 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Auto Evaluation for Assessing Multilingual LLMs
Oct 17, 2024


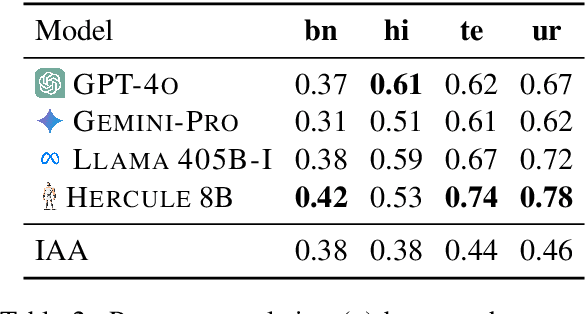
Evaluating machine-generated text remains a significant challenge in NLP, especially for non-English languages. Current methodologies, including automated metrics, human assessments, and LLM-based evaluations, predominantly focus on English, revealing a significant gap in multilingual evaluation frameworks. We introduce the Cross Lingual Auto Evaluation (CIA) Suite, an extensible framework that includes evaluator LLMs (Hercule) and a novel test set (Recon) specifically designed for multilingual evaluation. Our test set features 500 human-annotated instructions spanning various task capabilities along with human judgment scores across six languages. This would enable benchmarking of general-purpose multilingual LLMs and facilitate meta-evaluation of Evaluator LLMs. The proposed model, Hercule, is a cross-lingual evaluation model that addresses the scarcity of reference answers in the target language by learning to assign scores to responses based on easily available reference answers in English. Our experiments demonstrate that Hercule aligns more closely with human judgments compared to proprietary models, demonstrating the effectiveness of such cross-lingual evaluation in low resource scenarios. Further, it is also effective in zero-shot evaluation on unseen languages. This study is the first comprehensive examination of cross-lingual evaluation using LLMs, presenting a scalable and effective approach for multilingual assessment. All code, datasets, and models will be publicly available to enable further research in this important area.
PERSOMA: PERsonalized SOft ProMpt Adapter Architecture for Personalized Language Prompting
Aug 02, 2024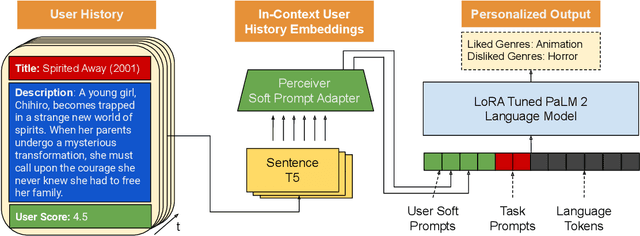



Understanding the nuances of a user's extensive interaction history is key to building accurate and personalized natural language systems that can adapt to evolving user preferences. To address this, we introduce PERSOMA, Personalized Soft Prompt Adapter architecture. Unlike previous personalized prompting methods for large language models, PERSOMA offers a novel approach to efficiently capture user history. It achieves this by resampling and compressing interactions as free form text into expressive soft prompt embeddings, building upon recent research utilizing embedding representations as input for LLMs. We rigorously validate our approach by evaluating various adapter architectures, first-stage sampling strategies, parameter-efficient tuning techniques like LoRA, and other personalization methods. Our results demonstrate PERSOMA's superior ability to handle large and complex user histories compared to existing embedding-based and text-prompt-based techniques.
Finding Blind Spots in Evaluator LLMs with Interpretable Checklists
Jun 19, 2024Large Language Models (LLMs) are increasingly relied upon to evaluate text outputs of other LLMs, thereby influencing leaderboards and development decisions. However, concerns persist over the accuracy of these assessments and the potential for misleading conclusions. In this work, we investigate the effectiveness of LLMs as evaluators for text generation tasks. We propose FBI, a novel framework designed to examine the proficiency of Evaluator LLMs in assessing four critical abilities in other LLMs: factual accuracy, instruction following, coherence in long-form writing, and reasoning proficiency. By introducing targeted perturbations in answers generated by LLMs, that clearly impact one of these key capabilities, we test whether an Evaluator LLM can detect these quality drops. By creating a total of 2400 perturbed answers covering 22 perturbation categories, we conduct a comprehensive study using different evaluation strategies on five prominent LLMs commonly used as evaluators in the literature. Our findings reveal significant shortcomings in current Evaluator LLMs, which failed to identify quality drops in over 50\% of cases on average. Single-answer and pairwise evaluations demonstrated notable limitations, whereas reference-based evaluations showed comparatively better performance. These results underscore the unreliable nature of current Evaluator LLMs and advocate for cautious implementation in practical applications. Code and data are available at https://github.com/AI4Bharat/FBI.
