 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimum Bayes Risk Decoding for Error Span Detection in Reference-Free Automatic Machine Translation Evaluation
Dec 19, 2025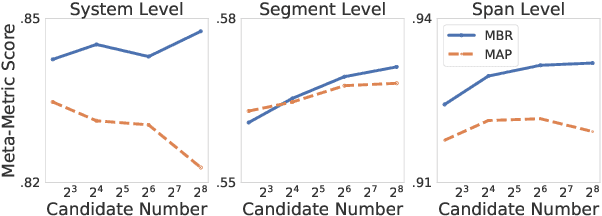

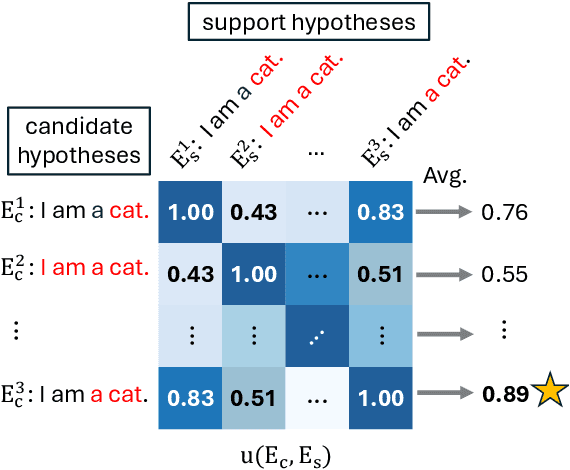
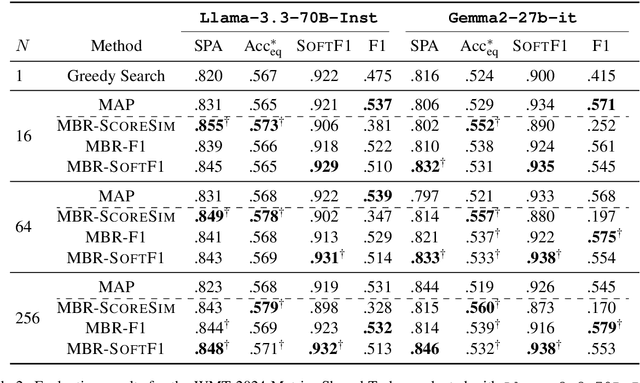
Error Span Detection (ESD) extends automatic machine translation (MT) evaluation by localizing translation errors and labeling their severity. Current generative ESD methods typically use Maximum a Posteriori (MAP) decoding, assuming that the model-estimated probabilities are perfectly correlated with similarity to the human annotation, but we often observe higher likelihood assigned to an incorrect annotation than to the human one. We instead apply Minimum Bayes Risk (MBR) decoding to generative ESD. We use a sentence- or span-level similarity function for MBR decoding, which selects candidate hypotheses based on their approximate similarity to the human annotation. Experimental results on the WMT24 Metrics Shared Task show that MBR decoding significantly improves span-level performance and generally matches or outperforms MAP at the system and sentence levels. To reduce the computational cost of MBR decoding, we further distill its decisions into a model decoded via greedy search, removing the inference-time latency bottleneck.
PrahokBART: A Pre-trained Sequence-to-Sequence Model for Khmer Natural Language Generation
Dec 15, 2025This work introduces {\it PrahokBART}, a compact pre-trained sequence-to-sequence model trained from scratch for Khmer using carefully curated Khmer and English corpora. We focus on improving the pre-training corpus quality and addressing the linguistic issues of Khmer, which are ignored in existing multilingual models, by incorporating linguistic components such as word segmentation and normalization. We evaluate PrahokBART on three generative tasks: machine translation, text summarization, and headline generation, where our results demonstrate that it outperforms mBART50, a strong multilingual pre-trained model. Additionally, our analysis provides insights into the impact of each linguistic module and evaluates how effectively our model handles space during text generation, which is crucial for the naturalness of texts in Khmer.
