 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHacking Neural Evaluation Metrics with Single Hub Text
Dec 18, 2025



Strongly human-correlated evaluation metrics serve as an essential compass for the development and improvement of generation models and must be highly reliable and robust. Recent embedding-based neural text evaluation metrics, such as COMET for translation tasks, are widely used in both research and development fields. However, there is no guarantee that they yield reliable evaluation results due to the black-box nature of neural networks. To raise concerns about the reliability and safety of such metrics, we propose a method for finding a single adversarial text in the discrete space that is consistently evaluated as high-quality, regardless of the test cases, to identify the vulnerabilities in evaluation metrics. The single hub text found with our method achieved 79.1 COMET% and 67.8 COMET% in the WMT'24 English-to-Japanese (En--Ja) and English-to-German (En--De) translation tasks, respectively, outperforming translations generated individually for each source sentence by using M2M100, a general translation model. Furthermore, we also confirmed that the hub text found with our method generalizes across multiple language pairs such as Ja--En and De--En.
Case-Based Decision-Theoretic Decoding with Quality Memories
Sep 16, 2025Minimum Bayes risk (MBR) decoding is a decision rule of text generation, which selects the hypothesis that maximizes the expected utility and robustly generates higher-quality texts than maximum a posteriori (MAP) decoding. However, it depends on sample texts drawn from the text generation model; thus, it is difficult to find a hypothesis that correctly captures the knowledge or information of out-of-domain. To tackle this issue, we propose case-based decision-theoretic (CBDT) decoding, another method to estimate the expected utility using examples of domain data. CBDT decoding not only generates higher-quality texts than MAP decoding, but also the combination of MBR and CBDT decoding outperformed MBR decoding in seven domain De--En and Ja$\leftrightarrow$En translation tasks and image captioning tasks on MSCOCO and nocaps datasets.
Long-Tail Crisis in Nearest Neighbor Language Models
Mar 28, 2025



The $k$-nearest-neighbor language model ($k$NN-LM), one of the retrieval-augmented language models, improves the perplexity for given text by directly accessing a large datastore built from any text data during inference. A widely held hypothesis for the success of $k$NN-LM is that its explicit memory, i.e., the datastore, enhances predictions for long-tail phenomena. However, prior works have primarily shown its ability to retrieve long-tail contexts, leaving the model's performance remain underexplored in estimating the probabilities of long-tail target tokens during inference. In this paper, we investigate the behavior of $k$NN-LM on low-frequency tokens, examining prediction probability, retrieval accuracy, token distribution in the datastore, and approximation error of the product quantization. Our experimental results reveal that $k$NN-LM does not improve prediction performance for low-frequency tokens but mainly benefits high-frequency tokens regardless of long-tail contexts in the datastore.
SoftMatcha: A Soft and Fast Pattern Matcher for Billion-Scale Corpus Searches
Mar 05, 2025Researchers and practitioners in natural language processing and computational linguistics frequently observe and analyze the real language usage in large-scale corpora. For that purpose, they often employ off-the-shelf pattern-matching tools, such as grep, and keyword-in-context concordancers, which is widely used in corpus linguistics for gathering examples. Nonetheless, these existing techniques rely on surface-level string matching, and thus they suffer from the major limitation of not being able to handle orthographic variations and paraphrasing -- notable and common phenomena in any natural language. In addition, existing continuous approaches such as dense vector search tend to be overly coarse, often retrieving texts that are unrelated but share similar topics. Given these challenges, we propose a novel algorithm that achieves \emph{soft} (or semantic) yet efficient pattern matching by relaxing a surface-level matching with word embeddings. Our algorithm is highly scalable with respect to the size of the corpus text utilizing inverted indexes. We have prepared an efficient implementation, and we provide an accessible web tool. Our experiments demonstrate that the proposed method (i) can execute searches on billion-scale corpora in less than a second, which is comparable in speed to surface-level string matching and dense vector search; (ii) can extract harmful instances that semantically match queries from a large set of English and Japanese Wikipedia articles; and (iii) can be effectively applied to corpus-linguistic analyses of Latin, a language with highly diverse inflections.
Theoretical Aspects of Bias and Diversity in Minimum Bayes Risk Decoding
Oct 19, 2024



