 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Speech Recognition for Documenting Endangered Languages: Case Study of Ikema Miyakoan
Mar 27, 2026Language endangerment poses a major challenge to linguistic diversity worldwide, and technological advances have opened new avenues for documentation and revitalization. Among these, automatic speech recognition (ASR) has shown increasing potential to assist in the transcription of endangered language data. This study focuses on Ikema, a severely endangered Ryukyuan language spoken in Okinawa, Japan, with approximately 1,300 remaining speakers, most of whom are over 60 years old. We present an ongoing effort to develop an ASR system for Ikema based on field recordings. Specifically, we (1) construct a {\totaldatasethours}-hour speech corpus from field recordings, (2) train an ASR model that achieves a character error rate as low as 15\%, and (3) evaluate the impact of ASR assistance on the efficiency of speech transcription. Our results demonstrate that ASR integration can substantially reduce transcription time and cognitive load, offering a practical pathway toward scalable, technology-supported documentation of endangered languages.
Efficient Context Selection for Long-Context QA: No Tuning, No Iteration, Just Adaptive-$k$
Jun 10, 2025Retrieval-augmented generation (RAG) and long-context language models (LCLMs) both address context limitations of LLMs in open-domain question answering (QA). However, optimal external context to retrieve remains an open problem: fixing the retrieval size risks either wasting tokens or omitting key evidence. Existing adaptive methods like Self-RAG and Self-Route rely on iterative LLM prompting and perform well on factoid QA, but struggle with aggregation QA, where the optimal context size is both unknown and variable. We present Adaptive-$k$ retrieval, a simple and effective single-pass method that adaptively selects the number of passages based on the distribution of the similarity scores between the query and the candidate passages. It does not require model fine-tuning, extra LLM inferences or changes to existing retriever-reader pipelines. On both factoid and aggregation QA benchmarks, Adaptive-$k$ matches or outperforms fixed-$k$ baselines while using up to 10x fewer tokens than full-context input, yet still retrieves 70% of relevant passages. It improves accuracy across five LCLMs and two embedding models, highlighting that dynamically adjusting context size leads to more efficient and accurate QA.
SoftMatcha: A Soft and Fast Pattern Matcher for Billion-Scale Corpus Searches
Mar 05, 2025Researchers and practitioners in natural language processing and computational linguistics frequently observe and analyze the real language usage in large-scale corpora. For that purpose, they often employ off-the-shelf pattern-matching tools, such as grep, and keyword-in-context concordancers, which is widely used in corpus linguistics for gathering examples. Nonetheless, these existing techniques rely on surface-level string matching, and thus they suffer from the major limitation of not being able to handle orthographic variations and paraphrasing -- notable and common phenomena in any natural language. In addition, existing continuous approaches such as dense vector search tend to be overly coarse, often retrieving texts that are unrelated but share similar topics. Given these challenges, we propose a novel algorithm that achieves \emph{soft} (or semantic) yet efficient pattern matching by relaxing a surface-level matching with word embeddings. Our algorithm is highly scalable with respect to the size of the corpus text utilizing inverted indexes. We have prepared an efficient implementation, and we provide an accessible web tool. Our experiments demonstrate that the proposed method (i) can execute searches on billion-scale corpora in less than a second, which is comparable in speed to surface-level string matching and dense vector search; (ii) can extract harmful instances that semantically match queries from a large set of English and Japanese Wikipedia articles; and (iii) can be effectively applied to corpus-linguistic analyses of Latin, a language with highly diverse inflections.
Language Complexity and Speech Recognition Accuracy: Orthographic Complexity Hurts, Phonological Complexity Doesn't
Jun 13, 2024



We investigate what linguistic factors affect the performance of Automatic Speech Recognition (ASR) models. We hypothesize that orthographic and phonological complexities both degrade accuracy. To examine this, we fine-tune the multilingual self-supervised pretrained model Wav2Vec2-XLSR-53 on 25 languages with 15 writing systems, and we compare their ASR accuracy, number of graphemes, unigram grapheme entropy, logographicity (how much word/morpheme-level information is encoded in the writing system), and number of phonemes. The results demonstrate that orthographic complexities significantly correlate with low ASR accuracy, while phonological complexity shows no significant correlation.