IndicLLMSuite: A Blueprint for Creating Pre-training and Fine-Tuning Datasets for Indian Languages
Mar 11, 2024Despite the considerable advancements in English LLMs, the progress in building comparable models for other languages has been hindered due to the scarcity of tailored resources. Our work aims to bridge this divide by introducing an expansive suite of resources specifically designed for the development of Indic LLMs, covering 22 languages, containing a total of 251B tokens and 74.8M instruction-response pairs. Recognizing the importance of both data quality and quantity, our approach combines highly curated manually verified data, unverified yet valuable data, and synthetic data. We build a clean, open-source pipeline for curating pre-training data from diverse sources, including websites, PDFs, and videos, incorporating best practices for crawling, cleaning, flagging, and deduplication. For instruction-fine tuning, we amalgamate existing Indic datasets, translate/transliterate English datasets into Indian languages, and utilize LLaMa2 and Mixtral models to create conversations grounded in articles from Indian Wikipedia and Wikihow. Additionally, we address toxicity alignment by generating toxic prompts for multiple scenarios and then generate non-toxic responses by feeding these toxic prompts to an aligned LLaMa2 model. We hope that the datasets, tools, and resources released as a part of this work will not only propel the research and development of Indic LLMs but also establish an open-source blueprint for extending such efforts to other languages. The data and other artifacts created as part of this work are released with permissive licenses.
User Embedding Model for Personalized Language Prompting
Jan 10, 2024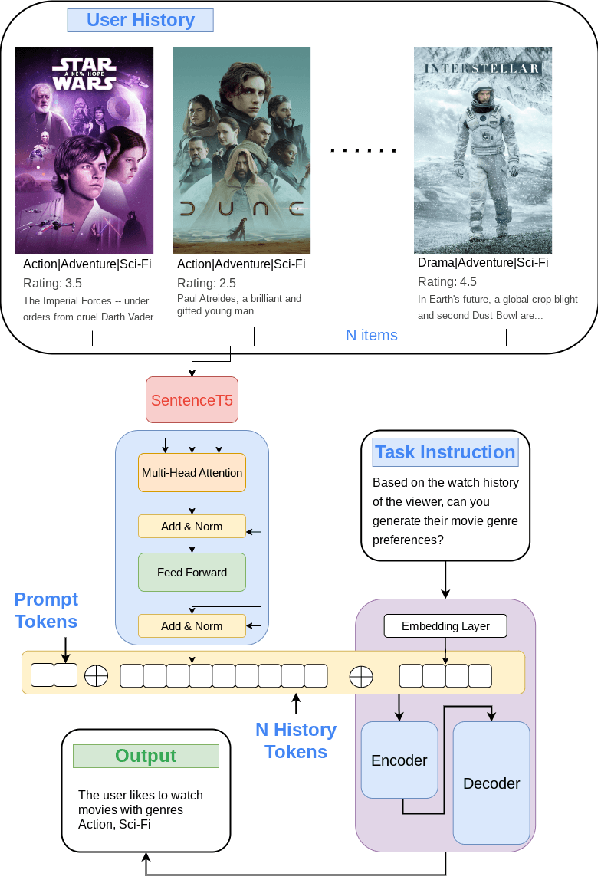

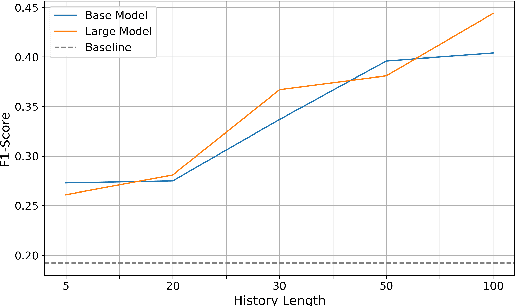

Modeling long histories plays a pivotal role in enhancing recommendation systems, allowing to capture user's evolving preferences, resulting in more precise and personalized recommendations. In this study we tackle the challenges of modeling long user histories for preference understanding in natural language. Specifically, we introduce a new User Embedding Module (UEM) that efficiently processes user history in free-form text by compressing and representing them as embeddings, to use them as soft prompts to a LM. Our experiments demonstrate the superior capability of this approach in handling significantly longer histories compared to conventional text based prompting methods, yielding substantial improvements in predictive performance. The main contribution of this research is to demonstrate the ability to bias language models with user signals represented as embeddings.
