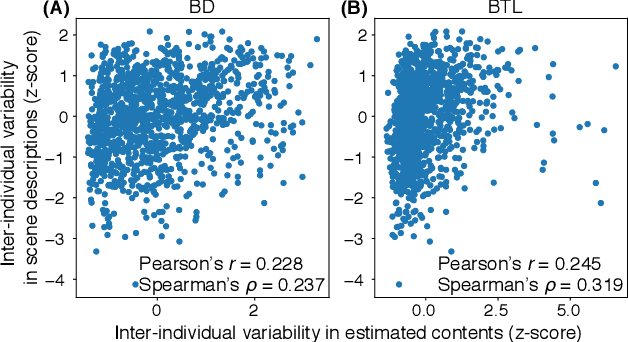
Human flexible cognition and behavior indicate that the human brain can effectively use its internal feature representations acquired through limited experiences for new experiences in different domains. This function is analogous to transfer learning (TL) in the field of machine learning. TL uses a well-trained feature space in a specific task domain to improve performance in new tasks with insufficient training data. TL with rich feature representations, such as features of convolutional neural networks (CNNs), shows high generalization ability across different task domains. However, such TL is still insufficient in making machine learning attain generalization ability comparable to that of the human brain. To address this, we introduce a method for TL mediated by human brains to improve the performance of TL especially on pattern recognition in which human high-level cognition is considered. Our method transforms feature representations of audiovisual inputs in CNNs into those in activation patterns of individual brains via their association learned ahead using measured brain responses. Then, to estimate labels reflecting human cognition and behavior induced by the audiovisual inputs, the transformed representations are used for TL. We demonstrate that our brain-mediated TL (BTL) shows higher performance in the label estimation than the standard TL. In addition, we illustrate that the estimations mediated by different brains vary from brain to brain, and the variability reflects the individual variability in perception. Thus, our BTL provides a framework to improve the generalization ability of machine-learning feature representations and enable machine learning to estimate human-like cognition and behavior, including individual variability.
Describing Semantic Representations of Brain Activity Evoked by Visual Stimuli
Jan 19, 2018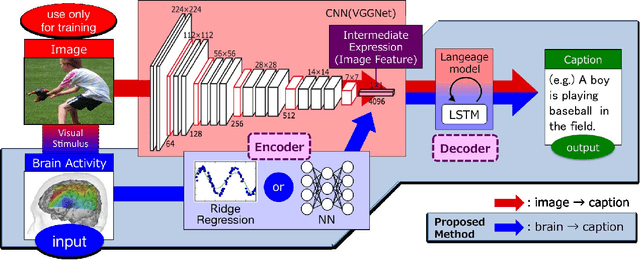
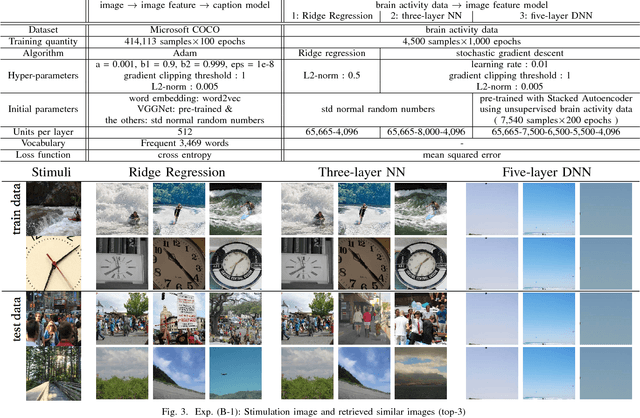


Quantitative modeling of human brain activity based on language representations has been actively studied in systems neuroscience. However, previous studies examined word-level representation, and little is known about whether we could recover structured sentences from brain activity. This study attempts to generate natural language descriptions of semantic contents from human brain activity evoked by visual stimuli. To effectively use a small amount of available brain activity data, our proposed method employs a pre-trained image-captioning network model using a deep learning framework. To apply brain activity to the image-captioning network, we train regression models that learn the relationship between brain activity and deep-layer image features. The results demonstrate that the proposed model can decode brain activity and generate descriptions using natural language sentences. We also conducted several experiments with data from different subsets of brain regions known to process visual stimuli. The results suggest that semantic information for sentence generations is widespread across the entire cortex.