 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndicIFEval: A Benchmark for Verifiable Instruction-Following Evaluation in 14 Indic Languages
Feb 25, 2026Instruction-following benchmarks remain predominantly English-centric, leaving a critical evaluation gap for the hundreds of millions of Indic language speakers. We introduce IndicIFEval, a benchmark evaluating constrained generation of LLMs across 14 Indic languages using automatically verifiable, rule-based instructions. It comprises around 800 human-verified examples per language spread across two complementary subsets: IndicIFEval-Ground, translated prompts from IFEval (Zhou et al., 2023) carefully localized for Indic contexts, and IndicIFEval-Ground, synthetically generated instructions grounded in native Indic content. We conduct a comprehensive evaluation of major open-weight and proprietary models spanning both reasoning and non-reasoning models. While models maintain strong adherence to formatting constraints, they struggle significantly with lexical and cross-lingual tasks -- and despite progress in high-resource languages, instruction-following across the broader Indic family lags significantly behind English. We release IndicIFEval and its evaluation scripts to support progress on multilingual constrained generation (http://github.com/ai4bharat/IndicIFEval).
Can Vision-Language Models Evaluate Handwritten Math?
Jan 13, 2025



Recent advancements in Vision-Language Models (VLMs) have opened new possibilities in automatic grading of handwritten student responses, particularly in mathematics. However, a comprehensive study to test the ability of VLMs to evaluate and reason over handwritten content remains absent. To address this gap, we introduce FERMAT, a benchmark designed to assess the ability of VLMs to detect, localize and correct errors in handwritten mathematical content. FERMAT spans four key error dimensions - computational, conceptual, notational, and presentation - and comprises over 2,200 handwritten math solutions derived from 609 manually curated problems from grades 7-12 with intentionally introduced perturbations. Using FERMAT we benchmark nine VLMs across three tasks: error detection, localization, and correction. Our results reveal significant shortcomings in current VLMs in reasoning over handwritten text, with Gemini-1.5-Pro achieving the highest error correction rate (77%). We also observed that some models struggle with processing handwritten content, as their accuracy improves when handwritten inputs are replaced with printed text or images. These findings highlight the limitations of current VLMs and reveal new avenues for improvement. We release FERMAT and all the associated resources in the open-source to drive further research.
Pralekha: An Indic Document Alignment Evaluation Benchmark
Nov 28, 2024



Mining parallel document pairs poses a significant challenge because existing sentence embedding models often have limited context windows, preventing them from effectively capturing document-level information. Another overlooked issue is the lack of concrete evaluation benchmarks comprising high-quality parallel document pairs for assessing document-level mining approaches, particularly for Indic languages. In this study, we introduce Pralekha, a large-scale benchmark for document-level alignment evaluation. Pralekha includes over 2 million documents, with a 1:2 ratio of unaligned to aligned pairs, covering 11 Indic languages and English. Using Pralekha, we evaluate various document-level mining approaches across three dimensions: the embedding models, the granularity levels, and the alignment algorithm. To address the challenge of aligning documents using sentence and chunk-level alignments, we propose a novel scoring method, Document Alignment Coefficient (DAC). DAC demonstrates substantial improvements over baseline pooling approaches, particularly in noisy scenarios, achieving average gains of 20-30% in precision and 15-20% in F1 score. These results highlight DAC's effectiveness in parallel document mining for Indic languages.
BhasaAnuvaad: A Speech Translation Dataset for 14 Indian Languages
Nov 07, 2024



Automatic Speech Translation (AST) datasets for Indian languages remain critically scarce, with public resources covering fewer than 10 of the 22 official languages. This scarcity has resulted in AST systems for Indian languages lagging far behind those available for high-resource languages like English. In this paper, we first evaluate the performance of widely-used AST systems on Indian languages, identifying notable performance gaps and challenges. Our findings show that while these systems perform adequately on read speech, they struggle significantly with spontaneous speech, including disfluencies like pauses and hesitations. Additionally, there is a striking absence of systems capable of accurately translating colloquial and informal language, a key aspect of everyday communication. To this end, we introduce BhasaAnuvaad, the largest publicly available dataset for AST involving 14 scheduled Indian languages spanning over 44,400 hours and 17M text segments. BhasaAnuvaad contains data for English speech to Indic text, as well as Indic speech to English text. This dataset comprises three key categories: (1) Curated datasets from existing resources, (2) Large-scale web mining, and (3) Synthetic data generation. By offering this diverse and expansive dataset, we aim to bridge the resource gap and promote advancements in AST for low-resource Indian languages, especially in handling spontaneous and informal speech patterns.
MILU: A Multi-task Indic Language Understanding Benchmark
Nov 04, 2024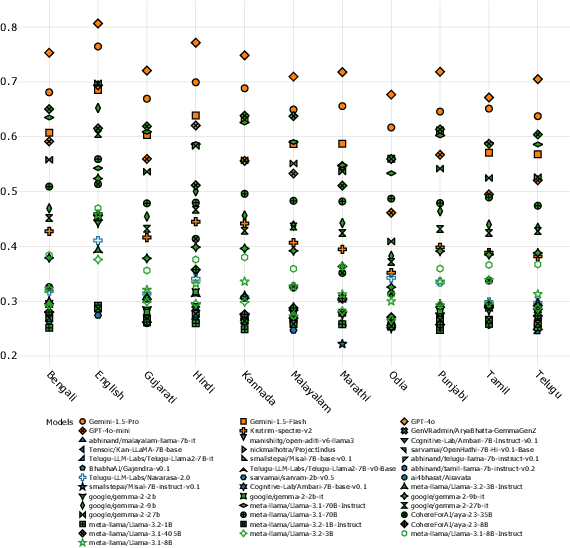