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025



Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
IteRABRe: Iterative Recovery-Aided Block Reduction
Mar 08, 2025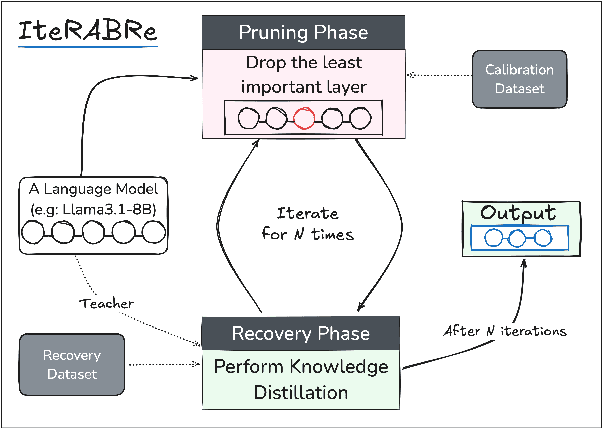
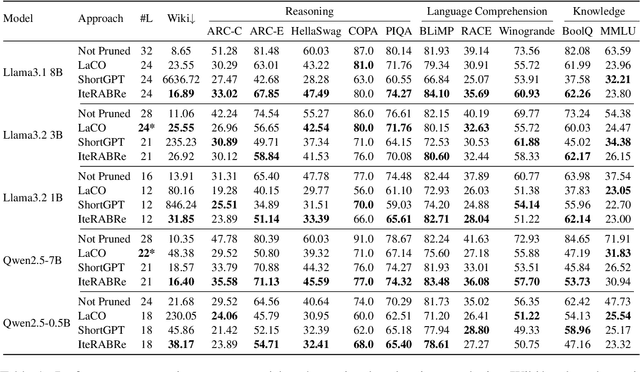
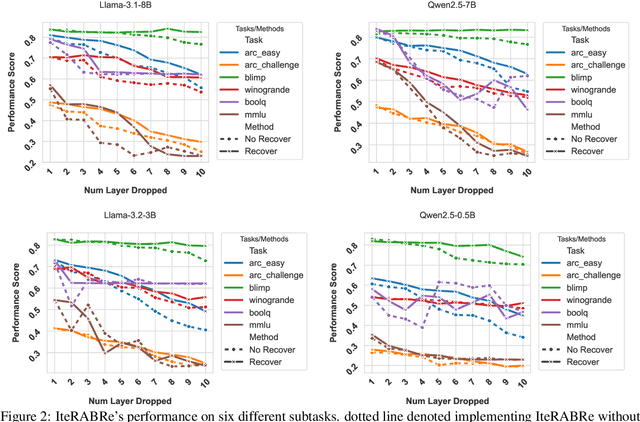
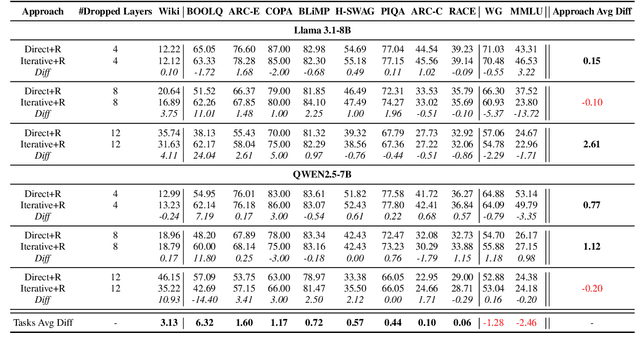
Large Language Models (LLMs) have grown increasingly expensive to deploy, driving the need for effective model compression techniques. While block pruning offers a straightforward approach to reducing model size, existing methods often struggle to maintain performance or require substantial computational resources for recovery. We present IteRABRe, a simple yet effective iterative pruning method that achieves superior compression results while requiring minimal computational resources. Using only 2.5M tokens for recovery, our method outperforms baseline approaches by ~3% on average when compressing the Llama3.1-8B and Qwen2.5-7B models. IteRABRe demonstrates particular strength in the preservation of linguistic capabilities, showing an improvement 5% over the baselines in language-related tasks. Our analysis reveals distinct pruning characteristics between these models, while also demonstrating preservation of multilingual capabilities.
