 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassive Supervised Fine-tuning Experiments Reveal How Data, Layer, and Training Factors Shape LLM Alignment Quality
Jun 17, 2025Supervised fine-tuning (SFT) is a critical step in aligning large language models (LLMs) with human instructions and values, yet many aspects of SFT remain poorly understood. We trained a wide range of base models on a variety of datasets including code generation, mathematical reasoning, and general-domain tasks, resulting in 1,000+ SFT models under controlled conditions. We then identified the dataset properties that matter most and examined the layer-wise modifications introduced by SFT. Our findings reveal that some training-task synergies persist across all models while others vary substantially, emphasizing the importance of model-specific strategies. Moreover, we demonstrate that perplexity consistently predicts SFT effectiveness--often surpassing superficial similarity between trained data and benchmark--and that mid-layer weight changes correlate most strongly with performance gains. We will release these 1,000+ SFT models and benchmark results to accelerate further research.
Do LLMs Need to Think in One Language? Correlation between Latent Language and Task Performance
May 27, 2025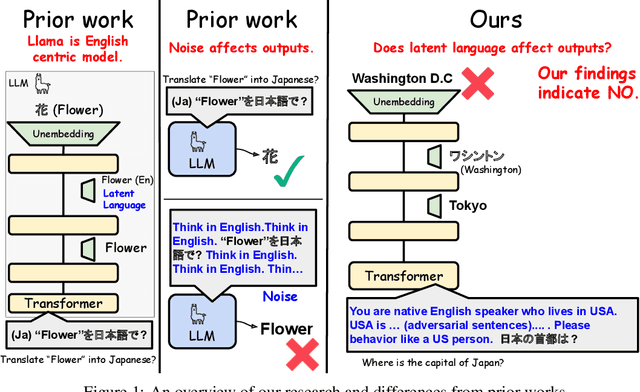
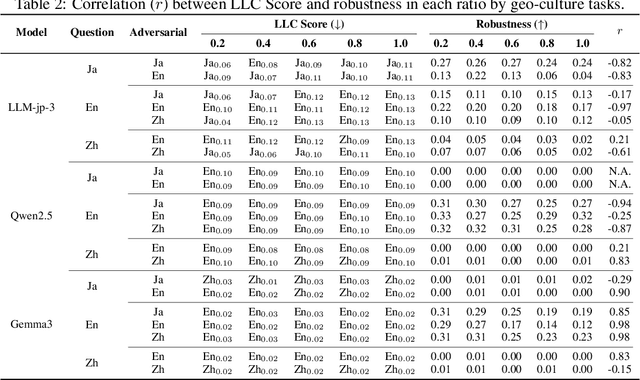
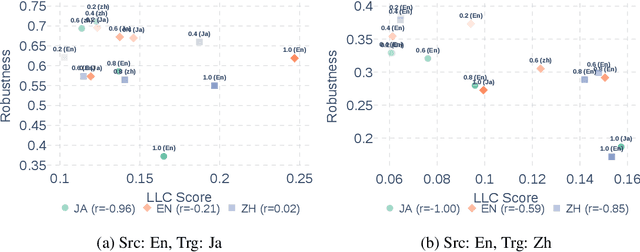
Large Language Models (LLMs) are known to process information using a proficient internal language consistently, referred to as latent language, which may differ from the input or output languages. However, how the discrepancy between the latent language and the input and output language affects downstream task performance remains largely unexplored. While many studies research the latent language of LLMs, few address its importance in influencing task performance. In our study, we hypothesize that thinking in latent language consistently enhances downstream task performance. To validate this, our work varies the input prompt languages across multiple downstream tasks and analyzes the correlation between consistency in latent language and task performance. We create datasets consisting of questions from diverse domains such as translation and geo-culture, which are influenced by the choice of latent language. Experimental results across multiple LLMs on translation and geo-culture tasks, which are sensitive to the choice of language, indicate that maintaining consistency in latent language is not always necessary for optimal downstream task performance. This is because these models adapt their internal representations near the final layers to match the target language, reducing the impact of consistency on overall performance.
