 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExCAM: Explainable Cultural Awareness Metrics
May 28, 2026Evaluating the cultural awareness of large language models is crucial to ensure the fairness of generated text and the generalizability of applications across the world. Recent benchmarks explore cultural goods like food or values like behavior in stressful situations through the lens of question answering or text generation tasks. However, creating these benchmarks requires time-intensive and costly human annotations. Also, benchmarks that evaluate cultural awareness in free text are scarce and often rely on dated evaluation mechanisms. To address this gap, we introduce ExCAM, an Explainable Cultural Awareness Metric, which is, to our knowledge, the first dedicated evaluation metric that identifies, rates and explains cultural errors in instruction-output pairs. To train and evaluate ExCAM, we introduce ExCAM40k, a dataset comprised of nine existing benchmarks that we reformat and enhance with synthetic errors. Compared to several baselines, including GPT-5, ExCAM achieves the highest error detection rate with up to 80% accuracy on a balanced test set. Therefore, ExCAM opens the pathway towards fine-grained and explainable cultural evaluation of free text.
Minimum Bayes Risk Decoding for Error Span Detection in Reference-Free Automatic Machine Translation Evaluation
Dec 19, 2025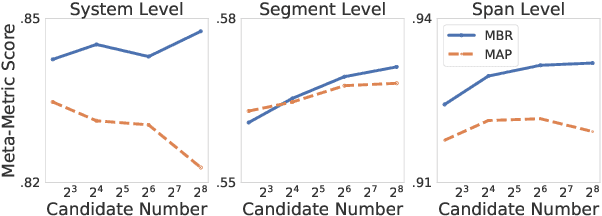

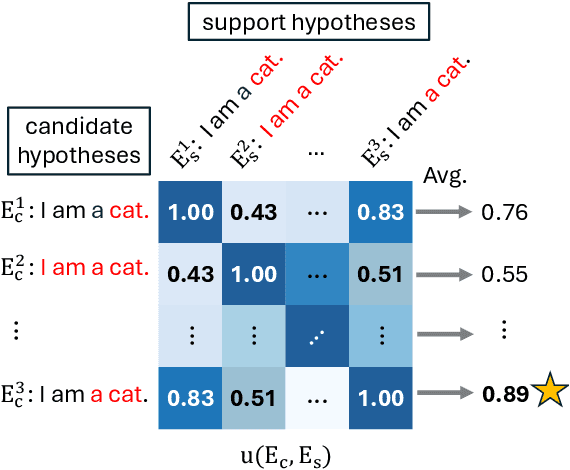
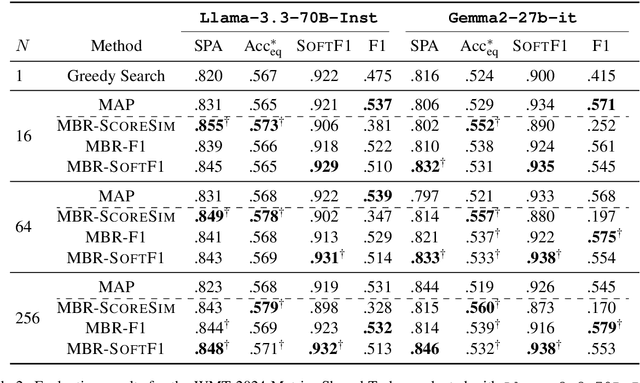
Error Span Detection (ESD) extends automatic machine translation (MT) evaluation by localizing translation errors and labeling their severity. Current generative ESD methods typically use Maximum a Posteriori (MAP) decoding, assuming that the model-estimated probabilities are perfectly correlated with similarity to the human annotation, but we often observe higher likelihood assigned to an incorrect annotation than to the human one. We instead apply Minimum Bayes Risk (MBR) decoding to generative ESD. We use a sentence- or span-level similarity function for MBR decoding, which selects candidate hypotheses based on their approximate similarity to the human annotation. Experimental results on the WMT24 Metrics Shared Task show that MBR decoding significantly improves span-level performance and generally matches or outperforms MAP at the system and sentence levels. To reduce the computational cost of MBR decoding, we further distill its decisions into a model decoded via greedy search, removing the inference-time latency bottleneck.