IndicTrans2: Towards High-Quality and Accessible Machine Translation Models for all 22 Scheduled Indian Languages
May 25, 2023India has a rich linguistic landscape with languages from 4 major language families spoken by over a billion people. 22 of these languages are listed in the Constitution of India (referred to as scheduled languages) are the focus of this work. Given the linguistic diversity, high-quality and accessible Machine Translation (MT) systems are essential in a country like India. Prior to this work, there was (i) no parallel training data spanning all the 22 languages, (ii) no robust benchmarks covering all these languages and containing content relevant to India, and (iii) no existing translation models which support all the 22 scheduled languages of India. In this work, we aim to address this gap by focusing on the missing pieces required for enabling wide, easy, and open access to good machine translation systems for all 22 scheduled Indian languages. We identify four key areas of improvement: curating and creating larger training datasets, creating diverse and high-quality benchmarks, training multilingual models, and releasing models with open access. Our first contribution is the release of the Bharat Parallel Corpus Collection (BPCC), the largest publicly available parallel corpora for Indic languages. BPCC contains a total of 230M bitext pairs, of which a total of 126M were newly added, including 644K manually translated sentence pairs created as part of this work. Our second contribution is the release of the first n-way parallel benchmark covering all 22 Indian languages, featuring diverse domains, Indian-origin content, and source-original test sets. Next, we present IndicTrans2, the first model to support all 22 languages, surpassing existing models on multiple existing and new benchmarks created as a part of this work. Lastly, to promote accessibility and collaboration, we release our models and associated data with permissive licenses at https://github.com/ai4bharat/IndicTrans2.
A Comprehensive Analysis of Adapter Efficiency
May 12, 2023Adapters have been positioned as a parameter-efficient fine-tuning (PEFT) approach, whereby a minimal number of parameters are added to the model and fine-tuned. However, adapters have not been sufficiently analyzed to understand if PEFT translates to benefits in training/deployment efficiency and maintainability/extensibility. Through extensive experiments on many adapters, tasks, and languages in supervised and cross-lingual zero-shot settings, we clearly show that for Natural Language Understanding (NLU) tasks, the parameter efficiency in adapters does not translate to efficiency gains compared to full fine-tuning of models. More precisely, adapters are relatively expensive to train and have slightly higher deployment latency. Furthermore, the maintainability/extensibility benefits of adapters can be achieved with simpler approaches like multi-task training via full fine-tuning, which also provide relatively faster training times. We, therefore, recommend that for moderately sized models for NLU tasks, practitioners should rely on full fine-tuning or multi-task training rather than using adapters. Our code is available at https://github.com/AI4Bharat/adapter-efficiency.
Vārta: A Large-Scale Headline-Generation Dataset for Indic Languages
May 10, 2023
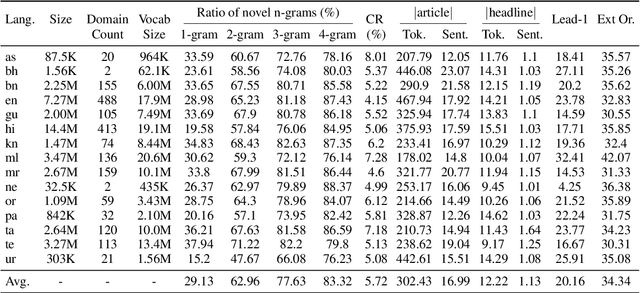
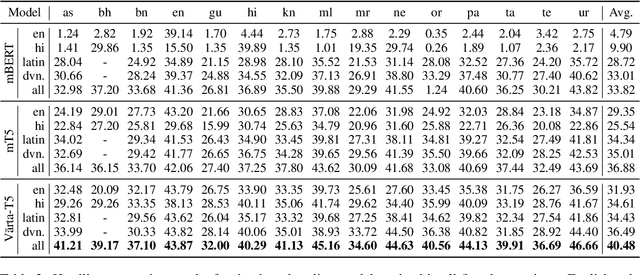

We present V\=arta, a large-scale multilingual dataset for headline generation in Indic languages. This dataset includes 41.8 million news articles in 14 different Indic languages (and English), which come from a variety of high-quality sources. To the best of our knowledge, this is the largest collection of curated articles for Indic languages currently available. We use the data collected in a series of experiments to answer important questions related to Indic NLP and multilinguality research in general. We show that the dataset is challenging even for state-of-the-art abstractive models and that they perform only slightly better than extractive baselines. Owing to its size, we also show that the dataset can be used to pretrain strong language models that outperform competitive baselines in both NLU and NLG benchmarks.