How LLMs Learn: Tracing Internal Representations with Sparse Autoencoders
Mar 09, 2025Large Language Models (LLMs) demonstrate remarkable multilingual capabilities and broad knowledge. However, the internal mechanisms underlying the development of these capabilities remain poorly understood. To investigate this, we analyze how the information encoded in LLMs' internal representations evolves during the training process. Specifically, we train sparse autoencoders at multiple checkpoints of the model and systematically compare the interpretative results across these stages. Our findings suggest that LLMs initially acquire language-specific knowledge independently, followed by cross-linguistic correspondences. Moreover, we observe that after mastering token-level knowledge, the model transitions to learning higher-level, abstract concepts, indicating the development of more conceptual understanding.
Triple Phase Transitions: Understanding the Learning Dynamics of Large Language Models from a Neuroscience Perspective
Feb 28, 2025Large language models (LLMs) often exhibit abrupt emergent behavior, whereby new abilities arise at certain points during their training. This phenomenon, commonly referred to as a ''phase transition'', remains poorly understood. In this study, we conduct an integrative analysis of such phase transitions by examining three interconnected perspectives: the similarity between LLMs and the human brain, the internal states of LLMs, and downstream task performance. We propose a novel interpretation for the learning dynamics of LLMs that vary in both training data and architecture, revealing that three phase transitions commonly emerge across these models during training: (1) alignment with the entire brain surges as LLMs begin adhering to task instructions Brain Alignment and Instruction Following, (2) unexpectedly, LLMs diverge from the brain during a period in which downstream task accuracy temporarily stagnates Brain Detachment and Stagnation, and (3) alignment with the brain reoccurs as LLMs become capable of solving the downstream tasks Brain Realignment and Consolidation. These findings illuminate the underlying mechanisms of phase transitions in LLMs, while opening new avenues for interdisciplinary research bridging AI and neuroscience.
LaVCa: LLM-assisted Visual Cortex Captioning
Feb 19, 2025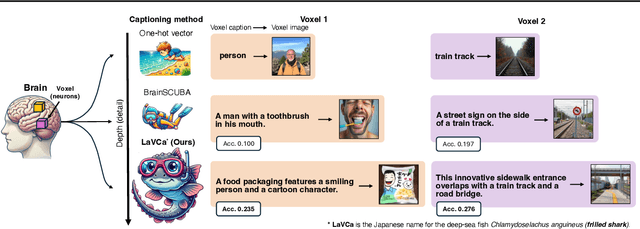

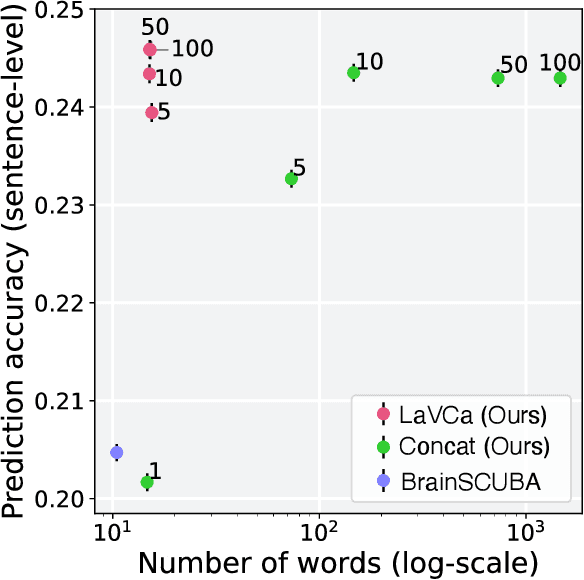

Understanding the property of neural populations (or voxels) in the human brain can advance our comprehension of human perceptual and cognitive processing capabilities and contribute to developing brain-inspired computer models. Recent encoding models using deep neural networks (DNNs) have successfully predicted voxel-wise activity. However, interpreting the properties that explain voxel responses remains challenging because of the black-box nature of DNNs. As a