 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaVCa: LLM-assisted Visual Cortex Captioning
Feb 19, 2025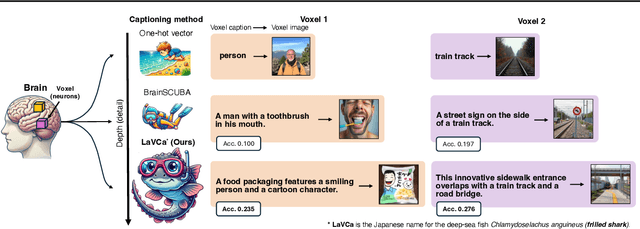

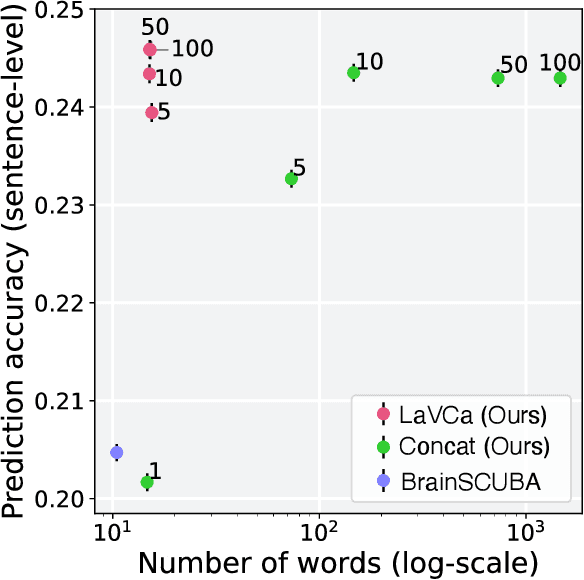

Understanding the property of neural populations (or voxels) in the human brain can advance our comprehension of human perceptual and cognitive processing capabilities and contribute to developing brain-inspired computer models. Recent encoding models using deep neural networks (DNNs) have successfully predicted voxel-wise activity. However, interpreting the properties that explain voxel responses remains challenging because of the black-box nature of DNNs. As a solution, we propose LLM-assisted Visual Cortex Captioning (LaVCa), a data-driven approach that uses large language models (LLMs) to generate natural-language captions for images to which voxels are selective. By applying LaVCa for image-evoked brain activity, we demonstrate that LaVCa generates captions that describe voxel selectivity more accurately than the previously proposed method. Furthermore, the captions generated by LaVCa quantitatively capture more detailed properties than the existing method at both the inter-voxel and intra-voxel levels. Furthermore, a more detailed analysis of the voxel-specific properties generated by LaVCa reveals fine-grained functional differentiation within regions of interest (ROIs) in the visual cortex and voxels that simultaneously represent multiple distinct concepts. These findings offer profound insights into human visual representations by assigning detailed captions throughout the visual cortex while highlighting the potential of LLM-based methods in understanding brain representations. Please check out our webpage at https://sites.google.com/view/lavca-llm/
Applicability of scaling laws to vision encoding models
Aug 01, 2023
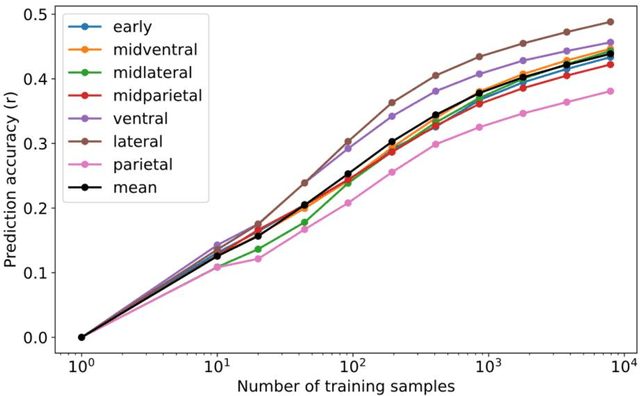


In this paper, we investigated how to build a high-performance vision encoding model to predict brain activity as part of our participation in the Algonauts Project 2023 Challenge. The challenge provided brain activity recorded by functional MRI (fMRI) while participants viewed images. Several vision models with parameter sizes ranging from 86M to 4.3B were used to build predictive models. To build highly accurate models, we focused our analysis on two main aspects: (1) How does the sample size of the fMRI training set change the prediction accuracy? (2) How does the prediction accuracy across the visual cortex vary with the parameter size of the vision models? The results show that as the sample size used during training increases, the prediction accuracy improves according to the scaling law. Similarly, we found that as the parameter size of the vision models increases, the prediction accuracy improves according to the scaling law. These results suggest that increasing the sample size of the fMRI training set and the parameter size of visual models may contribute to more accurate visual models of the brain and lead to a better understanding of visual neuroscience.
Brain2Music: Reconstructing Music from Human Brain Activity
Jul 20, 2023



The process of reconstructing experiences from human brain activity offers a unique lens into how the brain interprets and represents the world. In this paper, we introduce a method for reconstructing music from brain activity, captured using functional magnetic resonance imaging (fMRI). Our approach uses either music retrieval or the MusicLM music generation model conditioned on embeddings derived from fMRI data. The generated music resembles the musical stimuli that human subjects experienced, with respect to semantic properties like genre, instrumentation, and mood. We investigate the relationship between different components of MusicLM and brain activity through a voxel-wise encoding modeling analysis. Furthermore, we discuss which brain regions represent information derived from purely textual descriptions of music stimuli. We provide supplementary material including examples of the reconstructed music at https://google-research.github.io/seanet/brain2music