Text generation commonly relies on greedy and beam decoding that limit the search space and degrade output quality. Minimum Bayes Risk (MBR) decoding can mitigate this problem by utilizing automatic evaluation metrics and model-generated pseudo-references. Previous studies have conducted empirical analyses to reveal the improvement by MBR decoding, and reported various observations. However, despite these observations, the theoretical relationship between them remains uncertain. To address this, we present a novel theoretical interpretation of MBR decoding from the perspective of bias-diversity decomposition. We decompose errors in the estimated quality of generated hypotheses in MBR decoding into two key factors: bias, which reflects the closeness between utility functions and human evaluations, and diversity, which represents the variation in the estimated quality of utility functions. Our theoretical analysis reveals the difficulty in simultaneously improving both bias and diversity, and highlights the effectiveness of increasing diversity to enhance MBR decoding performance. This analysis verifies the alignment between our theoretical insights and the empirical results reported in previous work. Furthermore, to support our theoretical findings, we propose a new metric, pseudo-bias, which approximates the bias term using gold references. We also introduce a new MBR approach, Metric-augmented MBR (MAMBR), which increases diversity by adjusting the behavior of utility functions without altering the pseudo-references. Experimental results across multiple NLP tasks show that the decomposed terms in the bias-diversity decomposition correlate well with performance, and that MAMBR improves text generation quality by modifying utility function behavior. Our code will be available at https://github.com/naist-nlp/mbr-bias-diversity.
mbrs: A Library for Minimum Bayes Risk Decoding
Aug 08, 2024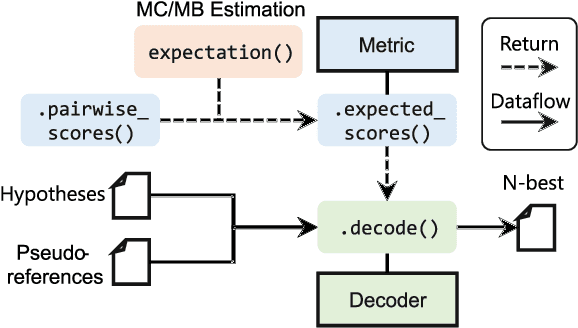
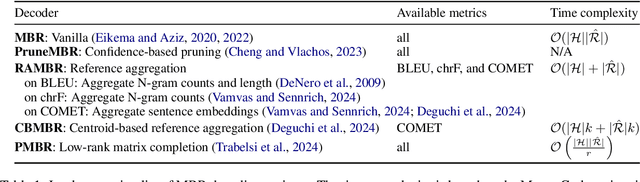
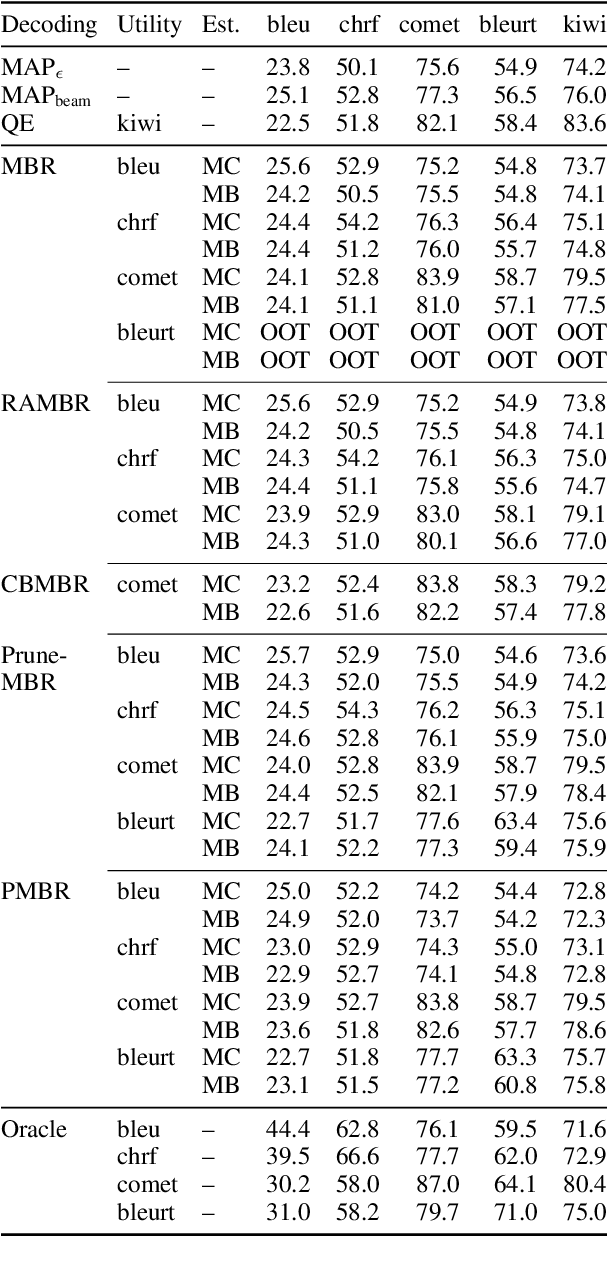