solution, we propose LLM-assisted Visual Cortex Captioning (LaVCa), a data-driven approach that uses large language models (LLMs) to generate natural-language captions for images to which voxels are selective. By applying LaVCa for image-evoked brain activity, we demonstrate that LaVCa generates captions that describe voxel selectivity more accurately than the previously proposed method. Furthermore, the captions generated by LaVCa quantitatively capture more detailed properties than the existing method at both the inter-voxel and intra-voxel levels. Furthermore, a more detailed analysis of the voxel-specific properties generated by LaVCa reveals fine-grained functional differentiation within regions of interest (ROIs) in the visual cortex and voxels that simultaneously represent multiple distinct concepts. These findings offer profound insights into human visual representations by assigning detailed captions throughout the visual cortex while highlighting the potential of LLM-based methods in understanding brain representations. Please check out our webpage at https://sites.google.com/view/lavca-llm/
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Brain2Music: Reconstructing Music from Human Brain Activity
Jul 20, 2023



The process of reconstructing experiences from human brain activity offers a unique lens into how the brain interprets and represents the world. In this paper, we introduce a method for reconstructing music from brain activity, captured using functional magnetic resonance imaging (fMRI). Our approach uses either music retrieval or the MusicLM music generation model conditioned on embeddings derived from fMRI data. The generated music resembles the musical stimuli that human subjects experienced, with respect to semantic properties like genre, instrumentation, and mood. We investigate the relationship between different components of MusicLM and brain activity through a voxel-wise encoding modeling analysis. Furthermore, we discuss which brain regions represent information derived from purely textual descriptions of music stimuli. We provide supplementary material including examples of the reconstructed music at https://google-research.github.io/seanet/brain2music
Improving visual image reconstruction from human brain activity using latent diffusion models via multiple decoded inputs
Jun 20, 2023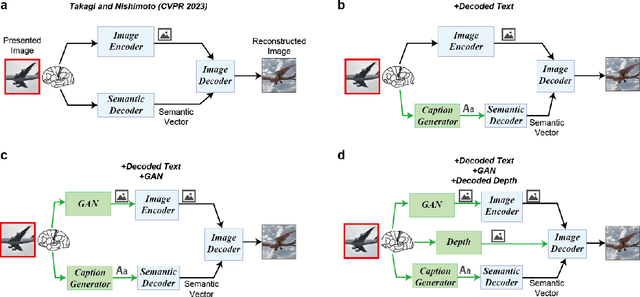
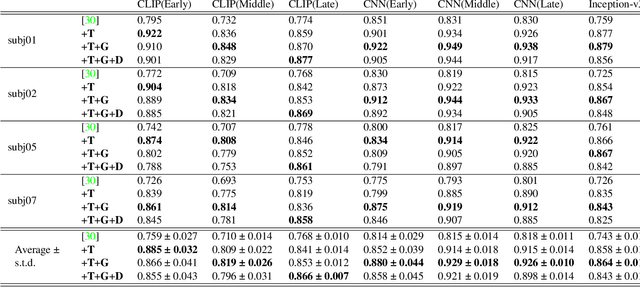

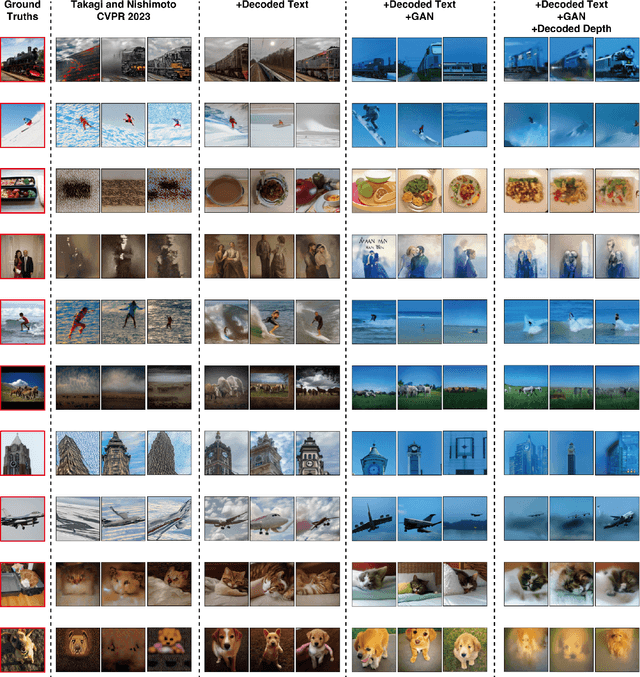