Killkan: The Automatic Speech Recognition Dataset for Kichwa with Morphosyntactic Information
Apr 23, 2024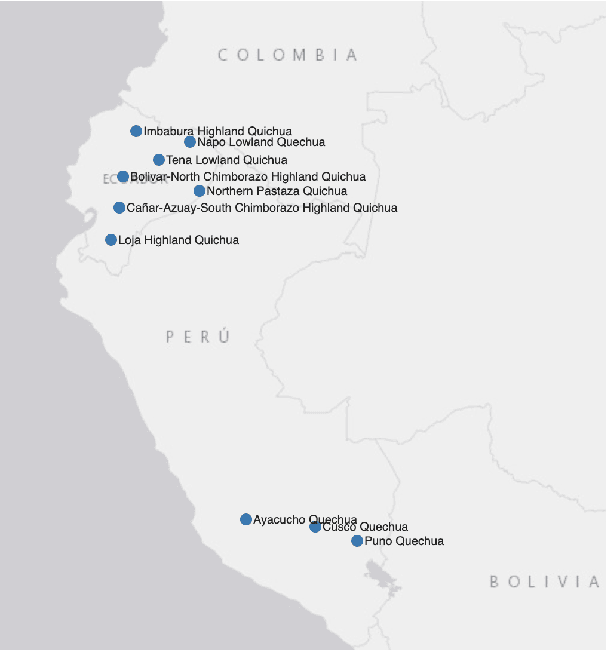
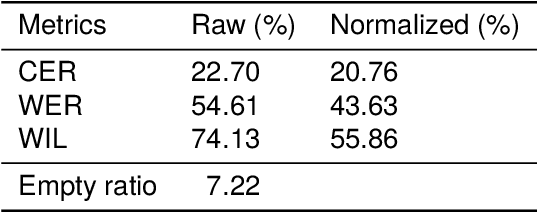
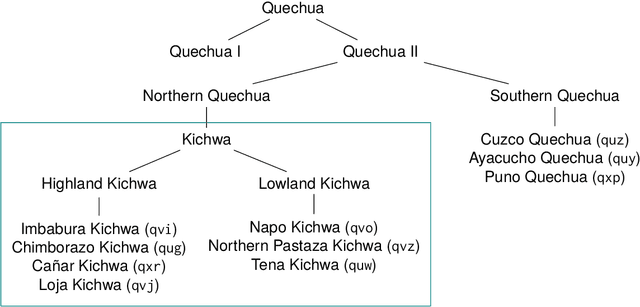
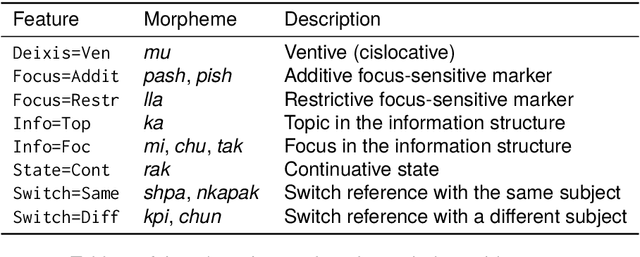
This paper presents Killkan, the first dataset for automatic speech recognition (ASR) in the Kichwa language, an indigenous language of Ecuador. Kichwa is an extremely low-resource endangered language, and there have been no resources before Killkan for Kichwa to be incorporated in applications of natural language processing. The dataset contains approximately 4 hours of audio with transcription, translation into Spanish, and morphosyntactic annotation in the format of Universal Dependencies. The audio data was retrieved from a publicly available radio program in Kichwa. This paper also provides corpus-linguistic analyses of the dataset with a special focus on the agglutinative morphology of Kichwa and frequent code-switching with Spanish. The experiments show that the dataset makes it possible to develop the first ASR system for Kichwa with reliable quality despite its small dataset size. This dataset, the ASR model, and the code used to develop them will be publicly available. Thus, our study positively showcases resource building and its applications for low-resource languages and their community.
Universal Automatic Phonetic Transcription into the International Phonetic Alphabet
Aug 07, 2023



This paper presents a state-of-the-art model for transcribing speech in any language into the International Phonetic Alphabet (IPA). Transcription of spoken languages into IPA is an essential yet time-consuming process in language documentation, and even partially automating this process has the potential to drastically speed up the documentation of endangered languages. Like the previous best speech-to-IPA model (Wav2Vec2Phoneme), our model is based on wav2vec 2.0 and is fine-tuned to predict IPA from audio input. We use training data from seven languages from CommonVoice 11.0, transcribed into IPA semi-automatically. Although this training dataset is much smaller than Wav2Vec2Phoneme's, its higher quality lets our model achieve comparable or better results. Furthermore, we show that the quality of our universal speech-to-IPA models is close to that of human annotators.