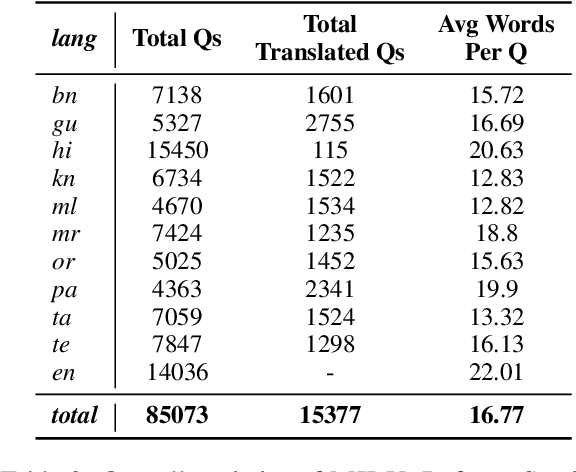
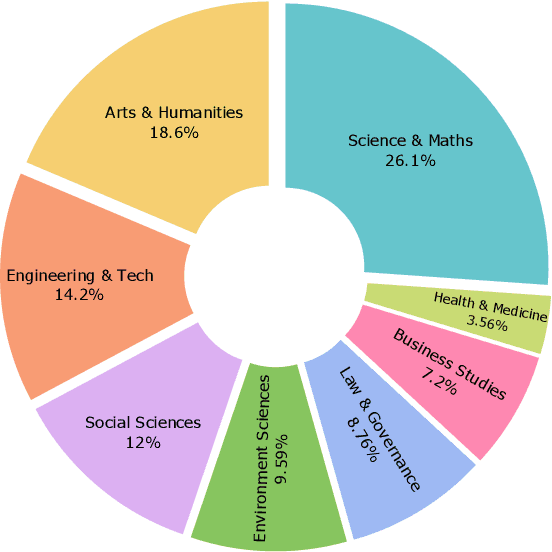
Evaluating Large Language Models (LLMs) in low-resource and linguistically diverse languages remains a significant challenge in NLP, particularly for languages using non-Latin scripts like those spoken in India. Existing benchmarks predominantly focus on English, leaving substantial gaps in assessing LLM capabilities in these languages. We introduce MILU, a Multi task Indic Language Understanding Benchmark, a comprehensive evaluation benchmark designed to address this gap. MILU spans 8 domains and 42 subjects across 11 Indic languages, reflecting both general and culturally specific knowledge. With an India-centric design, incorporates material from regional and state-level examinations, covering topics such as local history, arts, festivals, and laws, alongside standard subjects like science and mathematics. We evaluate over 42 LLMs, and find that current LLMs struggle with MILU, with GPT-4o achieving the highest average accuracy at 72 percent. Open multilingual models outperform language-specific fine-tuned models, which perform only slightly better than random baselines. Models also perform better in high resource languages as compared to low resource ones. Domain-wise analysis indicates that models perform poorly in culturally relevant areas like Arts and Humanities, Law and Governance compared to general fields like STEM. To the best of our knowledge, MILU is the first of its kind benchmark focused on Indic languages, serving as a crucial step towards comprehensive cultural evaluation. All code, benchmarks, and artifacts will be made publicly available to foster open research.
Cross-Lingual Auto Evaluation for Assessing Multilingual LLMs
Oct 17, 2024