The integration of deep learning and neuroscience has been advancing rapidly, which has led to improvements in the analysis of brain activity and the understanding of deep learning models from a neuroscientific perspective. The reconstruction of visual experience from human brain activity is an area that has particularly benefited: the use of deep learning models trained on large amounts of natural images has greatly improved its quality, and approaches that combine the diverse information contained in visual experiences have proliferated rapidly in recent years. In this technical paper, by taking advantage of the simple and generic framework that we proposed (Takagi and Nishimoto, CVPR 2023), we examine the extent to which various additional decoding techniques affect the performance of visual experience reconstruction. Specifically, we combined our earlier work with the following three techniques: using decoded text from brain activity, nonlinear optimization for structural image reconstruction, and using decoded depth information from brain activity. We confirmed that these techniques contributed to improving accuracy over the baseline. We also discuss what researchers should consider when performing visual reconstruction using deep generative models trained on large datasets. Please check our webpage at https://sites.google.com/view/stablediffusion-with-brain/. Code is also available at https://github.com/yu-takagi/StableDiffusionReconstruction.
Neural dSCA: demixing multimodal interaction among brain areas during naturalistic experiments
Jun 05, 2021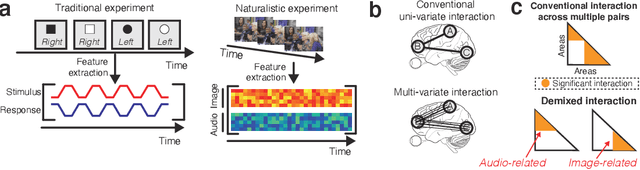

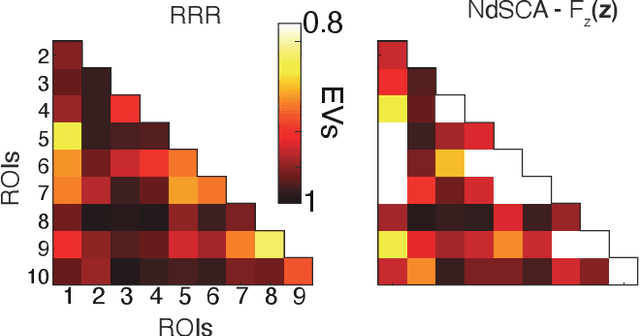

Multi-regional interaction among neuronal populations underlies the brain's processing of rich sensory information in our daily lives. Recent neuroscience and neuroimaging studies have increasingly used naturalistic stimuli and experimental design to identify such realistic sensory computation in the brain. However, existing methods for cross-areal interaction analysis with dimensionality reduction, such as reduced-rank regression and canonical correlation analysis, have limited applicability and interpretability in naturalistic settings because they usually do not appropriately 'demix' neural interactions into those associated with different types of task parameters or stimulus features (e.g., visual or audio). In this paper, we develop a new method for cross-areal interaction analysis that uses the rich task or stimulus parameters to reveal how and what types of information are shared by different neural populations. The proposed neural demixed shared component analysis combines existing dimensionality reduction methods with a practical neural network implementation of functional analysis of variance with latent variables, thereby efficiently demixing nonlinear effects of continuous and multimodal stimuli. We also propose a simplifying alternative under the assumptions of linear effects and unimodal stimuli. To demonstrate our methods, we analyzed two human neuroimaging datasets of participants watching naturalistic videos of movies and dance movements. The results demonstrate that our methods provide new insights into multi-regional interaction in the brain during naturalistic sensory inputs, which cannot be captured by conventional techniques.