 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMILU: A Multi-task Indic Language Understanding Benchmark
Nov 04, 2024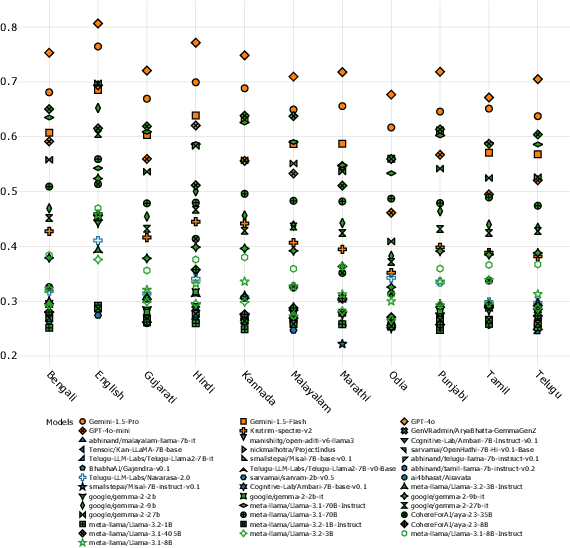

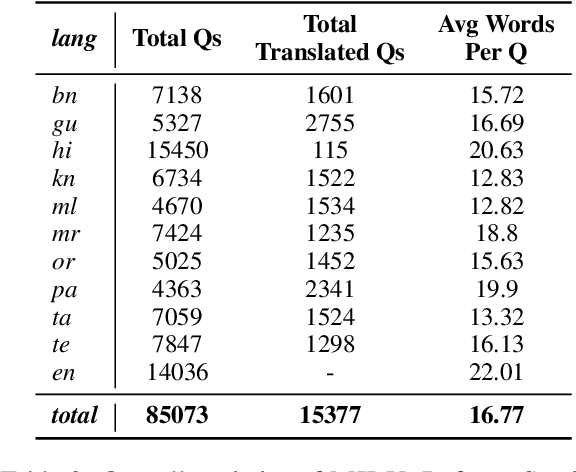
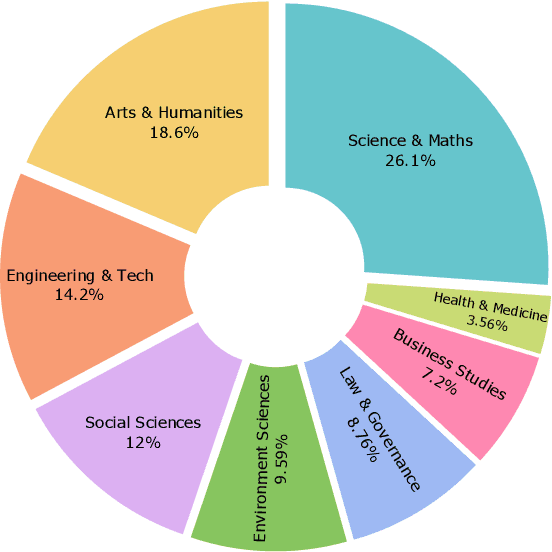
Evaluating Large Language Models (LLMs) in low-resource and linguistically diverse languages remains a significant challenge in NLP, particularly for languages using non-Latin scripts like those spoken in India. Existing benchmarks predominantly focus on English, leaving substantial gaps in assessing LLM capabilities in these languages. We introduce MILU, a Multi task Indic Language Understanding Benchmark, a comprehensive evaluation benchmark designed to address this gap. MILU spans 8 domains and 42 subjects across 11 Indic languages, reflecting both general and culturally specific knowledge. With an India-centric design, incorporates material from regional and state-level examinations, covering topics such as local history, arts, festivals, and laws, alongside standard subjects like science and mathematics. We evaluate over 42 LLMs, and find that current LLMs struggle with MILU, with GPT-4o achieving the highest average accuracy at 72 percent. Open multilingual models outperform language-specific fine-tuned models, which perform only slightly better than random baselines. Models also perform better in high resource languages as compared to low resource ones. Domain-wise analysis indicates that models perform poorly in culturally relevant areas like Arts and Humanities, Law and Governance compared to general fields like STEM. To the best of our knowledge, MILU is the first of its kind benchmark focused on Indic languages, serving as a crucial step towards comprehensive cultural evaluation. All code, benchmarks, and artifacts will be made publicly available to foster open research.
Finding Blind Spots in Evaluator LLMs with Interpretable Checklists
Jun 19, 2024Large Language Models (LLMs) are increasingly relied upon to evaluate text outputs of other LLMs, thereby influencing leaderboards and development decisions. However, concerns persist over the accuracy of these assessments and the potential for misleading conclusions. In this work, we investigate the effectiveness of LLMs as evaluators for text generation tasks. We propose FBI, a novel framework designed to examine the proficiency of Evaluator LLMs in assessing four critical abilities in other LLMs: factual accuracy, instruction following, coherence in long-form writing, and reasoning proficiency. By introducing targeted perturbations in answers generated by LLMs, that clearly impact one of these key capabilities, we test whether an Evaluator LLM can detect these quality drops. By creating a total of 2400 perturbed answers covering 22 perturbation categories, we conduct a comprehensive study using different evaluation strategies on five prominent LLMs commonly used as evaluators in the literature. Our findings reveal significant shortcomings in current Evaluator LLMs, which failed to identify quality drops in over 50\% of cases on average. Single-answer and pairwise evaluations demonstrated notable limitations, whereas reference-based evaluations showed comparatively better performance. These results underscore the unreliable nature of current Evaluator LLMs and advocate for cautious implementation in practical applications. Code and data are available at https://github.com/AI4Bharat/FBI.