PrahokBART: A Pre-trained Sequence-to-Sequence Model for Khmer Natural Language Generation
Dec 15, 2025This work introduces {\it PrahokBART}, a compact pre-trained sequence-to-sequence model trained from scratch for Khmer using carefully curated Khmer and English corpora. We focus on improving the pre-training corpus quality and addressing the linguistic issues of Khmer, which are ignored in existing multilingual models, by incorporating linguistic components such as word segmentation and normalization. We evaluate PrahokBART on three generative tasks: machine translation, text summarization, and headline generation, where our results demonstrate that it outperforms mBART50, a strong multilingual pre-trained model. Additionally, our analysis provides insights into the impact of each linguistic module and evaluates how effectively our model handles space during text generation, which is crucial for the naturalness of texts in Khmer.
TikZero: Zero-Shot Text-Guided Graphics Program Synthesis
Mar 14, 2025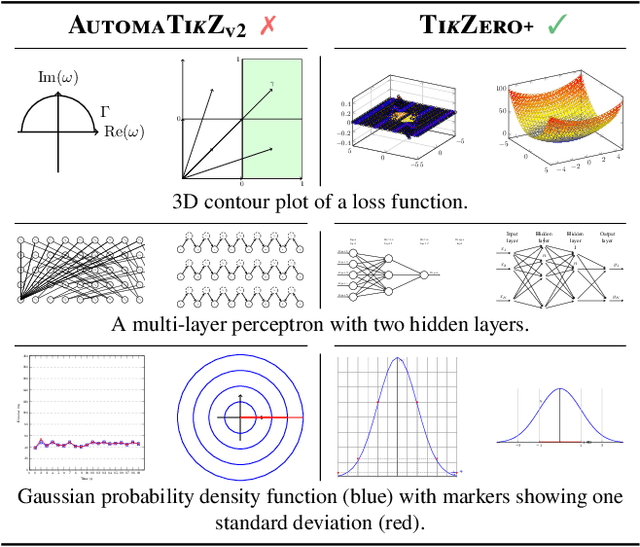
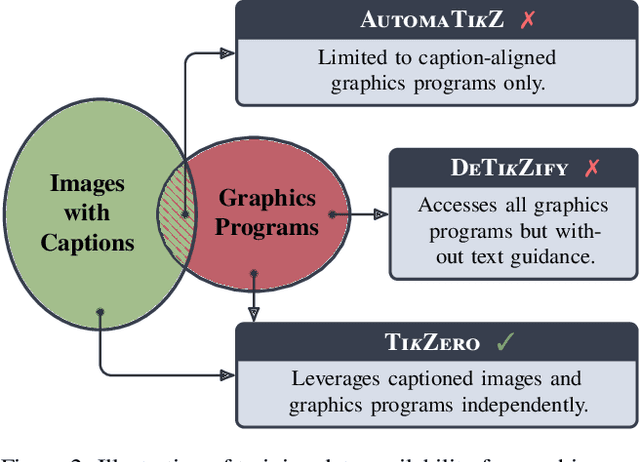

With the rise of generative AI, synthesizing figures from text captions becomes a compelling application. However, achieving high geometric precision and editability requires representing figures as graphics programs in languages like TikZ, and aligned training data (i.e., graphics programs with captions) remains scarce. Meanwhile, large amounts of unaligned graphics programs and captioned raster images are more readily available. We reconcile these disparate data sources by presenting TikZero, which decouples graphics program generation from text understanding by using image representations as an intermediary bridge. It enables independent training on graphics programs and captioned images and allows for zero-shot text-guided graphics program synthesis during inference. We show that our method substantially outperforms baselines that can only operate with caption-aligned graphics programs. Furthermore, when leveraging caption-aligned graphics programs as a complementary training signal, TikZero matches or exceeds the performance of much larger models, including commercial systems like GPT-4o. Our code, datasets, and select models are publicly available.