Pralekha: An Indic Document Alignment Evaluation Benchmark
Nov 28, 2024



Mining parallel document pairs poses a significant challenge because existing sentence embedding models often have limited context windows, preventing them from effectively capturing document-level information. Another overlooked issue is the lack of concrete evaluation benchmarks comprising high-quality parallel document pairs for assessing document-level mining approaches, particularly for Indic languages. In this study, we introduce Pralekha, a large-scale benchmark for document-level alignment evaluation. Pralekha includes over 2 million documents, with a 1:2 ratio of unaligned to aligned pairs, covering 11 Indic languages and English. Using Pralekha, we evaluate various document-level mining approaches across three dimensions: the embedding models, the granularity levels, and the alignment algorithm. To address the challenge of aligning documents using sentence and chunk-level alignments, we propose a novel scoring method, Document Alignment Coefficient (DAC). DAC demonstrates substantial improvements over baseline pooling approaches, particularly in noisy scenarios, achieving average gains of 20-30% in precision and 15-20% in F1 score. These results highlight DAC's effectiveness in parallel document mining for Indic languages.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
Enhancing Personality Recognition in Dialogue by Data Augmentation and Heterogeneous Conversational Graph Networks
Jan 11, 2024



Personality recognition is useful for enhancing robots' ability to tailor user-adaptive responses, thus fostering rich human-robot interactions. One of the challenges in this task is a limited number of speakers in existing dialogue corpora, which hampers the development of robust, speaker-independent personality recognition models. Additionally, accurately modeling both the interdependencies among interlocutors and the intra-dependencies within the speaker in dialogues remains a significant issue. To address the first challenge, we introduce personality trait interpolation for speaker data augmentation. For the second, we propose heterogeneous conversational graph networks to independently capture both contextual influences and inherent personality traits. Evaluations on the RealPersonaChat corpus demonstrate our method's significant improvements over existing baselines.
Bilingual Corpus Mining and Multistage Fine-Tuning for Improving Machine Translation of Lecture Transcripts
Nov 07, 2023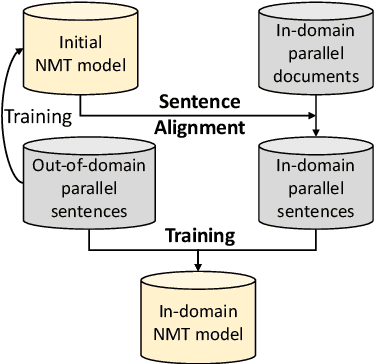
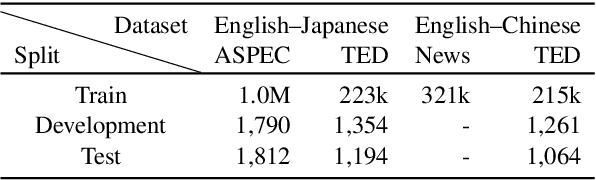
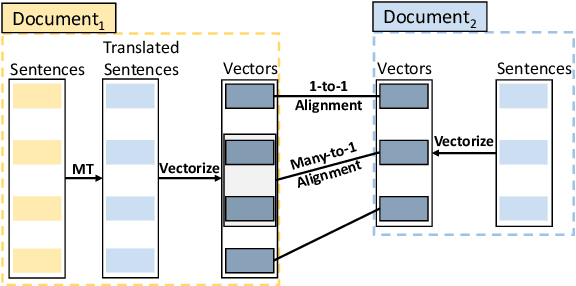
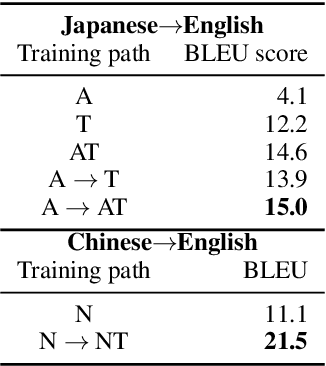
Lecture transcript translation helps learners understand online courses, however, building a high-quality lecture machine translation system lacks publicly available parallel corpora. To address this, we examine a framework for parallel corpus mining, which provides a quick and effective way to mine a parallel corpus from publicly available lectures on Coursera. To create the parallel corpora, we propose a dynamic programming based sentence alignment algorithm which leverages the cosine similarity of machine-translated sentences. The sentence alignment F1 score reaches 96%, which is higher than using the BERTScore, LASER, or sentBERT methods. For both English--Japanese and English--Chinese lecture translations, we extracted parallel corpora of approximately 50,000 lines and created development and test sets through manual filtering for benchmarking translation performance. Through machine translation experiments, we show that the mined corpora enhance the quality of lecture transcript translation when used in conjunction with out-of-domain parallel corpora via multistage fine-tuning. Furthermore, this study also suggests guidelines for gathering and cleaning corpora, mining parallel sentences, cleaning noise in the mined data, and creating high-quality evaluation splits. For the sake of reproducibility, we have released the corpora as well as the code to create them. The dataset is available at https://github.com/shyyhs/CourseraParallelCorpusMining.