Naamapadam: A Large-Scale Named Entity Annotated Data for Indic Languages
Dec 20, 2022



We present, Naamapadam, the largest publicly available Named Entity Recognition (NER) dataset for the 11 major Indian languages from two language families. In each language, it contains more than 400k sentences annotated with a total of at least 100k entities from three standard entity categories (Person, Location and Organization) for 9 out of the 11 languages. The training dataset has been automatically created from the Samanantar parallel corpus by projecting automatically tagged entities from an English sentence to the corresponding Indian language sentence. We also create manually annotated testsets for 8 languages containing approximately 1000 sentences per language. We demonstrate the utility of the obtained dataset on existing testsets and the Naamapadam-test data for 8 Indic languages. We also release IndicNER, a multilingual mBERT model fine-tuned on the Naamapadam training set. IndicNER achieves the best F1 on the Naamapadam-test set compared to an mBERT model fine-tuned on existing datasets. IndicNER achieves an F1 score of more than 80 for 7 out of 11 Indic languages. The dataset and models are available under open-source licenses at https://ai4bharat.iitm.ac.in/naamapadam.
IndicXTREME: A Multi-Task Benchmark For Evaluating Indic Languages
Dec 13, 2022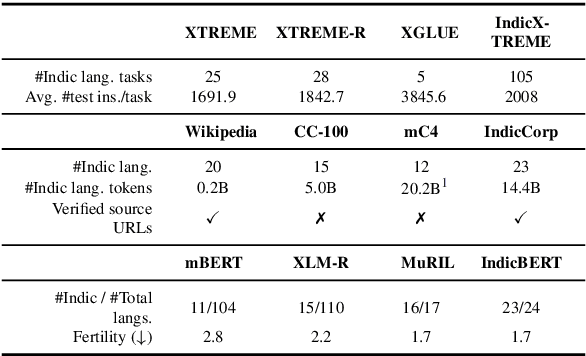
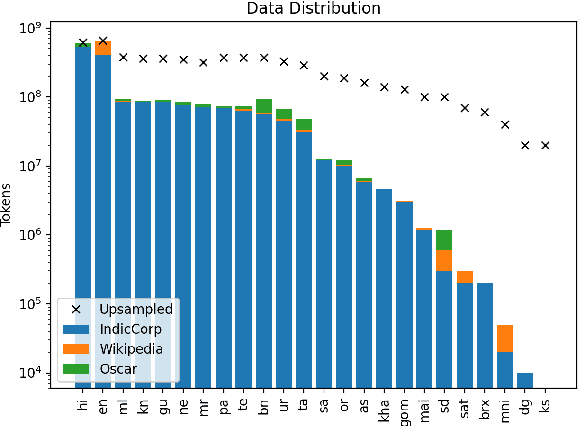
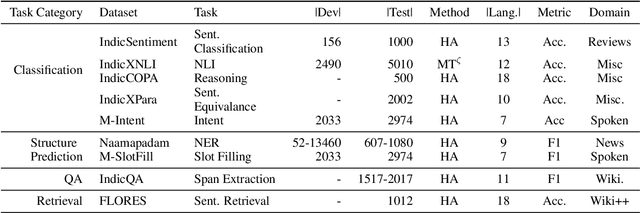
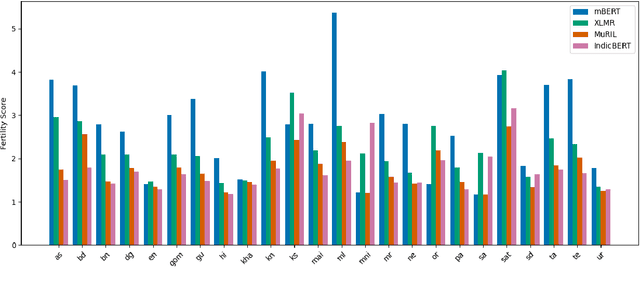
In this work, we introduce IndicXTREME, a benchmark consisting of nine diverse tasks covering 18 languages from the Indic sub-continent belonging to four different families. Across languages and tasks, IndicXTREME contains a total of 103 evaluation sets, of which 51 are new contributions to the literature. To maintain high quality, we only use human annotators to curate or translate our datasets. To the best of our knowledge, this is the first effort toward creating a standard benchmark for Indic languages that aims to test the zero-shot capabilities of pretrained language models. We also release IndicCorp v2, an updated and much larger version of IndicCorp that contains 20.9 billion tokens in 24 languages. We pretrain IndicBERT v2 on IndicCorp v2 and evaluate it on IndicXTREME to show that it outperforms existing multilingual language models such as XLM-R and MuRIL.