IteRABRe: Iterative Recovery-Aided Block Reduction
Mar 08, 2025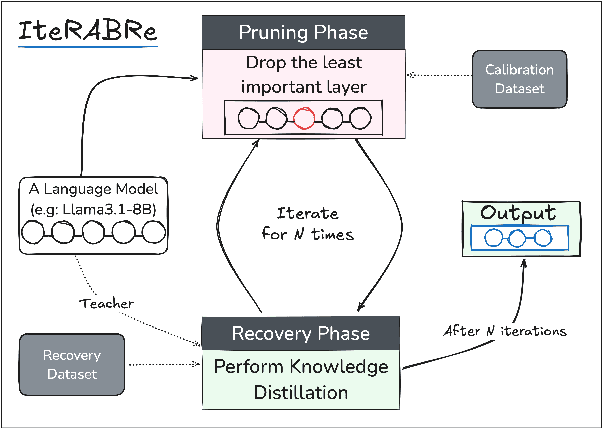
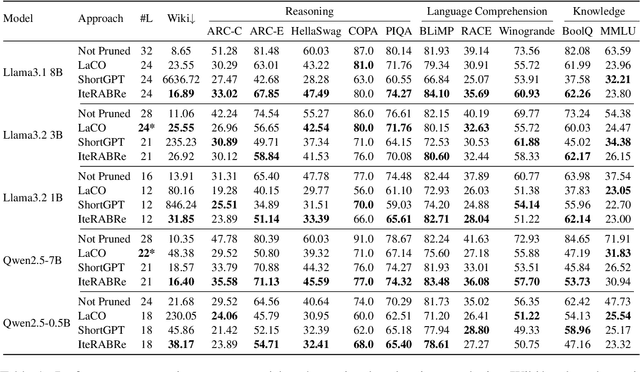
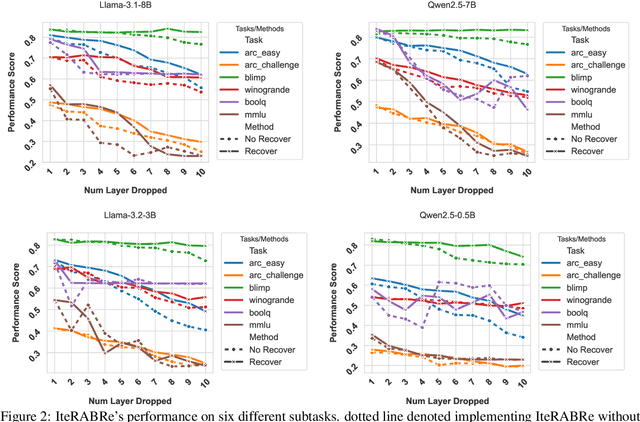
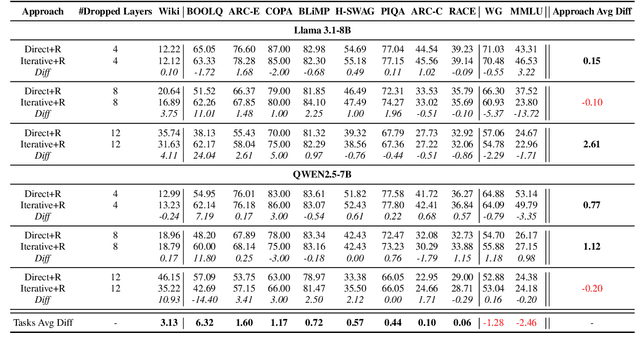
Large Language Models (LLMs) have grown increasingly expensive to deploy, driving the need for effective model compression techniques. While block pruning offers a straightforward approach to reducing model size, existing methods often struggle to maintain performance or require substantial computational resources for recovery. We present IteRABRe, a simple yet effective iterative pruning method that achieves superior compression results while requiring minimal computational resources. Using only 2.5M tokens for recovery, our method outperforms baseline approaches by ~3% on average when compressing the Llama3.1-8B and Qwen2.5-7B models. IteRABRe demonstrates particular strength in the preservation of linguistic capabilities, showing an improvement 5% over the baselines in language-related tasks. Our analysis reveals distinct pruning characteristics between these models, while also demonstrating preservation of multilingual capabilities.