SelfSeg: A Self-supervised Sub-word Segmentation Method for Neural Machine Translation
Jul 31, 2023
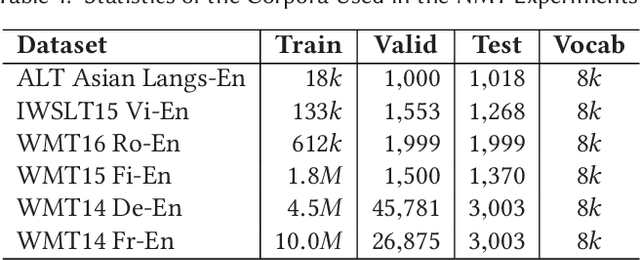
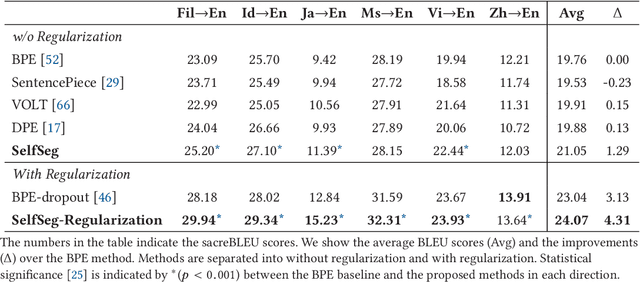
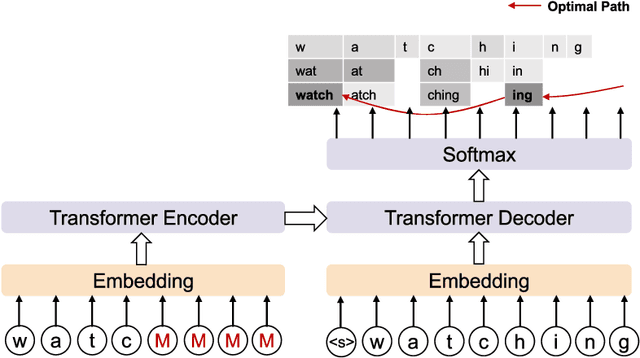
Sub-word segmentation is an essential pre-processing step for Neural Machine Translation (NMT). Existing work has shown that neural sub-word segmenters are better than Byte-Pair Encoding (BPE), however, they are inefficient as they require parallel corpora, days to train and hours to decode. This paper introduces SelfSeg, a self-supervised neural sub-word segmentation method that is much faster to train/decode and requires only monolingual dictionaries instead of parallel corpora. SelfSeg takes as input a word in the form of a partially masked character sequence, optimizes the word generation probability and generates the segmentation with the maximum posterior probability, which is calculated using a dynamic programming algorithm. The training time of SelfSeg depends on word frequencies, and we explore several word frequency normalization strategies to accelerate the training phase. Additionally, we propose a regularization mechanism that allows the segmenter to generate various segmentations for one word. To show the effectiveness of our approach, we conduct MT experiments in low-, middle- and high-resource scenarios, where we compare the performance of using different segmentation methods. The experimental results demonstrate that on the low-resource ALT dataset, our method achieves more than 1.2 BLEU score improvement compared with BPE and SentencePiece, and a 1.1 score improvement over Dynamic Programming Encoding (DPE) and Vocabulary Learning via Optimal Transport (VOLT) on average. The regularization method achieves approximately a 4.3 BLEU score improvement over BPE and a 1.2 BLEU score improvement over BPE-dropout, the regularized version of BPE. We also observed significant improvements on IWSLT15 Vi->En, WMT16 Ro->En and WMT15 Fi->En datasets, and competitive results on the WMT14 De->En and WMT14 Fr->En datasets.
