 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaVCa: LLM-assisted Visual Cortex Captioning
Paper and Code
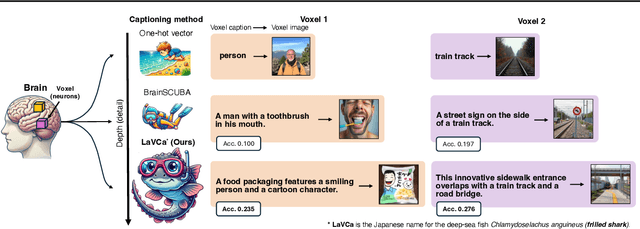

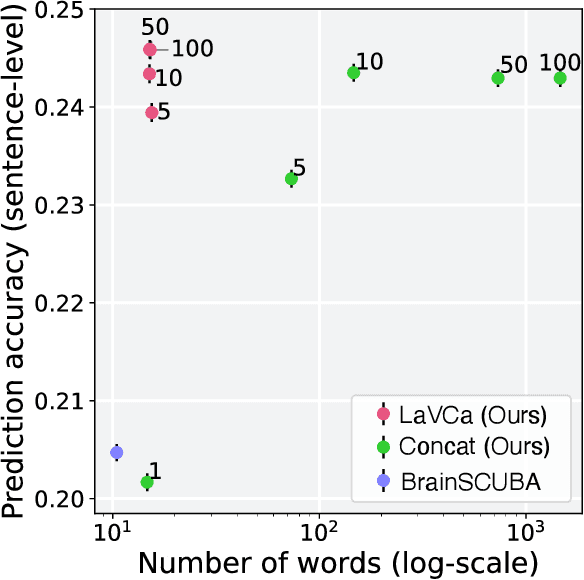

Understanding the property of neural populations (or voxels) in the human brain can advance our comprehension of human perceptual and cognitive processing capabilities and contribute to developing brain-inspired computer models. Recent encoding models using deep neural networks (DNNs) have successfully predicted voxel-wise activity. However, interpreting the properties that explain voxel responses remains challenging because of the black-box nature of DNNs. As a solution, we propose LLM-assisted Visual Cortex Captioning (LaVCa), a data-driven approach that uses large language models (LLMs) to generate natural-language captions for images to which voxels are selective. By applying LaVCa for image-evoked brain activity, we demonstrate that LaVCa generates captions that describe voxel selectivity more accurately than the previously proposed method. Furthermore, the captions generated by LaVCa quantitatively capture more detailed properties than the existing method at both the inter-voxel and intra-voxel levels. Furthermore, a more detailed analysis of the voxel-specific properties generated by LaVCa reveals fine-grained functional differentiation within regions of interest (ROIs) in the visual cortex and voxels that simultaneously represent multiple distinct concepts. These findings offer profound insights into human visual representations by assigning detailed captions throughout the visual cortex while highlighting the potential of LLM-based methods in understanding brain representations. Please check out our webpage at https://sites.google.com/view/lavca-llm/