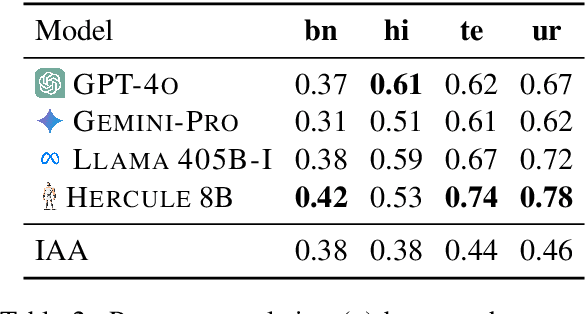
Evaluating machine-generated text remains a significant challenge in NLP, especially for non-English languages. Current methodologies, including automated metrics, human assessments, and LLM-based evaluations, predominantly focus on English, revealing a significant gap in multilingual evaluation frameworks. We introduce the Cross Lingual Auto Evaluation (CIA) Suite, an extensible framework that includes evaluator LLMs (Hercule) and a novel test set (Recon) specifically designed for multilingual evaluation. Our test set features 500 human-annotated instructions spanning various task capabilities along with human judgment scores across six languages. This would enable benchmarking of general-purpose multilingual LLMs and facilitate meta-evaluation of Evaluator LLMs. The proposed model, Hercule, is a cross-lingual evaluation model that addresses the scarcity of reference answers in the target language by learning to assign scores to responses based on easily available reference answers in English. Our experiments demonstrate that Hercule aligns more closely with human judgments compared to proprietary models, demonstrating the effectiveness of such cross-lingual evaluation in low resource scenarios. Further, it is also effective in zero-shot evaluation on unseen languages. This study is the first comprehensive examination of cross-lingual evaluation using LLMs, presenting a scalable and effective approach for multilingual assessment. All code, datasets, and models will be publicly available to enable further research in this important area.
Finding Blind Spots in Evaluator LLMs with Interpretable Checklists
Jun 19, 2024Large Language Models (LLMs) are increasingly relied upon to evaluate text outputs of other LLMs, thereby influencing leaderboards and development decisions. However, concerns persist over the accuracy of these assessments and the potential for misleading conclusions. In this work, we investigate the effectiveness of LLMs as evaluators for text generation tasks. We propose FBI, a novel framework designed to examine the proficiency of Evaluator LLMs in assessing four critical abilities in other LLMs: factual accuracy, instruction following, coherence in long-form writing, and reasoning proficiency. By introducing targeted perturbations in answers generated by LLMs, that clearly impact one of these key capabilities, we test whether an Evaluator LLM can detect these quality drops. By creating a total of 2400 perturbed answers covering 22 perturbation categories, we conduct a comprehensive study using different evaluation strategies on five prominent LLMs commonly used as evaluators in the literature. Our findings reveal significant shortcomings in current Evaluator LLMs, which failed to identify quality drops in over 50\% of cases on average. Single-answer and pairwise evaluations demonstrated notable limitations, whereas reference-based evaluations showed comparatively better performance. These results underscore the unreliable nature of current Evaluator LLMs and advocate for cautious implementation in practical applications. Code and data are available at https://github.com/AI4Bharat/FBI.
IndicLLMSuite: A Blueprint for Creating Pre-training and Fine-Tuning Datasets for Indian Languages
Mar 11, 2024Despite the considerable advancements in English LLMs, the progress in building comparable models for other languages has been hindered due to the scarcity of tailored resources. Our work aims to bridge this divide by introducing an expansive suite of resources specifically designed for the development of Indic LLMs, covering 22 languages, containing a total of 251B tokens and 74.8M instruction-response pairs. Recognizing the importance of both data quality and quantity, our approach combines highly curated manually verified data, unverified yet valuable data, and synthetic data. We build a clean, open-source pipeline for curating pre-training data from diverse sources, including websites, PDFs, and videos, incorporating best practices for crawling, cleaning, flagging, and deduplication. For instruction-fine tuning, we amalgamate existing Indic datasets, translate/transliterate English datasets into Indian languages, and utilize LLaMa2 and Mixtral models to create conversations grounded in articles from Indian Wikipedia and Wikihow. Additionally, we address toxicity alignment by generating toxic prompts for multiple scenarios and then generate non-toxic responses by feeding these toxic prompts to an aligned LLaMa2 model. We hope that the datasets, tools, and resources released as a part of this work will not only propel the research and development of Indic LLMs but also establish an open-source blueprint for extending such efforts to other languages. The data and other artifacts created as part of this work are released with permissive licenses.
Airavata: Introducing Hindi Instruction-tuned LLM
Jan 26, 2024We announce the initial release of "Airavata," an instruction-tuned LLM for Hindi. Airavata was created by fine-tuning OpenHathi with diverse, instruction-tuning Hindi datasets to make it better suited for assistive tasks. Along with the model, we also share the IndicInstruct dataset, which is a collection of diverse instruction-tuning datasets to enable further research for Indic LLMs. Additionally, we present evaluation benchmarks and a framework for assessing LLM performance across tasks in Hindi. Currently, Airavata supports Hindi, but we plan to expand this to all 22 scheduled Indic languages. You can access all artifacts at https://ai4bharat.github.io/airavata.