Variable-length Neural Interlingua Representations for Zero-shot Neural Machine Translation
May 17, 2023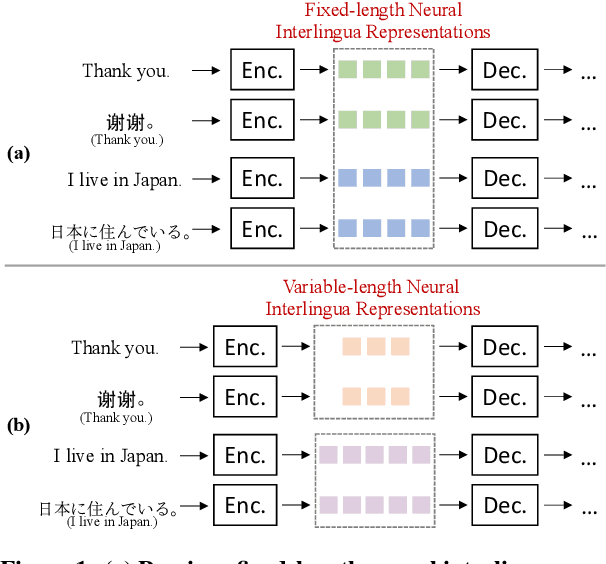
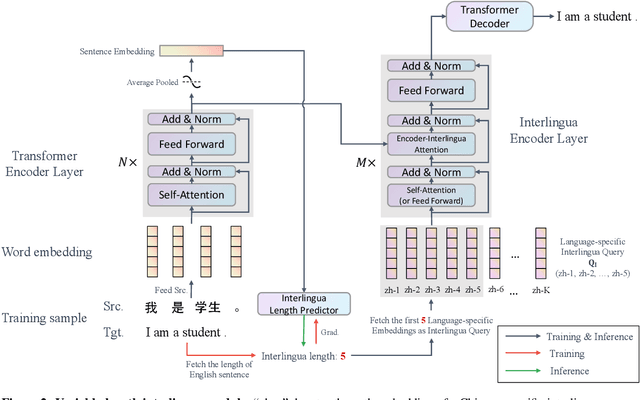
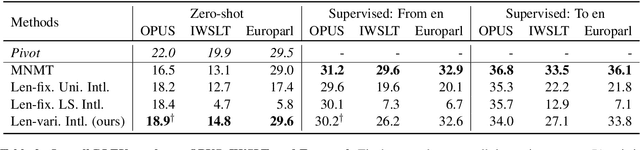
The language-independency of encoded representations within multilingual neural machine translation (MNMT) models is crucial for their generalization ability on zero-shot translation. Neural interlingua representations have been shown as an effective method for achieving this. However, fixed-length neural interlingua representations introduced in previous work can limit its flexibility and representation ability. In this study, we introduce a novel method to enhance neural interlingua representations by making their length variable, thereby overcoming the constraint of fixed-length neural interlingua representations. Our empirical results on zero-shot translation on OPUS, IWSLT, and Europarl datasets demonstrate stable model convergence and superior zero-shot translation results compared to fixed-length neural interlingua representations. However, our analysis reveals the suboptimal efficacy of our approach in translating from certain source languages, wherein we pinpoint the defective model component in our proposed method.