Minimum Bayes risk (MBR) decoding is a decision rule of text generation tasks that outperforms conventional maximum a posterior (MAP) decoding using beam search by selecting high-quality outputs based on a utility function rather than those with high-probability. Typically, it finds the most suitable hypothesis from the set of hypotheses under the sampled pseudo-references. mbrs is a library of MBR decoding, which can flexibly combine various metrics, alternative expectation estimations, and algorithmic variants. It is designed with a focus on speed measurement and calling count of code blocks, transparency, reproducibility, and extensibility, which are essential for researchers and developers. We published our mbrs as an MIT-licensed open-source project, and the code is available on GitHub. GitHub: https://github.com/naist-nlp/mbrs
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
E2GS: Event Enhanced Gaussian Splatting
Jun 21, 2024



Event cameras, known for their high dynamic range, absence of motion blur, and low energy usage, have recently found a wide range of applications thanks to these attributes. In the past few years, the field of event-based 3D reconstruction saw remarkable progress, with the Neural Radiance Field (NeRF) based approach demonstrating photorealistic view synthesis results. However, the volume rendering paradigm of NeRF necessitates extensive training and rendering times. In this paper, we introduce Event Enhanced Gaussian Splatting (E2GS), a novel method that incorporates event data into Gaussian Splatting, which has recently made significant advances in the field of novel view synthesis. Our E2GS effectively utilizes both blurry images and event data, significantly improving image deblurring and producing high-quality novel view synthesis. Our comprehensive experiments on both synthetic and real-world datasets demonstrate our E2GS can generate visually appealing renderings while offering faster training and rendering speed (140 FPS). Our code is available at https://github.com/deguchihiroyuki/E2GS.
Centroid-Based Efficient Minimum Bayes Risk Decoding
Feb 17, 2024Minimum Bayes risk (MBR) decoding achieved state-of-the-art translation performance by using COMET, a neural metric that has a high correlation with human evaluation. However, MBR decoding requires quadratic time since it computes the expected score between a translation hypothesis and all reference translations. We propose centroid-based MBR (CBMBR) decoding to improve the speed of MBR decoding. Our method clusters the reference translations in the feature space, and then calculates the score using the centroids of each cluster. The experimental results show that our CBMBR not only improved the decoding speed of the expected score calculation 6.9 times, but also outperformed vanilla MBR decoding in translation quality by up to 0.5 COMET in the WMT'22 En$\leftrightarrow$Ja, En$\leftrightarrow$De, En$\leftrightarrow$Zh, and WMT'23 En$\leftrightarrow$Ja translation tasks.
knn-seq: Efficient, Extensible kNN-MT Framework
Oct 18, 2023



k-nearest-neighbor machine translation (kNN-MT) boosts the translation quality of a pre-trained neural machine translation (NMT) model by utilizing translation examples during decoding. Translation examples are stored in a vector database, called a datastore, which contains one entry for each target token from the parallel data it is made from. Due to its size, it is computationally expensive both to construct and to retrieve examples from the datastore. In this paper, we present an efficient and extensible kNN-MT framework, knn-seq, for researchers and developers that is carefully designed to run efficiently, even with a billion-scale large datastore. knn-seq is developed as a plug-in on fairseq and easy to switch models and kNN indexes. Experimental results show that our implemented kNN-MT achieves a comparable gain to the original kNN-MT, and the billion-scale datastore construction took 2.21 hours in the WMT'19 German-to-English translation task. We publish our knn-seq as an MIT-licensed open-source project and the code is available on https://github.com/naist-nlp/knn-seq . The demo video is available on https://youtu.be/zTDzEOq80m0 .