Registering Source Tokens to Target Language Spaces in Multilingual Neural Machine Translation
Jan 06, 2025



The multilingual neural machine translation (MNMT) enables arbitrary translations across multiple languages by training a model with limited parameters using parallel data only. However, the performance of such MNMT models still lags behind that of large language models (LLMs), limiting their practicality. In this work, we address this limitation by introducing registering to achieve the new state-of-the-art of decoder-only MNMT models. Specifically, we insert a set of artificial tokens specifying the target language, called registers, into the input sequence between the source and target tokens. By modifying the attention mask, the target token generation only pays attention to the activation of registers, representing the source tokens in the target language space. Experiments on EC-40, a large-scale benchmark, show that our method outperforms related methods driven by optimizing multilingual representations. We further scale up and collect 9.3 billion sentence pairs across 24 languages from public datasets to pre-train two models, namely MITRE (multilingual translation with registers). One of them, MITRE-913M, outperforms NLLB-3.3B, achieves comparable performance with commercial LLMs, and shows strong adaptability in fine-tuning. Finally, we open-source our models to facilitate further research and development in MNMT: https://github.com/zhiqu22/mitre.
Improving Language Transfer Capability of Decoder-only Architecture in Multilingual Neural Machine Translation
Dec 03, 2024



Existing multilingual neural machine translation (MNMT) approaches mainly focus on improving models with the encoder-decoder architecture to translate multiple languages. However, decoder-only architecture has been explored less in MNMT due to its underperformance when trained on parallel data solely. In this work, we attribute the issue of the decoder-only architecture to its lack of language transfer capability. Specifically, the decoder-only architecture is insufficient in encoding source tokens with the target language features. We propose dividing the decoding process into two stages so that target tokens are explicitly excluded in the first stage to implicitly boost the transfer capability across languages. Additionally, we impose contrastive learning on translation instructions, resulting in improved performance in zero-shot translation. We conduct experiments on TED-19 and OPUS-100 datasets, considering both training from scratch and fine-tuning scenarios. Experimental results show that, compared to the encoder-decoder architecture, our methods not only perform competitively in supervised translations but also achieve improvements of up to 3.39 BLEU, 6.99 chrF++, 3.22 BERTScore, and 4.81 COMET in zero-shot translations.
Centroid-Based Efficient Minimum Bayes Risk Decoding
Feb 17, 2024Minimum Bayes risk (MBR) decoding achieved state-of-the-art translation performance by using COMET, a neural metric that has a high correlation with human evaluation. However, MBR decoding requires quadratic time since it computes the expected score between a translation hypothesis and all reference translations. We propose centroid-based MBR (CBMBR) decoding to improve the speed of MBR decoding. Our method clusters the reference translations in the feature space, and then calculates the score using the centroids of each cluster. The experimental results show that our CBMBR not only improved the decoding speed of the expected score calculation 6.9 times, but also outperformed vanilla MBR decoding in translation quality by up to 0.5 COMET in the WMT'22 En$\leftrightarrow$Ja, En$\leftrightarrow$De, En$\leftrightarrow$Zh, and WMT'23 En$\leftrightarrow$Ja translation tasks.
SciCap+: A Knowledge Augmented Dataset to Study the Challenges of Scientific Figure Captioning
Jun 06, 2023



In scholarly documents, figures provide a straightforward way of communicating scientific findings to readers. Automating figure caption generation helps move model understandings of scientific documents beyond text and will help authors write informative captions that facilitate communicating scientific findings. Unlike previous studies, we reframe scientific figure captioning as a knowledge-augmented image captioning task that models need to utilize knowledge embedded across modalities for caption generation. To this end, we extended the large-scale SciCap dataset~\cite{hsu-etal-2021-scicap-generating} to SciCap+ which includes mention-paragraphs (paragraphs mentioning figures) and OCR tokens. Then, we conduct experiments with the M4C-Captioner (a multimodal transformer-based model with a pointer network) as a baseline for our study. Our results indicate that mention-paragraphs serves as additional context knowledge, which significantly boosts the automatic standard image caption evaluation scores compared to the figure-only baselines. Human evaluations further reveal the challenges of generating figure captions that are informative to readers. The code and SciCap+ dataset will be publicly available at https://github.com/ZhishenYang/scientific_figure_captioning_dataset